還不知道?近20+自動駕駛數據集、榜單和Benchmark匯總
本文經自動駕駛之心公眾號授權轉載,轉載請聯系出處。
1.Nuscenes
數據集鏈接:nuScenes
nuscenes數據集下有多個任務,涉及Detection(2D/3D)、Tracking、prediction、激光雷達分割、全景任務、規(guī)劃控制等多個任務;
nuScenes數據集是一個具有三維目標注釋的大型自動駕駛數據集,也是目前主流算法評測的benchmark,它的特點:
● 全套傳感器套件(1個激光雷達、5個雷達、6個攝像頭、IMU、GPS)
● 1000個20s的場景
● 1400000張相機圖像
● 39萬次激光雷達掃描
● 兩個不同的城市:波士頓和新加坡
● 左側交通與右側交通
● 詳細地圖信息
● 為23個目標類手動注釋的1.4M 3D邊界框
2.KITTI
數據集官網:The KITTI Vision Benchmark Suite (cvlibs.net)
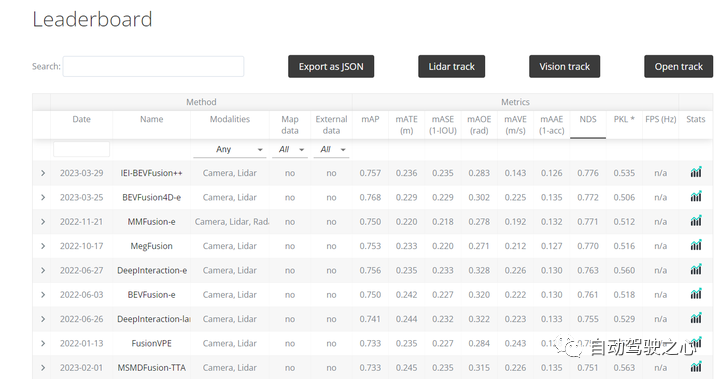
ITTI數據集由德國卡爾斯魯厄理工學院和豐田美國技術研究院聯合創(chuàng)辦,該數據集用于評測立體視覺(stereo),光流(optical flow),視覺測距(visual odometry),3D物體檢測(object detection)和3D跟蹤(tracking)等計算機視覺技術在車載環(huán)境下的性能。KITTI包含市區(qū)、鄉(xiāng)村和高速公路等場景采集的真實圖像數據,每張圖像中最多達15輛車和30個行人,還有各種程度的遮擋與截斷。整個數據集由389對立體圖像和光流圖,39.2 km視覺測距序列以及超過200k 3D標注物體的圖像組成 ,以10Hz的頻率采樣及同步。總體上看,原始數據集被分類為’Road’, ’City’, ’Residential’, ’Campus’ 和 ’Person’。對于3D物體檢測,label細分為car, van, truck, pedestrian, pedestrian(sitting), cyclist, tram以及misc組成。
因為數據量少,目前很多算法驗證都在nuscenes上啦~~~

3.Wamyo
年份:2020年;
作者:Waymo LLC和Google LLC
場景數:共1150個場景,主要采集自San Francisco,Mountain View,Phoenix等;
類別數:共4類,分別是Vehicles,Pedestrians,Cyclists及Signs;
是否360°采集:是;
數據總量:共包含 2030個片段,每個片段長度為20秒;
標注總數:約12,600,000個3D標注框;
傳感器型號:包含1個mid-range LiDAR,4個short-range LiDARs,5個相機(前置及側面),同時LiDAR和相機是經過同步和標定處理過的;
數據集鏈接:https://waymo.com/open/;
簡介:Waymo是自動駕駛領域最重要的數據集之一,規(guī)模很大,主要用以支持自動駕駛感知技術的研究。Waymo主要由兩個數據集組成,Perception Dataset及Motion Dataset。其中,Perception Dataset包含3D標注,2D全景分割標注,關鍵點標注,3D語義分割標注等。Motion Dataset主要用于交互任務的研究,共包含103,354個20s片段,標注了不同物體及對應的3D地圖數據。

4.BDD100K
