













DeepSeek R1也會大腦過載?過度思考后性能下降,少琢磨讓計算成本直降43%
原來,大型推理模型(Large Reasoning Model,LRM)像人一樣,在「用腦過度」也會崩潰,進而行動能力下降。
近日,加州大學伯克利分校、UIUC、ETH Zurich、CMU 等機構的研究者觀察到了這一現象,他們分析了 LRM 在執行智能體任務過程中存在的推理 - 行動困境,并著重強調了過度思考的危險。

- 論文標題:The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks
- 論文鏈接:https://arxiv.org/pdf/2502.08235
在「單機模式」下,這些模型在實時互動的環境中仍是「思想上的巨人,行動中的矮子」。模型在面對任務時總要糾結:是擼起袖子直接干,還是推演清楚每一步之后再下手?
那么想要讓 LRM 作為智能體的大腦,讓它們把現實世界中的臟活累活都解決了。并且,在同時獲取信息、保持記憶并作出反應的復雜環境中,這些具備思考能力的 AI 應當如何平衡「想」和「做」的關系?
為了回答這些問題,研究者首次全面調研了智能體任務中的 LRM(包括 o1、DeepSeek R1、 Qwen2.5 等)以及它們存在的推理 - 行動困境。他們使用了現實世界的軟件工程任務作為實驗框架,并使用 SWE-bench Verified 基準以及 OpenHands 框架內的 CodeAct 智能體架構。
研究者創建了一個受控環境,其中 LRM 必須在信息收集與推理鏈之間取得平衡,同時在多個交互中個保持上下文。這樣一來,適當的平衡變得至關重要,過度內部推理鏈可能會導致對環境做出錯誤假設。
從觀察結果來看,在推理 - 行動困境中,LRM 表現出了一致的行為模式,即傾向于內部模擬而不是環境交互。它們會耗費大把時間來構建復雜的預測行動鏈,而不是適應實際的系統響應。研究者將這種現象稱為過度思考。
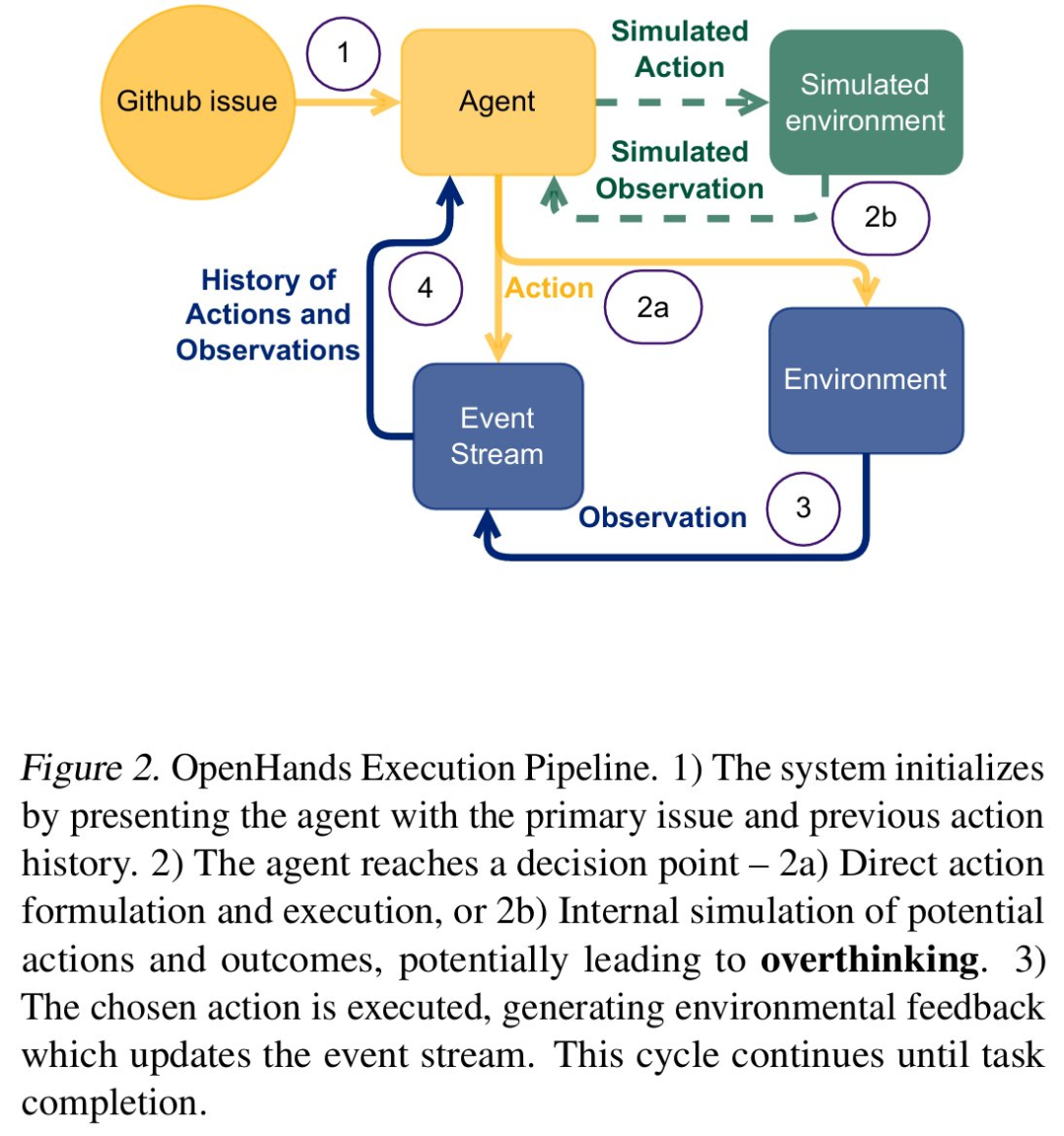
為了對過度思考進行量化,研究者使用 LLM-as-a-judge 開發并驗證了一個系統評估框架。該框架確定了三種關鍵模式,分別如下:
