













近200+自動駕駛數據集全面調研!一覽如何數據閉環全流程
寫在前面&個人理解
自動駕駛技術在硬件和深度學習方法的最新進展中迅速發展,并展現出令人期待的性能。高質量的數據集對于開發可靠的自動駕駛算法至關重要。先前的數據集調研試圖回顧這些數據集,但要么集中在有限數量的數據集上,要么缺乏對數據集特征的詳細調查。為此,這里從多個角度對超過200個自動駕駛數據集進行了詳盡的研究,包括傳感器模態、數據大小、任務和上下文條件。引入了一種新的評估每個數據集影響的度量標準,該標準還可以成為建立新數據集的指南。進一步分析了數據集的標注過程和質量。此外,對幾個重要數據集的數據分布進行了深入分析。最后,討論未來自動駕駛數據集的發展趨勢。
當前行業的概述
自動駕駛(AD)旨在通過創建能夠準確感知環境、做出智能決策并在沒有人類干預的情況下安全行駛的車輛,徹底改變交通系統。由于令人激動的技術發展,各種自動駕駛產品已在多個領域實施,例如無人出租車。這些對自動駕駛的快速進展在很大程度上依賴于大量的數據集,這些數據集幫助自動駕駛系統在復雜的駕駛環境中變得穩健可靠。
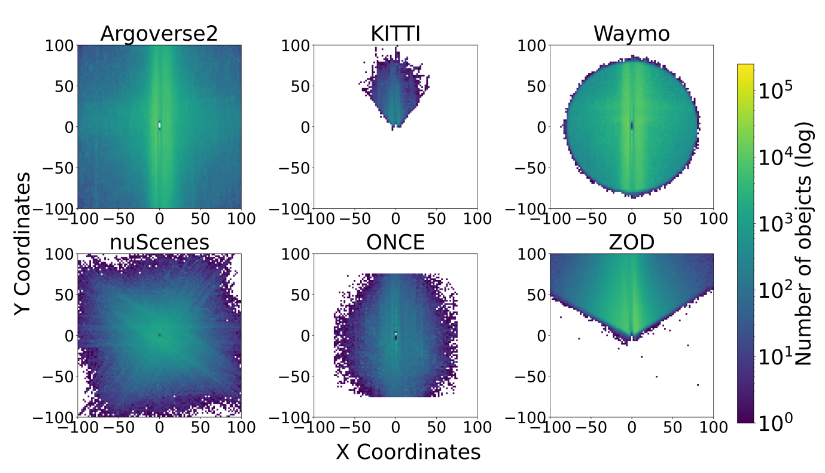
近年來,自動駕駛數據集的質量和種類顯著增加。數據集開發的第一個顯著現象是各種不同的數據收集策略,包括通過仿真器生成的合成數據集和從真實世界記錄的數據集等。其次,數據集在組成方面也各種各樣,包括但不限于多種感知數據(如相機圖像和LiDAR點云)以及用于自動駕駛各個任務的不同標注類型。下圖1以俯視圖的方式顯示了六個真實世界數據集(Argoverse 2 、KITTI 、nuScenes 、ONCE 、Waymo 和ZOD )的3D目標邊界框分布的統計數據,展示了每個數據集的獨特標注特性。
根據傳感器的設備位置,數據集的多樣性還體現在感知領域中,包括車載、V2X、無人機等。此外,幾何多樣性和天氣條件的改變提高了自動駕駛數據集的泛化能力。
為什么研究?動機是什么?
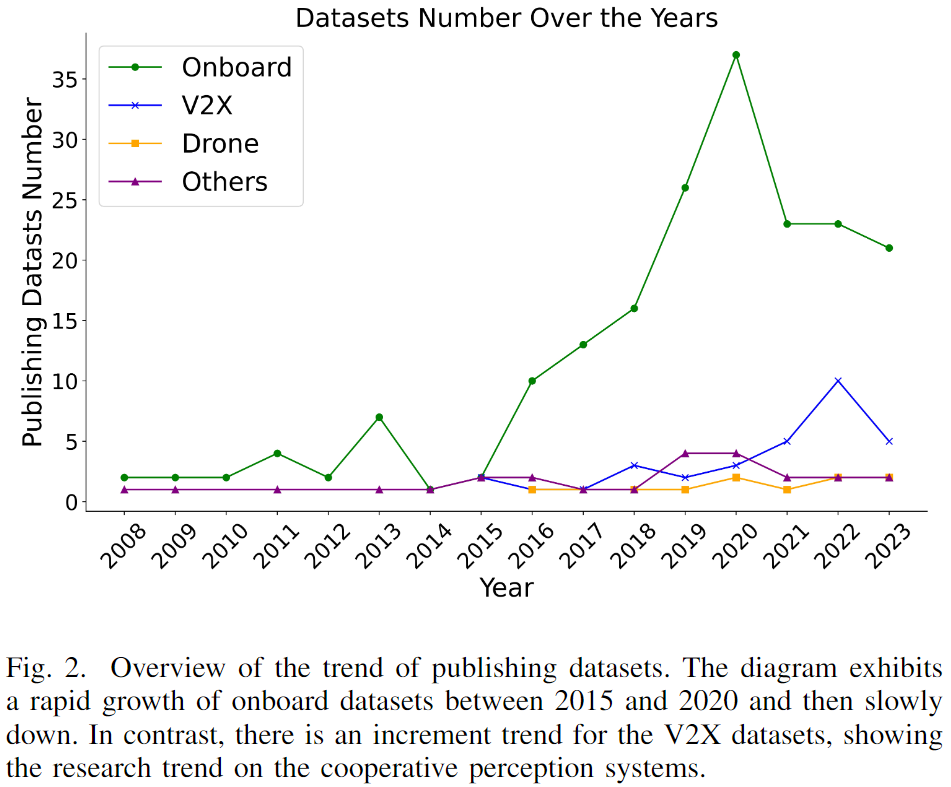
下圖2中展示了每年發布的感知數據集數量,以從一個角度反映自動駕駛數據集的趨勢。由于存在大量且不斷增加的公開發布的數據集,對自動駕駛數據集進行全面調查對推動學術和工業研究非常有價值。在先前的工作中,Yin等人總結了27個在公共道路上收集的數據的公開可用數據集。[35]除了描述現有數據集,討論了合成數據和真實數據之間的域適應以及自動標注方法。[36]總結了現有數據集,并對下一代數據集的特征進行了詳盡的分析。然而,這些調查僅總結了少量數據集,導致范圍不夠廣泛。AD-Dataset 收集了大量數據集,但缺乏對這些數據集屬性的詳細分析。與對所有類型的數據集進行研究相比,一些研究人員對特定類型的自動駕駛數據集進行了調查,例如異常檢測、合成數據集、3D語義分割和決策。
因此,本文的目標是提出一項全面而系統的研究,涵蓋自動駕駛中的大量數據集,從感知到控制的所有任務,考慮真實世界和合成數據,并深入了解若干關鍵數據集的數據模態和質量。在下表I中對比了其他數據集調查和作者的調查。

主要貢獻
本文的主要貢獻可總結如下:
- 對自動駕駛數據集進行了全面調查。盡可能全面地考慮公開可用數據集,記錄它們的基本特征,如發布年份、數據大小、傳感器模態、感知領域、幾何和環境條件以及支持任務。據我們所知,本工作提供了迄今為止記錄的最廣泛的自動駕駛數據集概述。
- 系統地說明了收集自動駕駛數據的傳感器和感知領域。此外,描述了自動駕駛的主要任務,包括任務目標、所需數據模態和評估指標。
- 根據感知領域和支持任務對數據集進行了總結和劃分,以幫助研究人員高效選擇和收集目標數據集的信息。從而促進更有針對性和有效的研究和開發工作。
- 此外,引入了一個影響分數度量標準,評估了在社區中發布的感知數據集的影響力。這個指標也可以作為未來數據集開發的指導。深入分析了具有最高分數的數據集,突出它們的優勢和效用。
- 調查了數據集的標注質量以及各種自動駕駛任務的現有標注程序。
- 進行了詳細的數據統計,展示了不同角度的各種數據集的數據分布,展示了它們固有的限制和適用情況。
- 分析了最近的技術趨勢,并展示了下一代數據集的發展方向。還展望了大語言模型進一步推動未來自動駕駛的潛在影響。
范圍與局限性
本文的目標是對現有的自動駕駛數據集進行詳盡調查,以提供對該領域未來算法和數據集的開發提供幫助和指導。收集了側重于四個基本自動駕駛任務的數據集:感知、預測、規劃和控制。由于有幾個多功能數據集支持多個任務,作者只在它們主要支持的主要范圍中解釋它們,以避免重復介紹。此外,收集了大量數據集,并以它們的主要特征展示在表格中。然而,對所有收集到的數據集進行詳細解釋可能無法突顯最受歡迎的數據集,可能會妨礙研究人員通過這項調查找到有價值的數據集。因此,只詳細描述了最有影響力的數據集。
文章結構
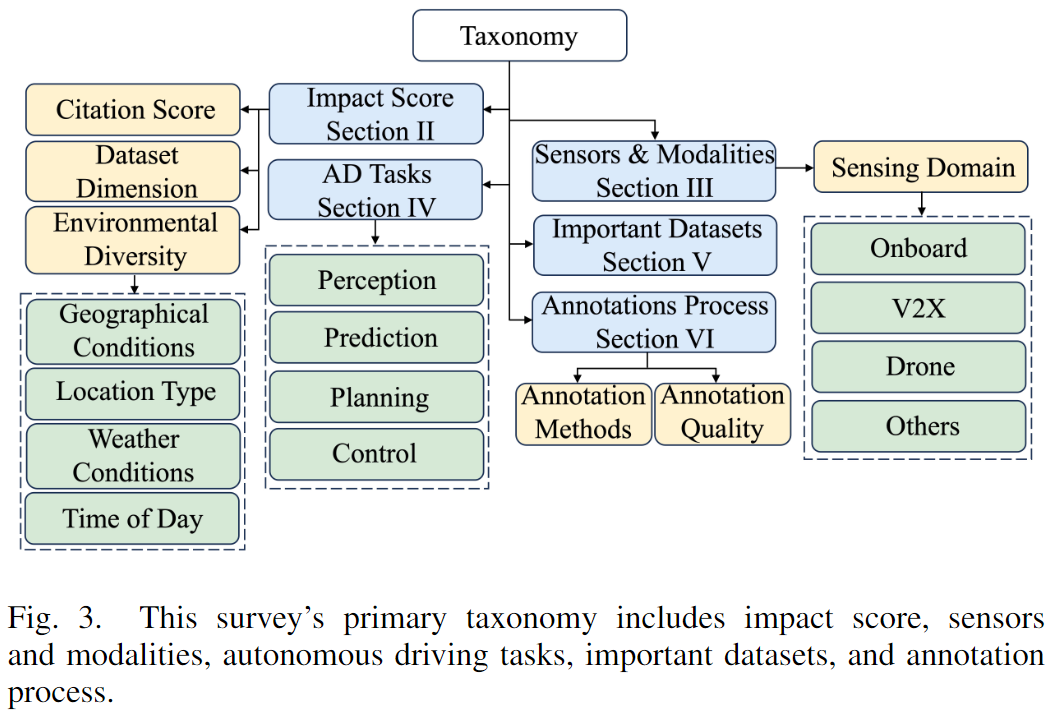
本文的其余部分結構如下:第二節介紹了用于獲取公共數據集以及數據集的評估指標的方法。第三節展示了自動駕駛中使用的主要傳感器及其模態。第四節討論了自動駕駛任務、相關挑戰和所需數據。在第五節進一步討論了幾個重要的數據集。在第六節展示了標注過程和影響標注質量的因素。此外,在第七節對幾個數據集的數據分布進行了統計。在第八節中,調查了自動駕駛數據集的發展趨勢和未來工作。最后,在第九節總結。此調查的分類結構如下圖3所示。
方法論介紹
本節包括1) 如何收集和篩選數據集(II-A),以及2) 如何評估數據集對自動駕駛領域的影響(II-B)。
數據集收集
作者遵循[42]的方法進行系統性的回顧,以詳盡收集已發布的自動駕駛數據集。為確保來源的多樣性,作者利用了知名的搜索引擎,如Google、Google Scholar和Baidu來搜索數據集。為了確保從各個國家和地區全面收集數據集,使用英語、中文和德語進行搜索,使用關鍵詞如“autonomous driving datasets”、“intelligent vehicle datasets”以及與目標檢測、分類、跟蹤、分割、預測、規劃和控制相關的術語。
此外,在IEEE Xplore和自動駕駛及智能交通系統領域的相關會議中搜索,以收集來自期刊和會議論文集的數據集。通過關鍵詞搜索和手動標題審查驗證了這些來源的數據集。
