













微軟Windows Azure計算云發生全局故障
微軟Windows Azure云日前在全球范圍內發生部分計算停運事故,這讓我們不禁要問:微軟到底是如何對其服務進行有效劃分的?
根據微軟公司的服務信息面板顯示,問題出現在早上2:35(UTC),而且一直延續至當天晚上10:20(UTC)。
“在云服務上以手動操作執行交換部署可能產生錯誤,這將導致一部分服務管理功能受限,”微軟解釋稱。
Azure的每一個區域——即使地理跨度相當遙遠且歸屬于完全不同的數據中心群——都受到了影響,其中包括:美國西部、歐洲西部、亞洲東南部、美國中南部、歐洲北部、美國中北部、亞洲東部以及美國東部。
“我們正在采取一切必要措施,希望盡快緩解這一事件給托管服務造成的影響。進一步信息更新將在兩小時之內公布,幫助大家了解***情況。我們對于此次事件給客戶們帶來的任何不便深表歉意,”微軟公司晚上10點(UTC)這樣寫道。
交換部署操作允許開發人員在分段及生產環境之間進行虛擬IP地址交換。交換部署是一種異步操作,需要與Azure管理服務進行交互。盡管并不屬于這套IaaS云的主要組件,但停運事故仍然會給那些重量級用戶造成不良影響。此外,涉及范圍如此之廣的全局停運也很可能損害用戶對微軟規模化服務管理能力的信心。
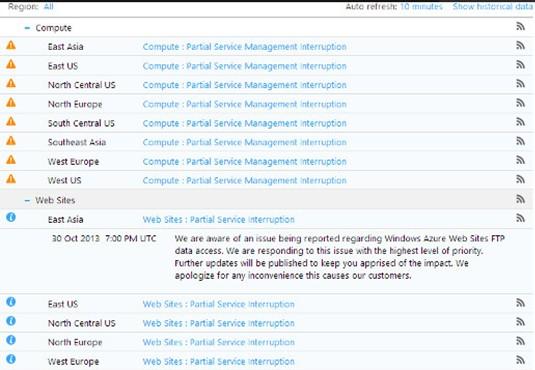
信息面板提示……對于云體系來說,全局故障絕對是可能發生的最糟糕的事態。
除了計算服務的一個子組件發生全局故障,Azure云的網站功能同樣在世界范圍內遭遇問題。由于交換部署服務失效,“FTP數據訪問”也于當天下午7點(UTC)出現連帶故障。
云計算所帶來的***擔憂就是問題會對所有區域同時造成影響。此次事故也標志著微軟在同一年中第二次遭遇并發式全局故障。
上一次讓微軟出糗的是某失效安全證書,它直接使全球范圍內的Windows Azure存儲服務陷入癱瘓。這一次的問題則由另一個更無足輕重的小小組件所引發。事實上,面對頻繁的全局失效,我們不禁要對微軟可能已經落實到位的區域劃分政策提出強烈控訴。