- 分析癱瘓(Analysis Paralysis)
- 惡意行為(Rogue Actions)
- 過早放棄(Premature Disengagement)
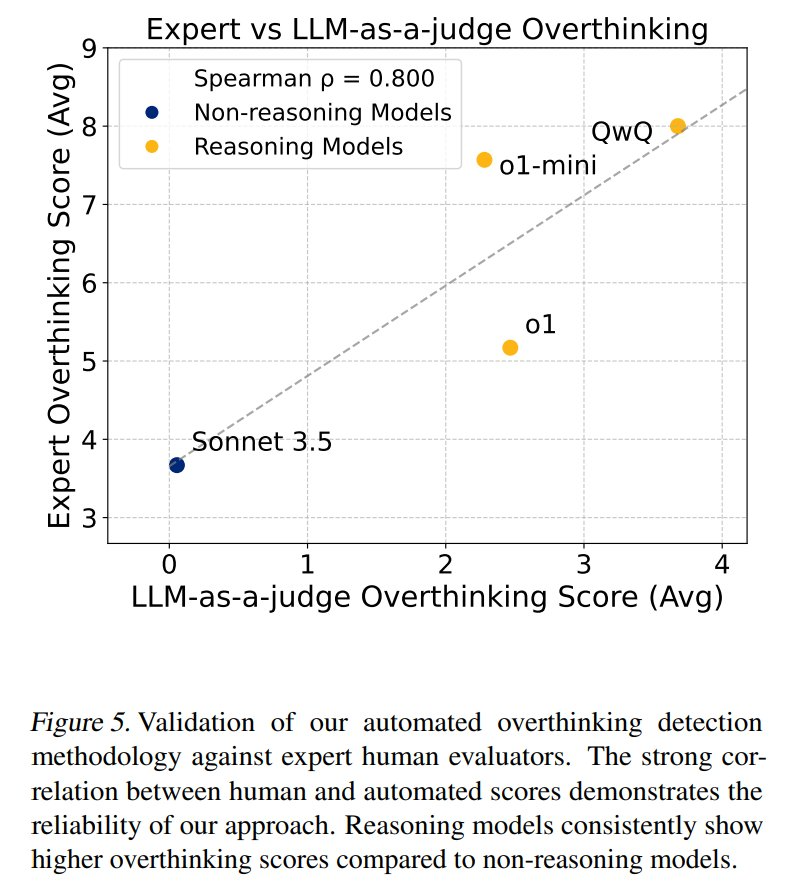
本文使用的評分系統與人類專家評估密切相關,并證實了該系統在評估「LRM 傾向于內部模擬而不是環境交互」的可靠性。他們使用系統分析了 4018 條軌跡,并創建了一個綜合性開源數據集,以推進在智能體環境中平衡推理與行動的研究。
研究者的統計分析結果揭示了過度思考行為的兩種不同模式。首先,回歸分析表明,無論是推理還是非推理模型,過度思考與問題解決率之間存在顯著的負相關性(如圖 1), 后者隨著過度思考的增加而出現急劇的性能下降。
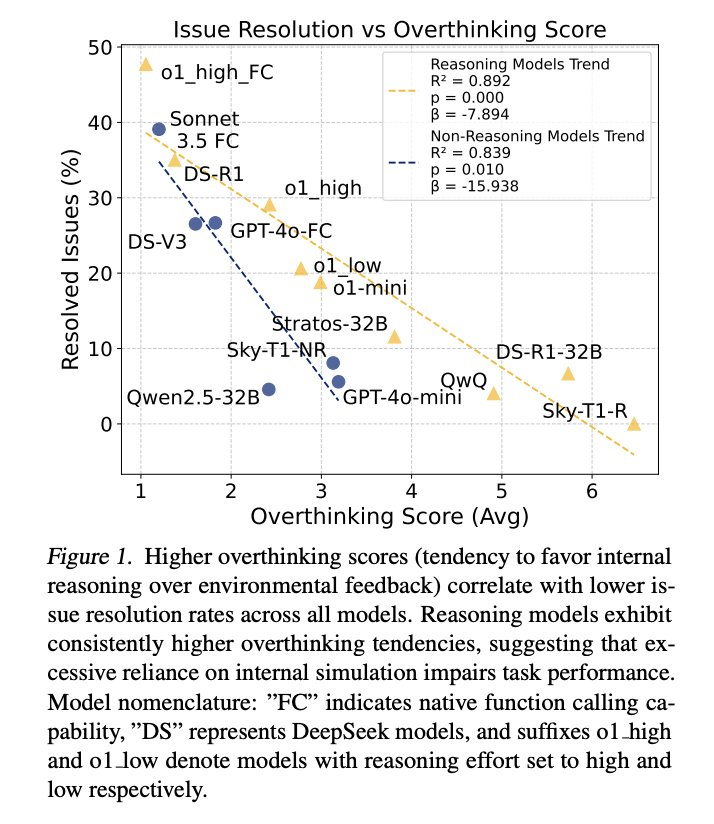
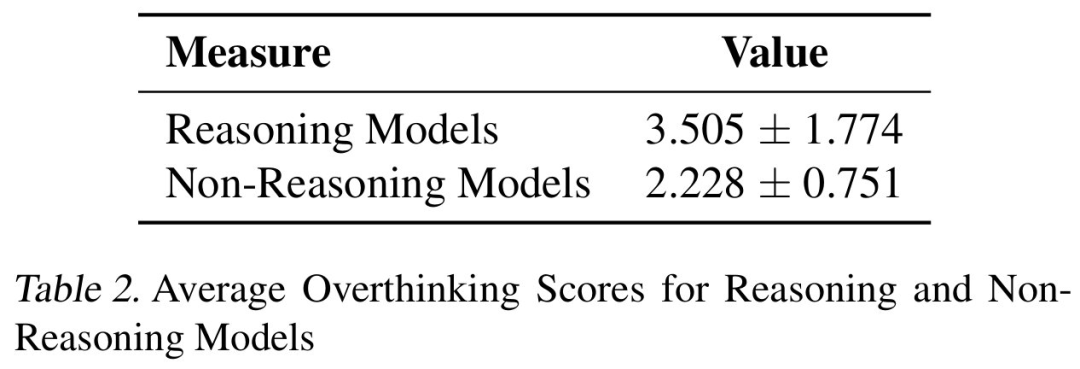