最后,為了確保包括專業或較少知名的數據集,作者通過Github倉庫和Paperwithcodes進行了搜索。類似于數據庫,對數據集進行了手動和基于關鍵詞的搜索。
數據集評估指標
作者引入了一個新的度量標準,即影響分數(impact score),用于評估已發布數據集的重要性,這也可以作為準備新數據集的指南。在本節中,詳細解釋了計算自動駕駛數據集影響分數的方法。
為了進行公平和可比較的比較,作者僅考慮與感知領域相關的數據集,因為感知領域占據了自動駕駛數據集的很大一部分。此外,為了確保評分系統的客觀性和可理解性,考慮了各種因素,包括引用次數、數據維度和環境多樣性。所有的值都是從官方論文或開源數據集網站收集而來。
引用分數。首先,作者從總引用次數和平均年引用次數計算引用分數。為了獲得公平的引用計數,選擇數據集的最早版本的時間作為其發布時間。此外,為了確保比較基于一致的時間框架,所有引用次數都是截至2023年9月20日收集的。總引用次數 反映了數據集的總體影響力。這個指標的較高數值意味著數據集得到了廣泛的認可和研究人員的使用。然而,較早發布的數據集可能積累更多的引用。為了解決這種不公平,作者利用平均年引用次數,它描述了數據集的年引用增速。計算函數如下公式1所示。
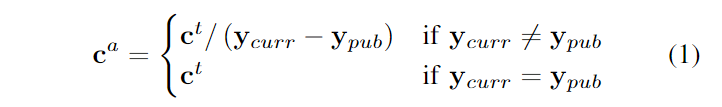
其中 和 分別表示當前年份和數據集發布年份。另一方面,引用次數 distastes 的范圍很廣,從幾位數到幾萬位數不等。為了緩解極端的不平衡并突顯每個數據集之間的差異,作者對 和 都進行了對數變換,然后進行 Min-Max 歸一化,如公式2所示。

最終,引用分數 是和的總和:
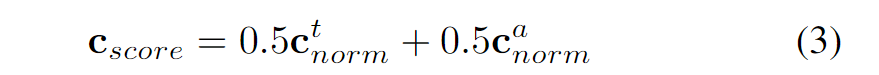
數據維度評分。 從四個角度測量數據維度:數據集大小、時間信息、任務數量和標注類別。數據集大小 f 由數據集的幀數表示,反映了其容量和全面性。為了獲得數據集大小評分 ,采用與引用分數相同的方法處理幀數,以克服不同數據集之間的極端不平衡。
時間信息對于自動駕駛至關重要,因為它使車輛能夠了解周圍環境隨時間的變化。作者使用 t ∈{0, 1} 表示數據集是否包含時間信息。關于任務數量,作者只考慮與自動駕駛感知領域中的六個基本任務相關的數據集,例如 2D 目標檢測、3D 目標檢測、2D 語義分割、3D 語義分割、跟蹤和車道線檢測。因此,任務數量評分被記錄為 。類別的數量對于數據集的穩健性和多功能性至關重要。在統計過程中,如果一個數據集支持多個任務并包含各種類型的標注,作者選擇類別數量最多的數據。然后,將這些類別分為五個級別,l = {1, 2, 3, 4, 5},基于五分位數。在后續過程之前,作者對 和 l 進行了規范化,以簡化計算。
為了盡可能客觀地反映數據維度評分 ,作者給四個組成部分分配了不同的權重,如下公式4所示。
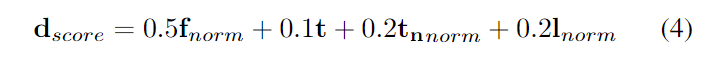
環境多樣性評分。根據以下因素評估數據集的環境多樣性:
- 天氣條件,例如雨雪。
- 白天或黃昏等數據收集時間。
- 駕駛場景的類型,例如城市或鄉村。
- 幾何范圍指的是數據記錄的國家或城市數量。
值得注意的是,作者將合成數據集的幾何范圍視為缺失。按照論文對數據進行分類的粒度來量化多樣性。此外,對于缺失值,如果數據集宣布數據是在多樣化條件下記錄的,作者使用中值作為缺失值。否則,將此屬性的缺失值設為1。作者將每個因素量化為五個不同級別,然后環境多樣性評分 是這四個因素的總和。
最后,利用公式5計算影響分數 。
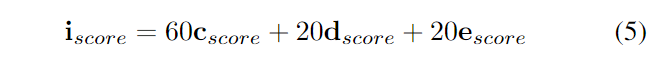
總影響分數為100,其中60%屬于引用分數 ,數據維度分數 和環境多樣性分數 占40%。
數據源和自動駕駛中的協同感知
本節介紹主要用于自動駕駛的傳感器及其模態。此外,分析了數據采集和通信領域,如車載、無人機和V2X的協同感知。
數據的傳感器和模態
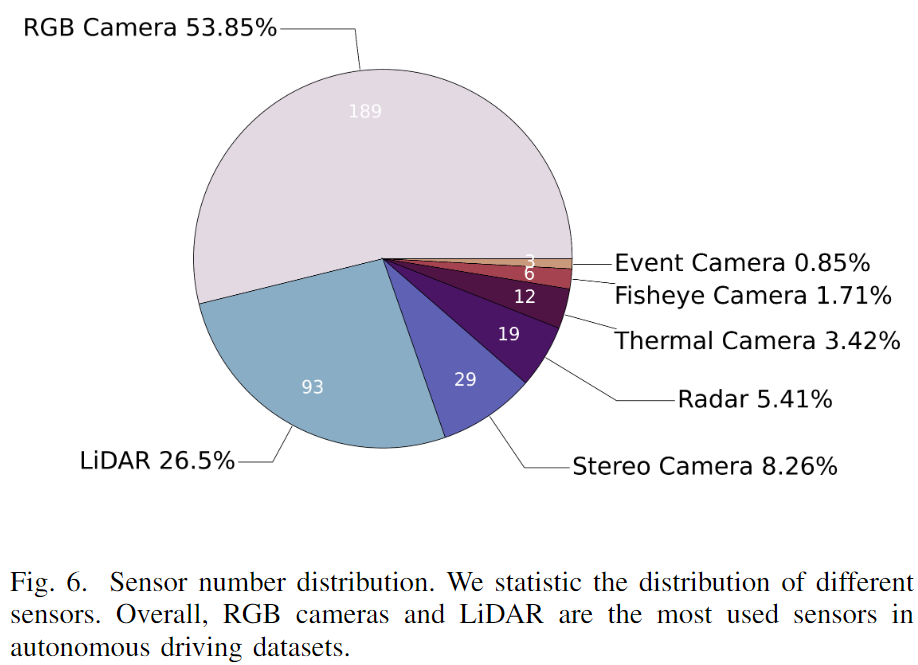
高效而準確地從周圍環境中收集數據是自動駕駛可靠感知系統的關鍵。為了實現這一目標,在自動駕駛車輛和基礎設施上使用了各種類型的傳感器。傳感器的示例如下圖 4 所示。最常用的傳感器是相機、LiDAR 和Radar。事件型和熱成像相機也安裝在車輛或道路旁邊,以進一步提高感知能力。

RGB 圖像。RGB 圖像通常由單目、雙目或魚眼相機記錄。單目相機提供不帶深度的 2D 視圖;雙目相機通過其雙鏡頭提供深度感知;魚眼相機使用廣角鏡頭捕捉廣闊的視野。所有這些相機通過透鏡將光傳導到圖像傳感器(例如 CMOS),將這些光轉換為表示圖像的電子信號。如下圖 5 (a) 所示,2D 圖像捕捉環境的顏色信息、豐富的紋理、模式和視覺細節。由于這些特性,RGB 圖像主要用于檢測車輛和行人,并識別道路標志。然而,RGB 圖像容易受到低照明、雨、霧或耀斑等條件的影響 。
LiDAR 點云。LiDAR 使用激光束測量傳感器與目標之間的距離,從而創建 3D 環境表示 。LiDAR 點云(如下圖 5 (b) 所示)提供高分辨率的精確空間信息,可以檢測長距離內的目標。然而,這些點的密度會隨著距離的增加而減小,導致遠處目標的表示更為稀疏。天氣條件,如霧,也會限制 LiDAR 的性能。總體而言,LiDAR 適用于需要 3D 簡要信息的情況。
Radar點云。Radar通過發射射頻波并分析其反射來檢測目標、距離和相對速度。此外,Radar在各種天氣條件下都具有很強的魯棒性 。然而,Radar點云通常比 LiDAR 數據更粗糙,缺乏目標的詳細形狀或紋理信息。因此,Radar通常用于輔助其他傳感器。下圖 5 (c) 展示了Radar點云。
事件相機。事件型相機異步捕捉數據,僅在像素檢測到亮度變化時才激活。捕捉到的數據稱為事件(如圖 5 (d) 所示)。由于采用了特定的數據生成方法,記錄的數據具有極高的時間分辨率,并且可以捕捉快速運動而不模糊 。
熱成像相機的紅外圖像。熱成像相機(見下圖 5 (e))通過捕捉紅外輻射來檢測熱特征 。由于基于溫差生成圖像,熱成像相機可以在完全黑暗中工作,并且不受霧或煙影響。然而,熱成像相機無法分辨顏色或詳細的視覺圖案。此外,與光學相機相比,紅外圖像的分辨率較低。