BDD100K數據集是2018年5月由伯克利大學AI實驗室(BAIR)所發(fā)布,同時設計了一個圖片標注系統(tǒng)。BDD100K數據集包含10萬段高清視頻,每個視頻約40秒/720p/30 fps 。每個視頻的第10秒對關鍵幀進行采樣,得到10萬張圖片,圖片分辨率為1280*720,并對其進行標注。數據庫集包含了不同天氣、場景、時間的圖片,具有規(guī)模大,多樣化的特點。
主要任務:視頻、可行使區(qū)域、車道線、語義分割、實力分割、全景分割、MOT、檢測任務、Pose等;
數據集鏈接:Berkeley DeepDrive

5.Lyft L5數據集
年份:2019年;
作者:Woven Planet Holdings;
場景數:共1805個場景,室外;
類別數:共9類,包括Car,Pedestrian,traffic lights等;
是否360°采集:是;
數據總量:包括46,000張圖像數據,及其對應的點云數據;
標注總數:約1300,000個3D標注框;
傳感器型號:包括2個LiDARs,分別是40線和64線,安裝在車頂及保險杠上,其分辨率為0.2°,在10Hz下采集約216,000個點。此外,還包括6個360°相機和1個長焦相機,攝像機與LiDAR采集頻率一致。
數據集鏈接:https://level-5.global/data/;
簡介:Lyft L5是一整套L5級自動駕駛數據集,據稱“業(yè)內最大的自動駕駛公共數據集”,涵蓋了Prediction Dataset及Perception Dataset。其中Prediction Dataset涵蓋了自動駕駛測車隊在Palo Alto沿線遇到的各類目標,如Cars,Cyclists和Pedestrians。Perception Dataset則涵蓋了自動駕駛車隊裝置的LiDARs和攝像機采集的真實數據,并通過人工方式標注了大量的3D邊界框。
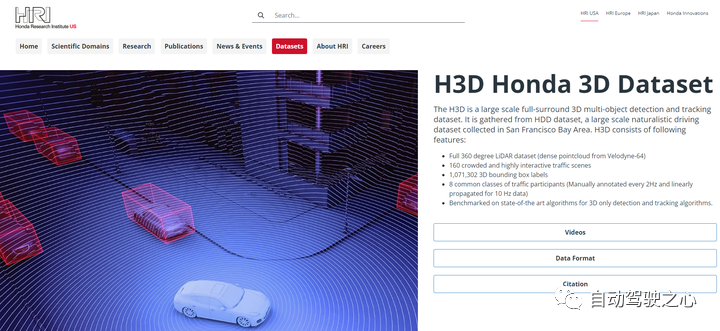
6.H3D數據集
年份:2019年;
作者:Honda Research Institute;
場景數:共160個場景,室外;
類別數:共8類;
是否360°采集:否;
數據總量:包括27,000張圖像數據,及其對應的點云數據;
標注總數:約1100,000個3D標注框;
傳感器型號:共配備了3個相機型號為Grasshopper 3,分辨率均為1920x1200,除了背面的相機FOV為80°,其他的2個相機的FOV為90°,使用了一個64線的LiDAR,型號為Velodyne HDL64E S2,以及一個GNSS+IMU型號為ADMA-G;
數據集鏈接:http://usa.honda-ri.com/H3D;
簡介:本田研究所于2019年3月發(fā)布其無人駕駛方向數據集H3D。該數據集使用3D LiDAR掃描儀收集的包括3D多目標檢測和跟蹤數據,包含160個擁擠且高度互動的交通場景,在27,721幀中有超過100萬個標記實例。
主要任務包括:
7.ApplloScape數據集
年份:2019年;
作者:Baidu Research;
場景數:共103個場景,室外;
類別數:共26類,包括small vehicles,big vehicles,pedestrian,motorcyclist等;
是否360°采集:否;
數據總量:包括143,906張圖像數據,及其對應的點云數據;
標注總數:標注總數未知;