慣性測量單元(IMU)。IMU 是一種電子設備,用于測量并報告目標的特定力、角速度,有時還有目標周圍的磁場 。在自動駕駛中,它用于跟蹤車輛的運動和方向。雖然 IMU 不包含周圍環境的視覺信息,但通過將 IMU 的數據與其他傳感器的數據融合,感知系統可以更準確、更魯棒地跟蹤車輛的運動和方向。
作者從收集的數據集中分析傳感器的分布,如下圖 6 所示。超過一半的傳感器是單目相機(53.85%),這是因為它們價格低廉且性能可靠。此外,93 個數據集包含 LiDAR 數據,由于其高分辨率和精確的空間信息而受到重視。然而,由于高昂的成本,限制了 LiDAR 的廣泛使用。除 LiDAR 點云外,29 個數據集利用雙目相機捕捉深度信息。此外,分別包含Radar、熱像相機和魚眼相機的數據集比例分別為5.41%、3.42%和1.71%。考慮到以事件為基礎的相機捕捉動態場景的時間效率,有三個數據集生成基于事件的相機數據。
傳感域和協同感知系統
自動駕駛系統中,自車與周圍環境中其他實體之間的感知數據和通信起著至關重要的作用,確保了自動駕駛系統的安全性、效率性和整體功能性。因此,傳感器的位置決定了可以收集的數據的質量、角度和范圍,因此非常關鍵。總體而言,在自動駕駛環境中,傳感器可以分為以下幾個領域:自車、車聯網(V2X)、無人機和其他。
自車:自車傳感器直接安裝在自動駕駛車輛上,通常包括相機、LiDAR、Radar和慣性測量單元(IMU)。這些傳感器提供了車輛視角的直接視圖,即時反饋車輛周圍的情況。然而,由于車輛檢測范圍的限制,自車傳感器可能在提供盲點內障礙物的預警或檢測急彎附近的危險方面存在局限性。
車聯網(V2X):車聯網包括車輛與交通系統中的任何其他組件之間的通信,包括車輛對車輛(V2V)、車輛對基礎設施(V2I)和車輛對網絡(V2N)(如下圖7所示)。除了直接的感知輸入外,協同系統確保多個實體協同工作。
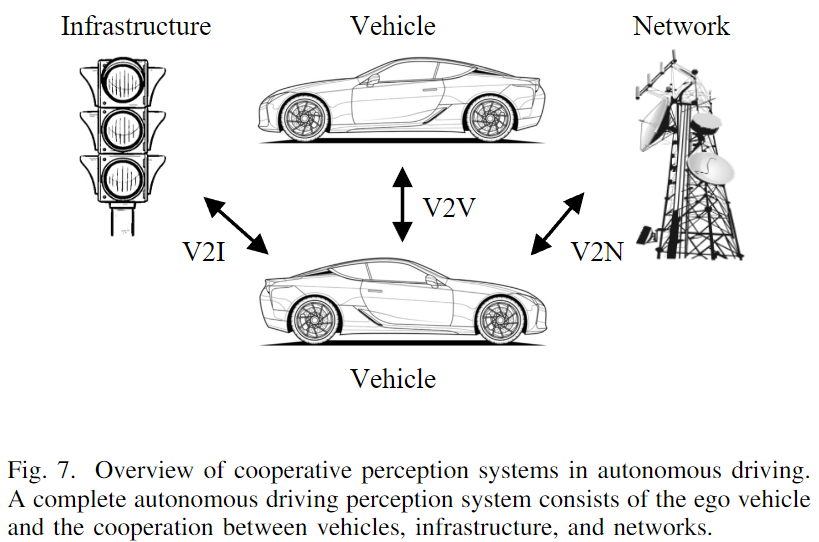
- 車到車(V2V) V2V使附近的車輛能夠共享數據,包括它們的位置、速度和傳感器數據,如相機圖像或LiDAR掃描,有助于更全面地了解駕駛場景。
- 車到基礎設施(V2I) V2I促進了自動駕駛車輛與基礎設施組件之間的通信,例如交通燈、標志或路邊傳感器。嵌入在道路基礎設施中的傳感器,包括相機、LiDAR、Radar或基于事件的相機,協同工作以擴展感知范圍并提高自動駕駛車輛的情境感知。在這項調查中,作者將通過基礎設施或V2I進行的感知都歸類為V2I。
- 車到網絡(V2N) V2N指的是在車輛和更廣泛的網絡基礎設施之間交換信息,通常利用蜂窩網絡為車輛提供對云數據的訪問。V2N通過共享跨區域數據或提供有關交通擁堵或道路封閉的實時更新,幫助V2V和V2I的合作感知。
無人機(Drone):無人機提供了一種空中視角,提供了軌跡預測和路徑規劃所需的數據。例如,來自無人機的實時數據可以集成到交通管理系統中,以優化交通流并提醒自動駕駛車輛前方的事故。
其他 未由前三種類型收集的數據被定義為其他,例如安裝在非車輛目標上或多個領域的其他設備。
自動駕駛中的任務
這一部分深入介紹了自動駕駛中的關鍵任務,如感知和定位、預測以及規劃和控制。自動駕駛流程的概覽如下圖8所示。詳細說明它們的目標、它們所依賴的數據的性質以及固有的挑戰。圖9展示了自動駕駛中若干主要任務的示例。
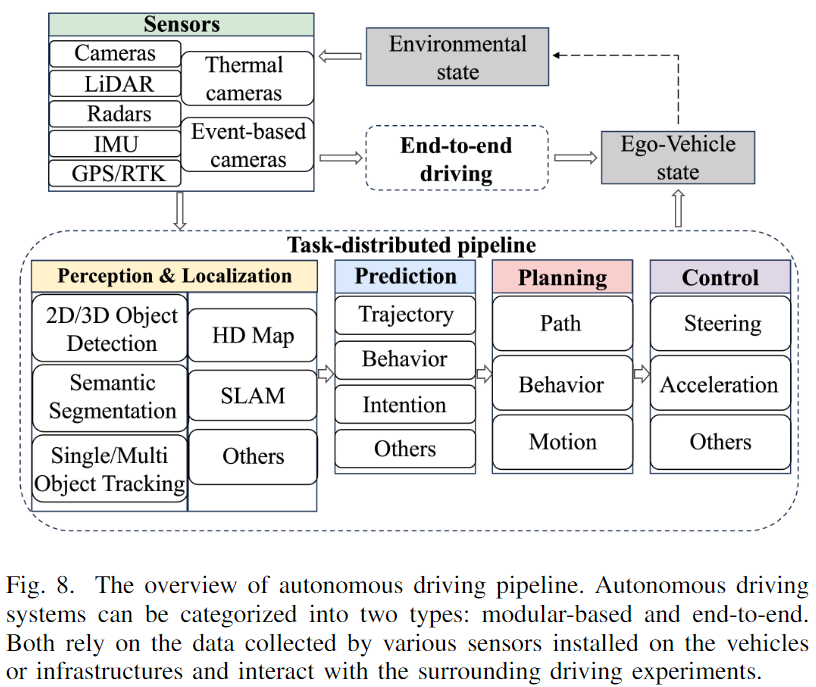
感知和定位
感知側重于根據感知數據理解環境,而定位確定自動駕駛車輛在該環境中的位置。
2D/3D 目標檢測
2D或3D目標檢測旨在識別和分類駕駛環境中的其他實體。而2D目標檢測在圖像空間中識別目標,3D目標檢測進一步整合由LiDAR提供的精確深度信息。盡管檢測技術取得了顯著進展,但仍存在一些挑戰,如目標遮擋、光照變化和多樣的目標外觀。
通常情況下,使用AP度量來評估目標檢測性能。根據[1],AP度量可表述為:
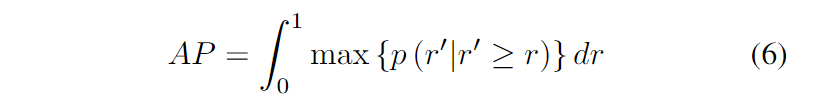
其中p(r)是精度-召回曲線。
2D/3D 語義分割
語義分割涉及將圖像的每個像素或點云的每個點分類到其語義類別。從數據集的角度來看,保持細粒度的目標邊界并管理大量標簽要求對這個任務來說是一個重要的挑戰。
正如中提到的,用于分割的主要度量標準包括平均像素準確率(mPA):

還有mIoU:

其中k*∈N是類別數,和和分別表示真正例、假正例和假反例。
目標跟蹤
目標跟蹤監控單個或多個目標隨時間的軌跡。這項任務需要時間序列的RGB數據、LiDAR或Radar序列。通常,目標跟蹤包括單目標跟蹤或多目標跟蹤(MOT)。
多目標跟蹤準確度(MOTA)是用于多目標跟蹤的廣泛使用的度量,它結合了假反例、假正例和不匹配率(參見方程9):

其中,、和分別是隨時間t的假正例、假反例和不匹配錯誤的數量。是真值。
此外,與其考慮單一閾值不同,Average MOTA(AMOTA)是基于所有目標置信閾值計算的。
高精度地圖
高精度地圖的目標是構建詳細、高度準確的表示,其中包括有關道路結構、交通標志和地標的信息。一個數據集應該提供LiDAR數據以獲取精確的空間信息,以及相機數據以獲取視覺細節,以確保建立的地圖準確性。
根據,高精度地圖自動化和高精度地圖變更檢測越來越受到關注。通常,高精度地圖的質量是通過準確度度量來估算的。
SLAM
同時定位與建圖(SLAM)涉及構建周圍環境的同時建圖,并在該地圖中定位車輛。因此,來自相機、用于位置跟蹤的IMUs以及實時LiDAR點云的數據是至關重要的。引入了兩個評估指標,相對位姿誤差(RPE)和絕對軌跡誤差(ATE),用于評估從輸入RGB-D圖像估計的軌跡的質量。
預測
預測是指對周圍agents的未來狀態或行為進行預測。這種能力確保在動態環境中更安全地導航。預測使用了一些評估指標,例如均方根誤差(RMSE):
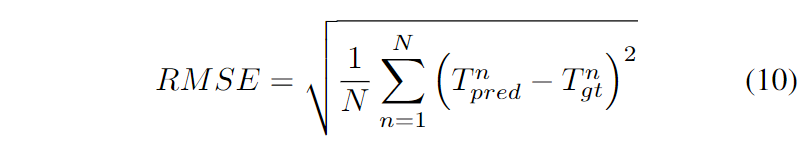
其中N是樣本的總數,和分別表示預測軌跡和真值軌跡。
負對數似然(NLL)(見方程11)是另一個重點關注軌跡正確性的度量,可用于比較不同模型的不確定性。
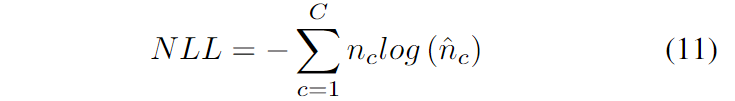
其中C是總類數,是預測的正確性的二進制指示器,是相應的預測概率。
軌跡預測
利用來自相機和LiDAR等傳感器的時間序列數據,軌跡預測涉及預測其他實體(如行人、騎車人或其他車輛)未來的路徑或移動模式。
行為預測
行為預測預測其他道路使用者的潛在動作,例如車輛是否會變道。訓練行為預測模型依賴于具有廣泛標注的數據,因為在不同情境中實體可能采取各種潛在動作。
意圖預測
意圖預測側重于推斷目標行為背后的意圖的高級目標,涉及對人類目標的物理或心理活動進行更深層次的語義理解。由于任務的復雜性,它不僅需要來自感知相機等傳感器的數據,還需要其他信息,如交通信號和手勢,以推斷其他agents的意圖。
規劃與控制
- 規劃: 規劃代表對感知環境和預測做出反應的決策過程。經典的三級分層規劃框架包括路徑規劃、行為規劃和運動規劃。
- 路徑規劃: 路徑規劃,也稱為路線規劃,涉及設定長期目標。這是一個高層次的過程,確定到達目的地的最佳路徑。
- 行為規劃: 行為規劃位于框架的中層,與決策制定相關,包括變道、超車、合并和十字路口穿越等。這個過程依賴于對其他agents行為的正確理解和交互。
- 運動規劃: 運動規劃處理車輛實時應該遵循的實際軌跡,考慮到障礙物、道路狀況和其他道路agents的預測行為。與路徑規劃相反,運動規劃生成實現局部目標的適當路徑。
- 控制: 自動駕駛中的控制機制管理自動駕駛汽車如何執行來自運動規劃系統的決定的路徑或行為,并糾正跟蹤誤差。它將高級命令轉換為可執行的油門、剎車和轉向命令。
端到端自動駕駛
端到端自動駕駛是指單個深度學習模型處理從感知到控制的所有任務,繞過傳統的模塊化流程。這樣的模型通常更具適應性,因為它們通過學習來調整整個模型。它們的固有優勢在于簡單性和效率,通過減少手工制作組件的需求。然而,實施端到端模型面臨著關鍵限制,如大量的訓練數據需求、低解釋性和不靈活的模塊調整。
對端到端自動駕駛進行大規模基準測試可以分為閉環和開環評估。閉環評估基于仿真環境,而開環評估涉及根據來自真實世界數據集的專業駕駛行為評估系統的性能。
高影響力數據集
本節描述了在感知、預測、規劃和控制領域中的具有里程碑意義的自動駕駛數據集。還展示了端到端自動駕駛的數據集。
感知數據集
感知數據集對于開發和優化自動駕駛系統至關重要。它們通過提供豐富的多模態感知數據,確保對周圍環境進行有效感知和理解,從而增強車輛的可靠性和穩健性。
作者利用提出的數據集評估指標計算收集的感知數據集的影響分數,隨后根據這些分數選擇前50個數據集,以創建一個按時間順序排列的概述,如下圖10所示。同時,如前章節中所述,將數據集分為車載、V2X、無人機和其他,從每個類別中選擇一個子集,編制一個包含50個數據集的綜合表格(下表II)。值得注意的是,表中的數據集是按照其各自類別內的影響分數進行排序的,不代表總體的前50。在以下部分,作者選擇了每個感知來源中影響分數最高的幾個數據集,并考慮它們的發布年份。



車載
- KITTI: KITTI 自2012年發布以來,深刻影響了自動駕駛領域。KITTI包含通過各種傳感器記錄的各種真實駕駛場景,包括相機、LiDAR和GPS/IMU。其豐富的標注和高分辨率的傳感器數據促進了在各種自動駕駛任務(如目標檢測、跟蹤、光流、深度估計和視覺里程計)方面的算法開發和基準測試。
- Cityscapes: Cityscapes 包括在復雜城市環境中明確捕獲的大量圖像。通過精心標注,Cityscapes為30個不同的目標類別提供像素級分割,其中包括各種車輛類型、行人、道路和交通標志信息。由于其復雜性和豐富性,Cityscapes已成為諸如城市場景中語義分割等任務的標準基準。
- SYNTHIA: SYNTHIA 是自動駕駛領域的合成數據集。該數據集包含13,400張圖像,具有語義分割的逐像素標注。SYNTHIA的一個顯著特點是它能夠彌合現實世界和合成數據之間的差距,促進了在不同領域之間開發穩健且可轉移的方法。
- Virtual KITTI: Virtual KITTI 通過虛擬環境密切模仿了原始KITTI數據集,通過提供包含各種交通情況和環境條件的高分辨率視頻序列而脫穎而出。類似于,Virtual KITTI支持關鍵的自動駕駛任務,包括目標檢測、語義分割和目標跟蹤。
- VIPER: VIPER 是從現實虛擬世界的駕駛、騎行和步行視角收集的合成數據集,解決了數據稀缺和標注現實世界數據的高成本挑戰。VIPER包含超過25萬幀視頻,為低級和高級視覺任務提供了真值數據,同時涵蓋各種天氣條件、光照場景和復雜的城市風景。總體而言,VIPER為研究人員提供了一個寶貴且經濟高效的工具,以加速可靠且安全的自動駕駛的發展。
- Apolloscapes:Apolloscapes 提供了超過140,000個高分辨率幀,具有準確的邊界框和像素級語義標簽,對于訓練和驗證自動車輛的感知和導航系統至關重要。Apolloscapes支持圖像和點云的語義分割,2D/3D目標檢測,多目標跟蹤和車道線分割,從而實現先進且安全的自動駕駛系統的創建和評估。
- SemanticKITTI:SemanticKITTI 是KITTI家族的一個顯著擴展,專注于自動駕駛領域的語義分割。SemanticKITTI包含超過43,000個LiDAR點云幀,使其成為戶外環境中3D語義分割最大的數據集之一。SemanticKITTI為28個類別提供精確的標簽,如汽車、道路、建筑等,為評估點云語義分割方法的性能提供了強有力的基準,支撐了相關領域的許多研究和創新。
- nuScenes:nuScenes 是自動駕駛領域的重要貢獻,提供了一個豐富的數據庫,滿足感知系統的多樣化需求。nuScenes利用LiDAR、Radar和相機記錄來自波士頓和新加坡不同城市場景的數據。值得一提的是,其六個相機提供了對周圍環境的全面視角,在多視角目標檢測任務中得到廣泛應用。總體而言,nuScenes數據集是發展自動駕駛技術的基石,支持多任務和應用,并在該領域設立了新的基準。
- Waymo:Waymo Open Dataset ,于2019年推出,通過提供大量的多模態感知數據和高質量標注,顯著影響了自動駕駛研究和進展。Waymo數據集的關鍵貢獻包括其對駕駛條件和地理位置的全面覆蓋,這對于不同任務(如檢測、跟蹤和分割)的魯棒性和通用性至關重要。