傳感器型號:共配置了2個VUX-1HA laser scanners,6個VMX-CS6相機(其中兩個前置相機分辨率為3384x2710),還有一個IMU/GNSS設備;laser scanners利用兩束激光來掃描其周圍環(huán)境,與常用的Velodyne HDL64E相比,scanner可以獲得更高密度的點云,同時具備更高精度(5mm/3mm);
數據集鏈接:http://apolloscape.auto/index.html;
簡介:ApolloScape由RGB視頻和對應的稠密點云組成。包含超過140K張圖片,并且每張圖片都有像素級的語義信息。在國內采集的數據,所以相比于國外的一些數據集,ApolloScape數據集包含的交通場景較復雜,各類目標數量較多,且與KITTI數據集類似,同樣包含Easy,Moderate,Hard三個子集。
主要任務包括:車道線、定位、軌跡預測、檢測、跟蹤、雙目、場景識別等;

8.Argoverse數據集
年份:2019年;
作者:Argo AI等;
場景數:共113個場景,室外,包括USA,Pennsylvania,Miami,Florida等;
類別數:共15類,包括Vehicle,Pedestrian,Stroller,Animal等;
是否360°采集:是;
數據總量:包括44,000張圖像數據,及其對應的點云數據;
標注總數:約993,000個3D標注框;
傳感器型號:與KITTI及nuScenes相似,Argoverse數據集配置了兩個32線LiDAR傳感器,型號為VLP-32。同時,包括7個高分辨率環(huán)視相機,分辨率為1920x1200,2個前置相機,分辨率為2056x2464;
數據集鏈接:https://www.argoverse.org/;
主要任務:3D跟蹤、運動預測等任務
簡介:Argoverse中的數據來自Argo AI的自動駕駛測試車輛在邁阿密和匹茲堡(這兩個美國城市面臨不同的城市駕駛挑戰(zhàn)和當地駕駛習慣)運行的地區(qū)的子集。包括跨不同季節(jié),天氣條件和一天中不同時間的傳感器數據或“日志段”的記錄,以提供廣泛的實際駕駛場景。其包含了共113個場景的3D跟蹤注釋,每個片段長度為15-30秒,共計包含11052個跟蹤目標。其中,70%的標注對象為車輛,其余對象為行人、自行車、摩托車等;此外,Argoverse包含高清地圖數據,主要囊括匹茲堡和邁阿密290公里的車道地圖,如位置、連接、交通信號、海拔等信息。
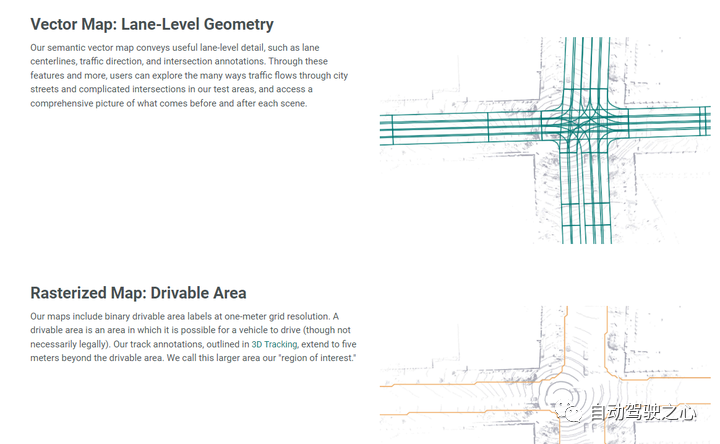
9.Argoversev2數據集
Argoverse 2是一個開源自動駕駛數據和高清(HD)地圖的集合,來自美國六個城市:奧斯汀、底特律、邁阿密、匹茲堡、帕洛阿爾托和華盛頓特區(qū)。本次發(fā)布建立在Argovverse(“Argoverse1”)的首次發(fā)布基礎上,Argovverse1是首批包含用于機器學習和計算機視覺研究的高清地圖的數據發(fā)布之一。
Argoverse 2包括四個開源數據集:
Argoverse 2傳感器數據集:包含1000個帶有激光雷達、立體圖像和環(huán)形攝像頭圖像的3D注釋場景。該數據集改進了Argoverse 1 3D跟蹤數據集;
Argoverse 2運動預測數據集:包含250000個場景,其中包含許多對象類型的軌跡數據。該數據集改進了Argoverse 1運動預測數據集;
Argoverse 2激光雷達數據集:包含20000個未標記的激光雷達序列;
Argoverse 2地圖更改數據集:包含1000個場景,其中200個場景描述了真實世界的高清地圖更改!