- BDD100K:BDD100K 數據集,由伯克利DeepDrive中心于2018年發布,是一個規模龐大且多樣化的駕駛數據集,以其規模和多樣性而聞名。它包括100,000個大約40秒的視頻。同時,它為目標檢測、跟蹤、語義分割和車道線檢測提供了各種標注標簽。這個龐大的數據集推動了自動駕駛社區的進展,成為研究人員和工程師提出和改進算法的具有挑戰性和多功能的平臺。
- RADIATE:RADIATE 是第一個公開的Radar數據集,包含44,140幀在不同惡劣天氣條件下收集的帶標注的圖像,如雨天、霧天、陰天和雪天。它還整合了LiDAR和相機數據,使駕駛環境的全面感知和理解成為可能。
- Argoverse 2:Argoverse 2 作為Argoverse 1 的續集,引入了更多樣化和復雜的駕駛場景,展示了迄今為止最大的自動駕駛分類法。它捕捉了六個城市和不同條件下的各種實際駕駛場景。Argoverse 2支持多個重要任務,包括但不限于3D目標檢測、語義分割和跟蹤。總之,Argoverse 2數據集提供了大量真實駕駛場景的多模態數據,促進了算法的創新和進步,并展示了其在自動駕駛中作為重要資源的實質潛力。
V2X
- V2VNet:V2VNet 引入的數據集專注于利用V2V通信,允許自動車輛從多個視點共享信息,這對于檢測被遮擋目標和預測其他交通參與者的行為至關重要。該數據集使用名為Lidarsim 的高保真LiDAR仿真器創建,該仿真器利用真實世界數據生成各種交通場景的逼真LiDAR點云。總的來說,這項工作引起了對V2V作為提高自動車輛能力的有前途的途徑的關注。
- DAIR-V2X:DAIR-V2X 是在車輛基礎設施協同自動駕駛領域的開創性資源,提供大規模、多模態、多視圖的真實世界數據。該數據集旨在解決車輛和基礎設施傳感器之間的時間不同步以及此類協作系統中涉及的數據傳輸成本等挑戰。DAIR-V2X數據集對自動駕駛的影響很大,因為它為車輛基礎設施合作的復雜性設立了一個基準,多虧了其來自真實世界的多種場景。
- Rope3D:Rope3D 是感知系統的重要貢獻,通過利用從路邊相機收集的數據,填補了自動駕駛中的關鍵差距。Rope3D包括50,000張圖像,處于不同的環境條件,包括不同的照明(白天、夜晚、黃昏)和天氣情況(雨天、晴天、多云)。總體而言,Rope3D數據集是推動路邊感知在自動駕駛中取得進展的先導工作,同時也是研究人員和工程師開發更健壯、智能的自動駕駛系統的重要工具。
- V2V4Real:V2V4Real 是第一個大規模的真實世界數據集,用于處理V2V合作感知。該數據集從兩輛配備有多模態傳感器(如LiDAR和相機)的車輛中收集。V2V4Real關注一系列感知任務,如合作3D目標檢測、合作3D目標跟蹤和Sim2Real域適應。這種多功能性使其成為開發和基準測試自動駕駛算法的寶貴資源。
無人機
- UAVDT:UAVDT 數據集包含80,000個準確標注的幀,其中包括14種屬性,如天氣條件、飛行姿態、相機視圖、車輛類別和遮擋級別。該數據集專注于在城市環境中基于UAV的目標檢測和跟蹤。此外,UAVDT基準測試包括密集場景、小型目標和顯著的相機運動,這對于當前最先進的方法來說都是具有挑戰性的。
- DroneVehicle:DroneVehicle 提出了一個大規模的基于無人機的數據集,提供28,439個RGB-紅外圖像對,用于解決低照明條件下的目標檢測問題。此外,它涵蓋了各種場景,如城市道路、住宅區和停車場。由于其在廣泛條件下的獨特無人機視角,這個數據集是發展自動駕駛技術的重要一步。
其它
- Pascal3D+:Pascal3D+ 是PASCAL VOC 2022 的擴展,通過為圖像提供更豐富和多樣化的標注來克服以前數據集的局限性。Pascal3D+通過為12個剛性目標類別(如汽車、公共汽車、自行車)提供3D姿勢標注,并從ImageNet 添加更多圖像,實現了高度的可變性。
- TT 100K:清華大學-騰訊100K 解決了在現實駕駛條件下檢測和分類交通標志的挑戰。它提供了100,000張圖像,包括30,000個交通標志實例。除了大規模的數據大小外,高分辨率的圖像涵蓋了各種照明和天氣條件,使其對于交通標志識別的訓練和驗證具有魯棒性。
- Mapillary Vistas :由于2017年提出,主要旨在對街景進行語義分割。該數據集包含25,000張圖像,標有66個目標類別,并包括37個類別的實例特定標注。它包含來自不同天氣、時間和幾何位置的圖像,有助于減輕對特定區域或條件的偏見。
預測、規劃和控制數據集
預測、規劃和控制數據集是促進訓練和評估駕駛系統的基礎,用于預測交通動態、行人移動和其他影響駕駛決策的重要因素。通過仿真各種駕駛場景,它們使自動駕駛車輛能夠做出明智的決策,穿越復雜的環境,并在道路上保持安全和高效。因此,作者根據數據大小、模態和引用數量詳細展示與這些任務相關的幾個高影響力的數據集。將預測、規劃和控制數據集總結為任務特定和多任務兩組。
任務特定數據集:
- highD。基于無人機的highD 數據集提供了德國高速公路上自然車輛軌跡的大規模收集,包含110,000輛汽車和卡車的后處理軌跡。該數據集旨在克服現有基于場景的安全驗證測量方法的局限性,這些方法通常無法捕捉道路用戶的自然行為或包含具有足夠質量的所有相關數據。
- PIE。由提出的行人意圖估計(PIE)數據集在理解城市環境中的行人行為方面取得了重大進展。它包含在多倫多市中心記錄的超過6小時的行車錄像,涵蓋了各種光照條件。PIE數據集提供了對感知和視覺推理的豐富標注,包括帶有遮擋標志的邊界框、過街意圖置信度以及行人行為的文本標簽。長時間的連續序列和標注有助于多個任務,如軌跡預測和行人意圖預測。
- USyd。USyd 在沒有交通信號燈的城市交叉口背景下推動了駕駛員意圖預測的進展,這在城市設置中很常見,由于缺乏明確的道路規則和信號,構成了一項挑戰。該數據集包括超過23,000輛車穿越五個不同的交叉口的數據,使用車載LiDAR跟蹤系統收集。數據模態包括詳盡無遺的提供了橫向和縱向坐標、航向和速度的車輛軌跡。這些信息對于預測駕駛行為至關重要,考慮到人類駕駛模式中固有的不確定性。
- Argoverse。Argoverse 是3D目標跟蹤和運動預測中的一個關鍵數據集。Argoverse提供了來自7個相機、前視雙目圖像和LiDAR點云的360°圖像。記錄的數據涵蓋了來自290km映射車道線的300,000多條車輛軌跡。借助豐富的傳感器數據和語義地圖,Argoverse對于推動預測系統的研究和開發至關重要。
- inD。inD 的重要性在于它大規模、高質量且多樣化的軌跡數據,對于道路用戶預測模型和城市交叉口環境中自動車輛的基于場景的安全驗證至關重要。它涵蓋了大約11,500條不同的道路用戶軌跡,例如車輛、自行車和行人。這些軌跡的定位誤差小于0.1米,對于數據的可靠性至關重要。
- PePscenes。PePscenes 解決了在動態駕駛環境中理解和預測行人動作的需求。該數據集通過添加每幀2D/3D邊界框和行為標注,重點關注行人過馬路行為,增強了nuScenes 數據集。的一個關鍵屬性是結合各種數據類型,包括語義地圖、場景圖像、軌跡和自車狀態,這對于創建能夠理解復雜交通場景的強大模型至關重要。
- openDD。openDD 數據集專注于分析和預測環狀交叉口周圍的交通場景,這些場景復雜且不受交通信號燈約束。它是在使用高分辨率(4K)的無人機捕獲的圖像的基礎上創建的,跨足了來自501次單獨飛行的62小時軌跡數據。該數據集不僅包含軌跡,還包括描述道路拓撲結構的shapefiles和可擴展標注語言(XML)文件,以及每個底層交叉口的參考圖像。
- nuPlan。nuPlan 是自動駕駛中世界上第一個閉環機器學習規劃基準。這個多模態數據集包括來自美國和亞洲四個城市的約1,500小時的人類駕駛數據,展示了不同的交通模式,如合并、變道、與騎自行車和行人的互動以及在施工區駕駛。nuPlan數據集的這些特征考慮了實際駕駛的動態和互動性質,使其更適合進行更真實的評估。
- exiD。 exiD 軌跡數據集是2022年提出的,對高度交互的高速公路場景具有重要意義。它利用無人機記錄交通情況,減少對交通的影響,并確保高數據質量和效率。這個基于無人機的數據集在捕捉各種交互中的多樣性方面超過了先前的數據集,特別是涉及高速入口和出口的車道線變更。
- MONA。Munich Motion Dataset of Natural Driving (MONA) 是一個龐大的數據集,包含來自130小時視頻的702,000條軌跡,覆蓋了具有多個車道線的城市道路、市區高速公路以及它們的過渡。這個數據集展示了0.51米的平均整體位置精度,展示了使用高度精確的定位和LiDAR傳感器收集數據的質量。
多任務數據集:
- INTERACTION。 INTERACTION 數據集涵蓋了多樣、復雜和關鍵的駕駛場景,結合了全面的語義地圖,使其成為一個多功能平臺,可用于多種任務,如運動預測、模仿學習以及決策和規劃的驗證。它包括不同國家的數據,進一步提高了對不同文化駕駛行為進行分析的魯棒性,這對全球自動駕駛的發展至關重要。
- BLVD。 BLVD 基準有助于動態4D(3D+時間)跟蹤、5D(4D+交互)交互事件識別和意圖預測等任務,這些對于更深入理解交通場景至關重要。BLVD提供了來自不同交通場景的約120,000幀,包括目標密度(低和高)和照明條件(白天和夜晚)。這些幀被完全標注,包括大量的3D標簽,涵蓋了車輛、行人和騎手。
- rounD。由提出的rounD數據集對于場景分類、道路用戶行為預測和駕駛員建模至關重要,因為它收集了在環狀交叉口的大量道路用戶軌跡。該數據集利用裝備有4K分辨率相機的無人機收集了超過六小時的視頻,記錄了超過13,000名道路用戶。廣泛記錄的交通情況和高質量的錄像使rounD成為自動駕駛中不可或缺的數據集,促進了對公共交通中自然駕駛行為的研究。
- Lyft Level 5。Lyft Level 5 是迄今為止最大規模的用于運動預測的自動駕駛數據集之一,擁有超過1,000小時的數據。它包括17,000個25秒長的場景,一個具有超過15,000個人工標注的高清語義地圖,8,500個車道線段和該區域的高分辨率航拍圖像。它支持多個任務,如運動預測、運動規劃和仿真。詳細標注的眾多多模態數據使Lyft Level 5數據集成為預測和規劃的重要基準。
- LOKI。LOKI 代表著長期和關鍵意圖(Long Term and Key Intentions),是多agents軌跡預測和意圖預測中的一個重要數據集。LOKI通過提供大規模、多樣化的數據,包括行人和車輛在內,彌補了智能和安全關鍵系統的一個關鍵空白。該數據集通過利用帶有相應LiDAR點云的相機圖像,提供了交通場景的多維視圖,使其成為社區中非常靈活的資源。
- SceNDD。SceNDD 引入了真實駕駛場景,展示了多樣的軌跡和駕駛行為,可用于開發高效的運動規劃和路徑跟蹤算法。它還適用于自動駕駛汽車不同配置,并包含可以分解為時間戳進行詳細分析的預測時間視角。總的來說,SceNDD數據集是自動駕駛預測和規劃研究的重要補充。
- DeepAccident。 合成數據集DeepAccident 是第一個為自動駕駛汽車提供直接且可解釋的安全評估指標的工作。這個包含57,000個帶標注幀和285,000個帶標注樣本的大規模數據集支持端到端的運動和事故預測,對于提高自動駕駛系統在避免碰撞和確保安全方面的預測能力至關重要。此外,這個多模態數據集對于各種基于V2X的感知任務,如3D目標檢測、跟蹤和鳥瞰(BEV)語義分割,都是多才多藝的。
- Talk2BEV。創新的數據集Talk2BEV 推動了從傳統的自動駕駛任務轉向在自動駕駛背景下將大型視覺語言模型與BEV地圖相結合的趨勢。Talk2BEV利用了視覺語言模型的最新進展,允許對道路場景進行更靈活、全面的理解。該數據集包含超過20,000個多樣的問題類別,全部由人工標注,并源自。所提出的Talk2BEV-Bench基準可用于多項任務,包括決策制定、視覺和空間推理以及意圖預測。
- V2X-Seq(預測)。軌跡預測數據集是現實世界數據集V2X-Seq 的重要組成部分,包含約80,000個基礎設施視圖和80,000個車輛視圖場景,以及額外的50,000個協同視圖場景。這種感知領域的多樣性為研究和分析車輛基礎設施協同(VIC)軌跡預測提供了更全面的視角。
端到端數據集
端到端已經成為自動駕駛中的一個趨勢,作為模塊化架構的替代。一些多功能數據集(如nuScenes 和Waymo )或仿真器(如CARLA )提供了開發端到端自動駕駛的機會。同時,一些工作提出了專門用于端到端駕駛的數據集。