Argoverse 2數據集共享一種通用的高清地圖格式,該格式比Argoverse 1中的高清地圖更豐富。Argoverse 2數據集還共享一個通用的API,允許用戶輕松訪問和可視化數據和地圖。

10.Occ3D
清華大學和英偉達出品,第一個大規(guī)模占用柵格benchmark!
數據集鏈接:Occ3D: A Large-Scale 3D Occupancy Prediction Benchmark for Autonomous Driving (tsinghua-mars-lab.github.io)
作者生成了兩個3D占用預測數據集,Occ3D nuScenes和Occ3D Waymo。Occ3D nuScenes包含600個用于訓練的場景、150個用于驗證的場景和150個用于測試的場景,總計40000幀。它有16個公共類和一個額外的通用對象(GO)類。每個樣本覆蓋范圍為[-40m、-40m、-1m、40m、40m、5.4m],體素大小為[0.4m、0.4m、0.4m]。Occ3D Waymo包含798個用于訓練的序列,202個用于驗證的序列,累積了200000幀。它有14個已知的目標類和一個額外的GO類。每個樣本覆蓋的范圍為[-80m、-80m、-1m、80m、80m和5.4m],極細的體素大小為[0.05m、0.05m、0.05m]。

11.nuPlan
nuPlan是世界上第一個自動駕駛的大規(guī)模規(guī)劃基準,雖然越來越多的基于ML的運動規(guī)劃人員,但由于缺乏既定的數據集、模擬框架和指標,限制了該領域的進展。自動駕駛汽車運動預測的現有基準(Argovest、Lyft、Waymo)專注于其他智能體的短期運動預測,而不是自我汽車的長期規(guī)劃。這導致以前的工作使用基于L2的指標進行開環(huán)評估,這不適合公平評估長期規(guī)劃。這個基準測試通過提供一個訓練框架來開發(fā)基于機器學習的規(guī)劃者、一個輕量級閉環(huán)模擬器、特定于運動規(guī)劃的指標和一個可視化結果的交互式工具,克服了這些限制。
提供了一個大規(guī)模數據集,其中包含來自美國和亞洲4個城市(波士頓、匹茲堡、拉斯維加斯和新加坡)的1200小時人類駕駛數據。數據集使用最先進的Offline Perception系統(tǒng)自動標記。與現有的這種大小的數據集相反,不僅發(fā)布了數據集中檢測到的對象的3d框,還提供了10%的原始傳感器數據(120h)。
數據集鏈接:nuPlan (nuscenes.org)

12.ONCE (One Million Scenes)
● 發(fā)布方:華為
● 發(fā)布時間:2021
● 簡介:ONCE(One millioN sCenEs)是自動駕駛場景下的3D物體檢測數據集。ONCE 數據集由 100 萬個 LiDAR 場景和 700 萬個對應的相機圖像組成。這些數據選自 144 個駕駛小時,比 nuScenes 和 Waymo 等其他可用的 3D 自動駕駛數據集長 20 倍,并且是在一系列不同的地區(qū)、時期和天氣條件下收集的。由組成:100 萬個 LiDAR 幀,700 萬個相機圖像 200 平方公里的駕駛區(qū)域,144 個駕駛小時 15k 個完全注釋的場景,分為 5 個類別(汽車、公共汽車、卡車、行人、騎自行車的人) 多樣化的環(huán)境(白天/夜晚、晴天/雨天、城市/郊區(qū))。
● 下載地址:https://opendatalab.org.cn/ONCE
● 論文地址:https://arxiv.org/pdf/2106.1103
13.Cityscape
● 發(fā)布方:達姆施塔特工業(yè)大學 · 馬克斯普朗克信息學研究所 ● 發(fā)布時間:2016
● 簡介:Cityscapes是一個大型數據庫,專注于對城市街道場景的語義理解。它為分為8個類別 (平面,人類,車輛,構造,對象,自然,天空和虛空) 的30個類提供語義,實例和密集的像素注釋。數據集由大約5000個精細注釋圖像和20000個粗糙注釋圖像組成。在幾個月,白天和良好的天氣條件下,在50個城市中捕獲了數據。它最初被記錄為視頻,因此手動選擇幀以具有以下功能: 大量動態(tài)對象,不同的場景布局和不同的背景。
● 下載地址:https://opendatalab.org.cn/CityScapes