- DDD17。 DDD17 數據集因其使用事件型相機而顯著,該相機提供標準主動像素傳感器(APS)圖像和動態視覺傳感器(DVS)時間對比事件的同時流,提供了視覺數據的獨特組合。此外,DDD17捕捉了包括高速公路和城市駕駛在內的各種駕駛場景,以及不同的天氣條件,為訓練和測試端到端自動駕駛算法提供詳盡而現實的數據。
在本調查中總結的其他數據集顯示在表IV、表V、表VI中。

標注過程
自動駕駛算法的成功和可靠性不僅依賴于大量的數據,還依賴于高質量的標注。本節首先解釋了標注數據的方法。此外分析了確保標注質量的最重要方面。
標注是如何創建的
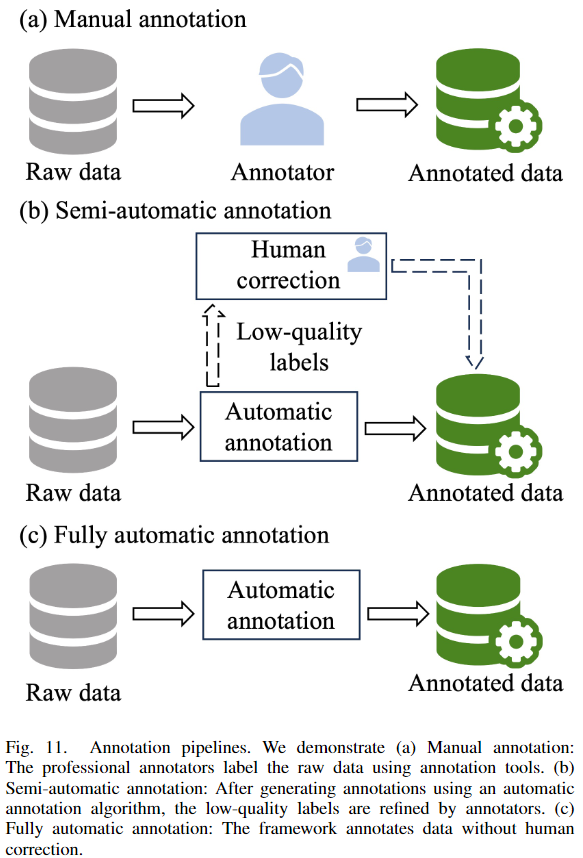
不同的自動駕駛任務需要特定類型的標注。例如,目標檢測需要實例的邊界框標簽,分割基于像素或點級別的標注,對于軌跡預測來說,標注連續的軌跡至關重要。另一方面,如下圖11所示,標注流程可以分為三種類型:手動標注、半自動標注和全自動標注。在本節詳細說明了不同類型標注的標注方法。
標注分割數據。標注分割數據的目標是為圖像中的每個像素或LiDAR幀中的每個點分配一個標簽,以指示它屬于哪個目標或區域。在標注之后,屬于同一目標的所有像素都用相同的類別進行標注。對于手動標注過程,標注者首先在目標周圍畫出邊界,然后填充區域或直接涂抹像素。然而,以這種方式生成像素/點級別標注是昂貴且低效的。
許多研究提出了全自動或半自動的標注方法以提高標注效率。提出了一種基于弱監督學習的完全自動標注方法,用于分割圖像中提出的可行駛路徑。[265]是一種半自動標注方法,利用目標先驗生成分割mask。之后,[266]提出了一種考慮20個類別的半自動方法。Polygon-RNN++ 提出了一種交互式分割標注工具,遵循[268]的思路。[269]不使用圖像信息生成像素級標簽,而是將3D信息轉移到2D圖像領域生成語義分割標注。對于標注3D數據,[270]提出了一個圖像輔助標注流程。[271]利用主動學習選擇少量點并形成最小訓練集,以避免標注整個點云場景。[272]引入了一種使用半/弱監督學習進行標注的高效標注框架,以標注室外點云。
標注2D/3D邊界框。邊界框標注的質量直接影響了自動駕駛車輛感知系統(如目標檢測)在現實場景中的有效性和魯棒性。標注過程通常涉及使用矩形框標注圖像或使用長方體標注點云,以精確包圍感興趣的目標。
Labelme 是一種專注于為目標檢測標注圖像的工具。然而,由專業標注者生成邊界框面臨與手動分割標注相同的問題。Wang等人 提出了一種基于開源視頻標注系統VATIC的半自動視頻標注工具。[275]是另一種用于自動駕駛場景的視頻標注工具。與白天標注相比,處理夜間的邊界框標注更具挑戰性。[276]介紹了一種利用軌跡的半自動方法來解決這個問題。
與2D標注相比,3D邊界框包含了更豐富的空間信息,如準確的位置、目標的寬度、長度、高度以及空間中的方向。因此,標注高質量的3D標注需要一個更復雜的框架。Meng等人 應用了一個兩階段的弱監督學習框架,使用人為循環來標注LiDAR點云。ViT-WSS3D 通過對LiDAR點和相應弱標簽之間的全局交互建模來生成偽邊界框。Apolloscape 采用了類似于的標注流程,包括3D標注和2D標注兩個分支,分別處理靜態背景/目標和移動目標。3D BAT 開發了一個標注工具箱,以輔助在半自動標注中獲取2D和3D標簽。
標注軌跡。軌跡本質上是一系列點,映射了目標隨時間的路徑,反映了空間和時間信息。為自動駕駛標注軌跡數據的過程涉及對駕駛環境中各種實體的路徑或運動模式進行標注,如車輛、行人和騎車者。通常,標注過程依賴于目標檢測和跟蹤的結果。
在軌跡標注的先前工作中,[280]在線生成了用于演習的動作,并被標注到軌跡中。[281]包括一個眾包步驟,后跟一個專家集成的精確過程。[282]開發了一個主動學習框架來標注駕駛軌跡。精確地預測行人的運動模式對于駕駛安全至關重要。Styles等人 引入了一種可擴展的機器標注方案,用于無需人工努力的行人軌跡標注。
在合成數據上進行標注。由于在真實世界數據上進行手動標注的費時昂貴,通過計算機圖形和仿真器生成的合成數據提供了解決這個問題的替代方法。由于數據生成過程是可控的,場景中每個目標的屬性(如位置、大小和運動)都是已知的,因此可以自動且準確地標注合成數據。
生成的合成場景被設計成模仿真實世界的條件,包括多個目標、各種地貌、天氣條件和光照變化。為了實現這個目標,一些研究人員利用了《俠盜獵車手5》(GTA5)游戲引擎構建了數據集 。[284]基于多個游戲構建了一個實時系統,用于生成各種自動駕駛任務的標注。SHIFT 、CAOS 和V2XSet 是基于CARLA 仿真器創建的,而不是應用游戲視頻。與[11]相比,V2X-Sim 研究了使用多個仿真器 ,為V2X感知任務生成數據集。CODD 進一步利用生成用于合作駕駛的3D LiDAR點云。其他工作利用Unity開發平臺 生成合成數據集。
標注的質量
現有基于監督學習的自動駕駛算法依賴于大量的標注數據。然而,在質量低的標注上進行訓練可能會對自動駕駛車輛的安全性和可靠性產生負面影響。因此,確保標注的質量對于提高在復雜的現實環境中行駛時的準確性是至關重要的。根據研究,標注質量受到多個因素的影響,例如一致性、正確性、精度和驗證。一致性是評估標注質量的首要標準。它涉及在整個數據集上保持一致性,對于避免在訓練在這些數據上的模型時產生混淆至關重要。例如,如果特定類型的車輛被標注為汽車,那么在所有其他情況下,它應該被一致地進行相同的標注。標注精度是另一個重要的指標,它指的是標簽是否與目標或場景的實際狀態相匹配。相比之下,正確性強調標注的數據是否適用于數據集的目的和標注準則。在標注之后,驗證標注數據的準確性和完整性是至關重要的。這個過程可以通過專家或算法的手動審查來完成。驗證有助于在問題影響自動駕駛車輛性能之前有效地防止數據集中的問題,從而減少潛在的安全風險。[288]提出了一種面向數據的驗證方法,適用于專家標注的數據集。
KITTI 的一個標注失敗案例如下圖12所示。在相應的圖像和LiDAR點云中說明了真值邊界框(藍色)。在圖像的左側,汽車的標注(用紅色圈出)不準確,因為它未包含整個汽車目標。此外,盡管相機和LiDAR清晰捕捉到兩輛汽車(綠色長方體突出顯示),但它們未被標注。

數據分析
這一部分將詳細系統地從不同角度分析數據集,例如全球數據的分布,時間趨勢,以及數據分布。
全球分布
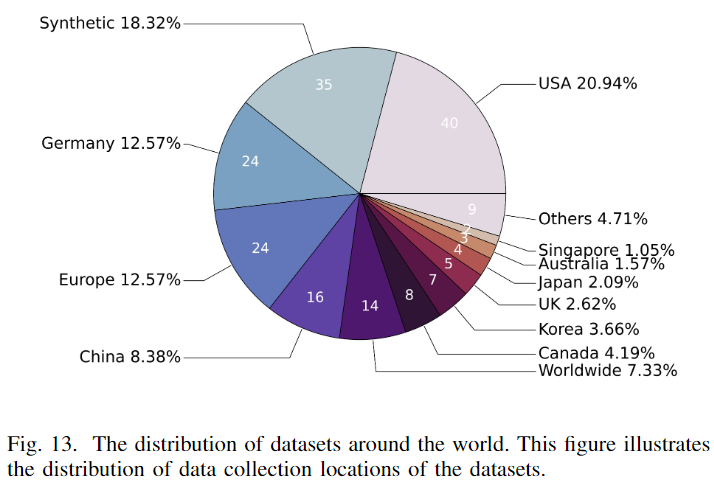