● 論文地址:https://arxiv.org/pdf/1604.0168
14.YouTube Driving Dataset
● 發(fā)布方:香港中文大學 · 加州大學 ● 發(fā)布時間:2022
● 簡介:從YouTube上抓取第一視圖駕駛視頻。收集總長度超過120小時的134視頻。這些視頻涵蓋了具有各種天氣條件 (晴天,雨天,下雪等) 和區(qū)域 (農村和城市地區(qū)) 的不同駕駛場景。每一秒鐘采樣一個幀,得到130萬幀的數據集。將YouTube駕駛數據集分為具有70% 數據的訓練集和具有30% 數據的測試集,并在訓練集上進行ACO的訓練。
● 下載地址:https://opendatalab.org.cn/YouTube_Driving_Dataset
● 論文地址:https://arxiv.org/pdf/2204.02393.pdf
15. A2D2
● 發(fā)布方:奧迪
● 發(fā)布時間:2020
● 簡介:我們已經發(fā)布了奧迪自動駕駛數據集 (A2D2),以支持從事自動駕駛的初創(chuàng)公司和學術研究人員。為車輛配備多模式傳感器套件,記錄大型數據集并對其進行標記是耗時且費力的。A2D2數據集消除了這種高進入壁壘,并使研究人員和開發(fā)人員可以專注于開發(fā)新技術。數據集具有2D語義分割,3D點云,3D邊界框和車輛總線數據。
● 下載地址:https://opendatalab.org.cn/A2D2
● 論文地址:https://arxiv.org/pdf/2004.0632
16.Cam2BEV
● 發(fā)布方:亞琛工業(yè)大學
● 發(fā)布時間:2020
該數據集包含兩個合成的、語義分割的道路場景圖像子集,它們是為開發(fā)和應用論文“A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented”中描述的方法而創(chuàng)建的。該數據集可以通過 Github 上描述的 Cam2BEV 方法的官方代碼實現來使用。
數據集鏈接:Cam2BEV-OpenDataLab
17.SemanticKITTI
● 發(fā)布方:波恩大學
● 發(fā)布時間:2019
這是一個基于 KITTI Vision Benchmark 的大規(guī)模數據集,并使用了里程計任務提供的所有序列。我們?yōu)樾蛄?00-10 的每個單獨掃描提供密集注釋,這使得能夠使用多個順序掃描進行語義場景解釋,如語義分割和語義場景補全。剩余的序列,即序列 11-21,被用作測試集,顯示大量具有挑戰(zhàn)性的交通情況和環(huán)境類型。未提供測試集的標簽,我們使用評估服務對提交進行評分并提供測試集結果。
● 下載地址:https://opendatalab.org.cn/SemanticKITTI
● 論文地址:https://arxiv.org/pdf/1904.0141
18. OpenLane
● 發(fā)布方:上海人工智能實驗室 · 上海交通大學 · 商湯科技研究所
● 發(fā)布時間:2022
OpenLane 是迄今為止第一個真實世界和規(guī)模最大的 3D 車道數據集。我們的數據集從公共感知數據集 Waymo Open Dataset 中收集有價值的內容,并為 1000 個路段提供車道和最近路徑對象(CIPO)注釋。簡而言之,OpenLane 擁有 200K 幀和超過 880K 仔細注釋的車道。我們公開發(fā)布了 OpenLane 數據集,以幫助研究界在 3D 感知和自動駕駛技術方面取得進步。
● 下載地址:https://opendatalab.org.cn/OpenLane
● 論文地址:https://arxiv.org/pdf/2203.11089.pdf
19. OpenLane-V2
● 發(fā)布方:上海人工智能實驗室
● 發(fā)布時間:2023
全球首個自動駕駛道路結構感知和推理基準。數據集的首要任務是場景結構感知和推理,這需要模型能夠識別周圍環(huán)境中車道的可行駛狀態(tài)。該數據集的任務不僅包括車道中心線和交通要素檢測,還包括檢測到的對象的拓撲關系識別。
● 下載地址:https://opendatalab.org.cn/OpenLane-V2

原文鏈接:https://mp.weixin.qq.com/s/rNc16TLtZFvvkw0BED8hiA