在圖13中展示了191個自動駕駛數據集的全球分布概況。該圖表顯示美國處于領先地位,擁有40個數據集(占比21%),突顯了其在自動駕駛領域的領導地位。德國擁有24個數據集,反映了其強大的汽車工業和對自動駕駛技術推動的影響。中國緊隨其后,擁有16個數據集,表明中國在這一領域的興趣和投資。另一個值得注意的點是,全球范圍內有11個數據集,歐洲地區(不包括德國)有24個數據集。這種多樣化的區域分布增強了收集到的數據的穩健性,并突顯了研究界和工業界的國際合作和努力。
另一方面,盡管較小的部分代表了包括加拿大、韓國、英國、日本和新加坡在內的其他國家,這些國家都是擁有堅實技術背景和積累的發達國家——這一統計數據反映了極端的地區偏見。美國、西歐和東亞的主導地位導致了自動駕駛系統在這些地區典型的環境條件下過度擬合的偏見。這種偏見可能導致自動駕駛車輛在各種或未知的地區和情況下無法正常運行。因此,引入來自更廣泛國家和地區的數據,如非洲,可以促進自動駕駛車輛的全面發展。
此外,由CARLA 等仿真器生成的35個合成數據集占18.32%。由于實際駕駛環境錄制的局限性,這些合成數據集克服了這些缺點,對于開發更強大和可靠的駕駛系統至關重要。
感知數據集的時間趨勢
在圖10中,作者介紹了從2007年到2023年(截至本文撰寫時)具有前50影響分數的感知數據集的時間趨勢概覽。這些數據集根據它們的數據來源領域進行了顏色編碼,并且合成數據集用紅色外框標注,清晰地展示了朝著多樣化數據收集策略的進展。一個明顯的趨勢顯示了多年來數據集的數量和種類的增加,表明隨著自動駕駛領域的不斷發展,需要高質量數據集。
總體而言,由于自動駕駛汽車有效而準確地感知周圍環境的能力的重要性,大多數數據集提供了來自裝備在自車上的傳感器的感知視角(車載)。另一方面,由于實際世界數據成本高昂,一些研究人員提出了高影響力的合成數據集,如VirtualKITTI (2016年),以減輕對實際數據的依賴。在仿真器的有效性的推動下,近年來發布了許多新穎的合成數據集。在時間線上,像DAIR-V2X (2021年)這樣的V2X數據集也呈現出向合作駕駛系統的趨勢。此外,由于無人機提供的非遮擋視角,基于無人機的數據集,如2018年發布的UAVDT ,在推動感知系統方面發揮著關鍵作用。
數據分布
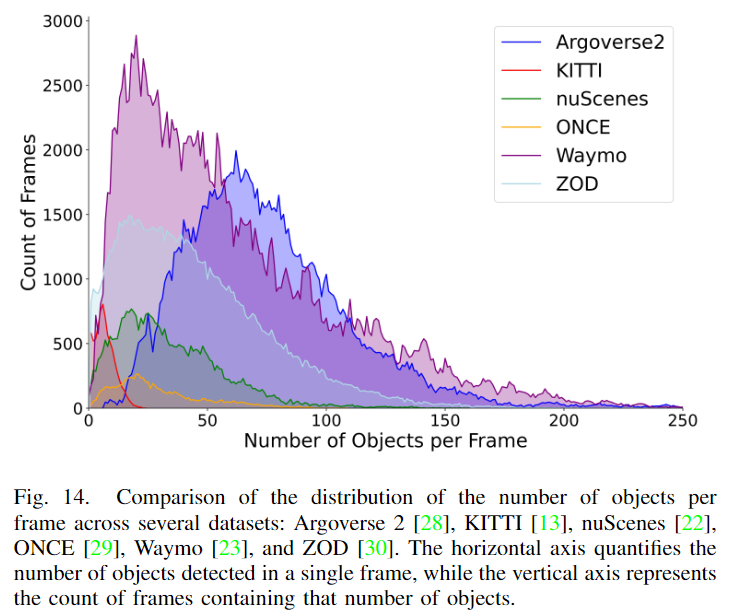
在圖14中介紹了這些數據集每幀目標數量的情況。值得注意的是,Waymo 展示了大量幀數少于50個目標的情況,同時在圖表中占據了廣泛的位置,說明了它在每幀中從低到高的目標密度涵蓋了各種場景。相反,KITTI 展示了一個更為受限的分布和有限的數據規模。Argoverse 2 具有大量幀數的高目標計數,其峰值約為70,這表明了它在一般情況下復雜的環境表示。對于 ONCE ,其目標密度均勻地分布在支持的感知范圍內。像 nuScenes 和 ZOD 這樣的數據集展示了類似的曲線,快速上升然后緩慢下降,暗示了環境復雜性的適度水平,每幀中目標數量具有相當的可變性。
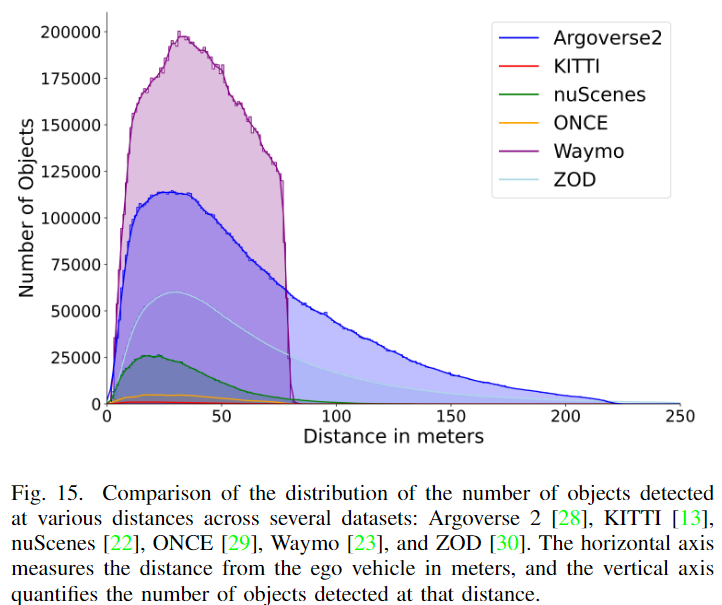
除了場景中目標數量之外,基于與自車的距離的目標分布是揭示數據集的多樣性和顯著差異的另一個重要點,如下圖15所示。Waymo 數據集展示了大量標注目標在近場到中場場景中。相反,Argoverse 2 和 ZOD 展示了更寬的檢測范圍,有些幀甚至包括超過200米的邊界框。nuScenes 的曲線意味著它在較短范圍內的目標非常豐富,這在城市駕駛場景中是典型的。然而,隨著距離的增加,nuScenes 數據集的目標數量迅速減少。ONCE 數據集覆蓋了目標在不同距離上更均勻的分布,而KITTI 數據集更注重近距離檢測。
討論與未來工作
本文主要關注分析現有數據集,這些數據集通常包含豐富的視覺數據,并旨在完成模塊化pipeline中的任務。然而,隨著技術的迅速發展,尤其是大語言模型的出色性能,下一代自動駕駛數據集出現了許多新的趨勢,提出了新的挑戰和需求。
端到端駕駛數據集。與模塊化設計的自動駕駛pipeline相比,端到端架構簡化了整體設計過程并減少了集成復雜性。UniAD 的成功驗證了端到端模型的潛在能力。然而,端到端自動駕駛的數據集數量有限 。因此,引入專注于端到端駕駛的數據集對推動自動駕駛車輛的發展至關重要。另一方面,在數據引擎中實施自動標注pipeline可以顯著促進端到端駕駛框架和數據的開發 。
自動駕駛數據集中引入語言。視覺語言模型(VLMs)最近在許多領域取得了令人印象深刻的進展。其在為視覺任務提供語言信息方面的固有優勢使得自動駕駛系統更具解釋性和可靠性。強調了多模式大語言模型在各種自動駕駛任務中的重要作用,例如感知 ,運動規劃 和控制 。下面表 VII 中展示了包含語言標簽的自動駕駛數據集。總體而言,將語言納入自動駕駛數據集是未來數據集發展的趨勢。

通過VLMs生成數據。正如所提到的,VLMs的強大能力可以用于生成自動駕駛數據。例如,DriveGAN 通過在沒有監督的情況下解開不同組件來生成高質量的自動駕駛數據。此外,由于世界模型理解駕駛環境的能力,一些工作探索了使用世界模型生成高質量駕駛視頻。DriveDreamer 作為從真實場景中派生的先驅性工作,解決了游戲環境或仿真設置的局限性。
域自適應。域自適應是開發自動駕駛車輛時面臨的關鍵挑戰 ,它指的是在一個數據集(源域)上訓練的模型在另一個數據集(目標域)上能夠穩定執行的能力。這個挑戰表現在多個方面,如環境條件的多樣性 、傳感器設置 或從合成到真實的轉換 。
結論
本文對200多個現有的自動駕駛數據集進行了詳盡而系統的回顧和分析。從傳感器類型和模態、感知領域以及與自動駕駛數據集相關的任務開始。引入了一個稱為"影響分數"的新型評估指標,以驗證感知數據集的影響力和重要性。隨后,展示了幾個高影響力數據集,涉及感知、預測、規劃、控制和端到端自動駕駛。此外,解釋了自動駕駛數據集的標注方法,并調查了影響標注質量的因素。
此外,描述了收集到的數據集的年代和地理分布,為理解當前自動駕駛數據集的發展提供了全面的視角。同時,研究了幾個數據集的數據分布,為理解不同數據集之間的差異提供了一個具體的觀點。最后,討論了下一代自動駕駛數據集的發展和趨勢。