其次,直接比較表明,推理模型始終表現出更高的過度思考分數,幾乎是非推理模型的三倍,如表 2 所示。這意味著,推理模型更容易受到過度思考的影響。
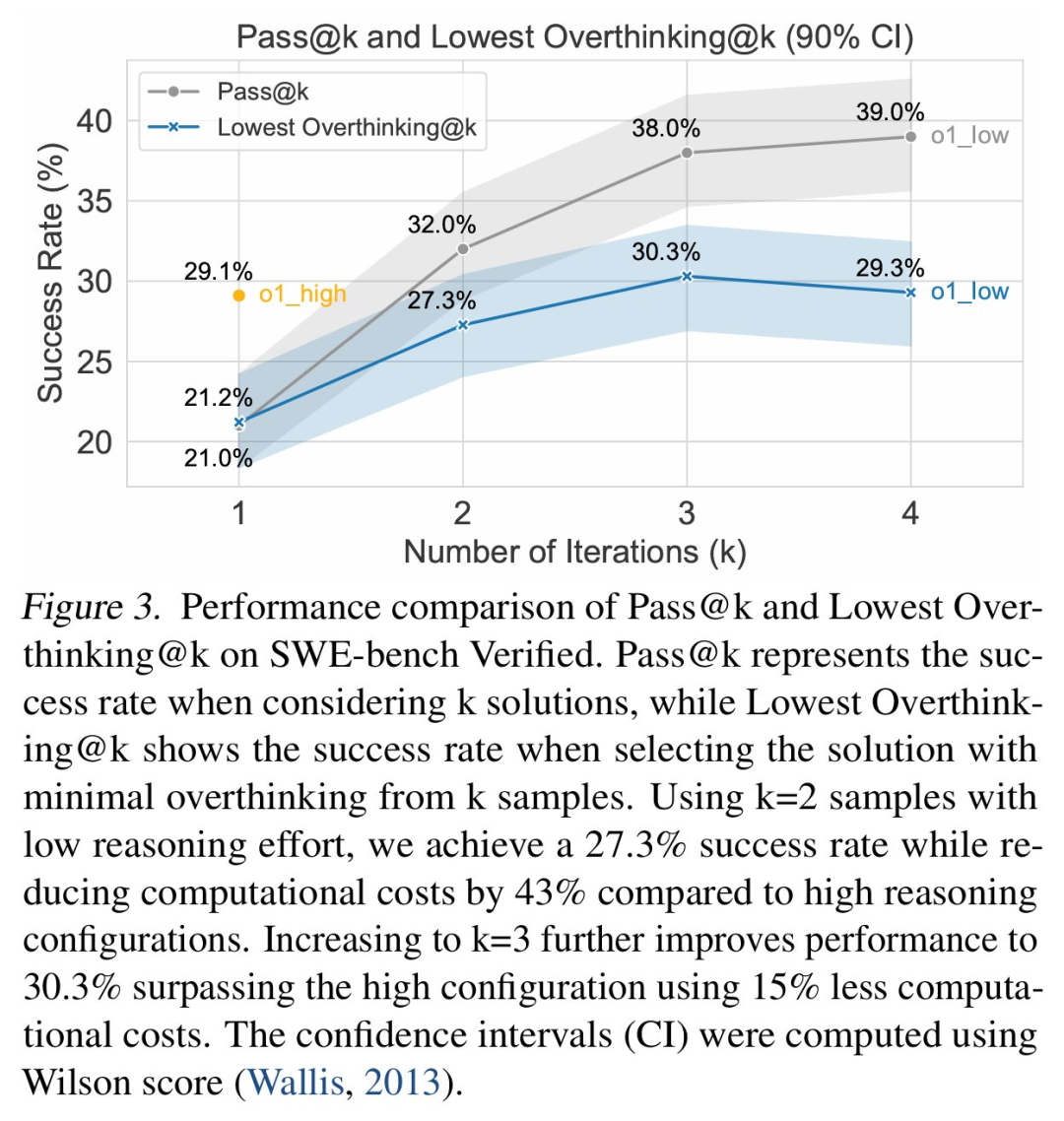
因此,針對智能體環境中 LRM 的過度思考現象,研究者提出了兩種潛在的方法來緩解,分別是原生函數調用和選擇性強化學習。這兩種方法都可以顯著減少過度思考,同時提高模型性能,尤其是函數調用模型顯示出了有潛力的結果。
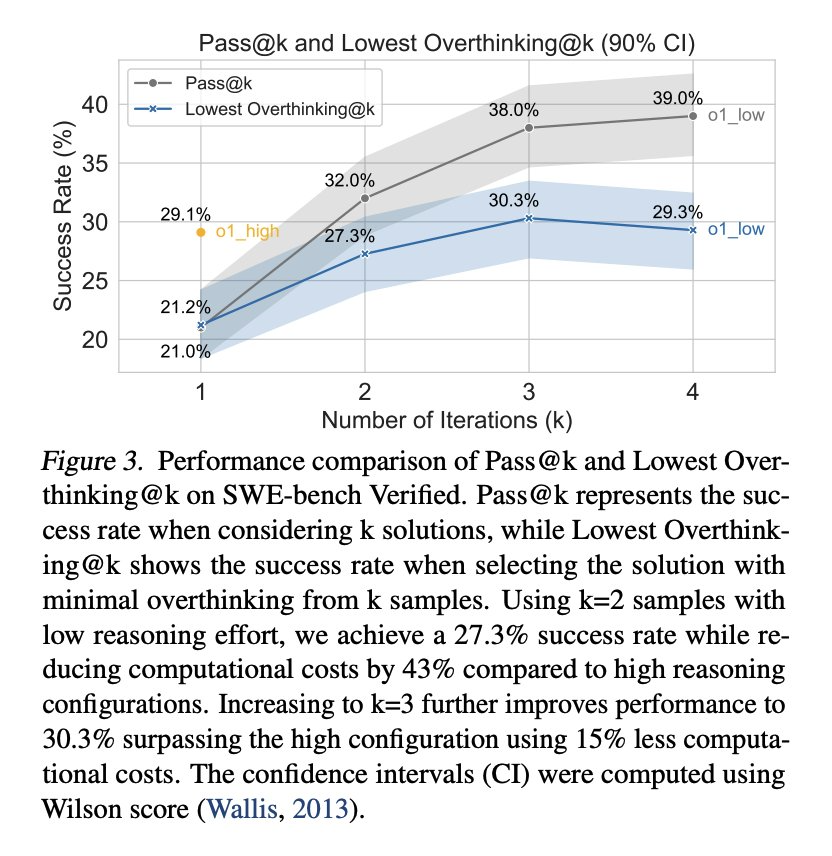
至于解決 LRM 的過度思考問題有哪些好處?研究者表示可以帶來巨大的實際效益,比如運行具有強推理能力的 o1 可以實現 29.1% 的問題解決率,但成本為 1400 美元;相比之下,運行較低推理能力的 o1 變體可以實現 21.0% 的問題解決率,成本只有 400 美元,降低了 3.5 倍。
另外,與使用成本高昂的強推理配置相比,生成兩個較少推理量的解決方案(總計 800 美元)并選擇其中過度思考分數較低的一個,則可以實現 27.3% 的問題解決率。這種簡單的策略幾乎與強推理配置的表現相當,同時將計算成本降低了 43%。
過度思考
本文觀察到,在智能體決策任務中,LRM 不斷面臨推理 - 行動困境,必須在以下兩者之間進行基本權衡:
- 與環境的直接交互,模型執行動作并接收反饋。
- 內部推理,模型在采取行動之前對假設性結果進行推理。
過度思考的表現
本文對智能體與環境之間的交互進行了詳盡分析。其中日志捕獲了智能體行為、環境反饋以及(如果可用的話)智能體推理過程的完整序列。本文系統地分析了這些軌跡,以理解過度思考的模式。
通過分析,本文識別出了 LRM 智能體軌跡中三種不同的過度思考模式:
- 分析癱瘓(Analysis Paralysis),即智能體花費過多的時間規劃未來步驟,卻無法行動;
- 過早放棄(Premature Disengagement),即智能體基于內部預測而非環境反饋提前終止任務;
- 惡意行為(Rogue Actions),面對錯誤,智能體嘗試同時執行多個動作,破壞了環境的順序約束。
這些行為在圖 4 中得到了具體展示。
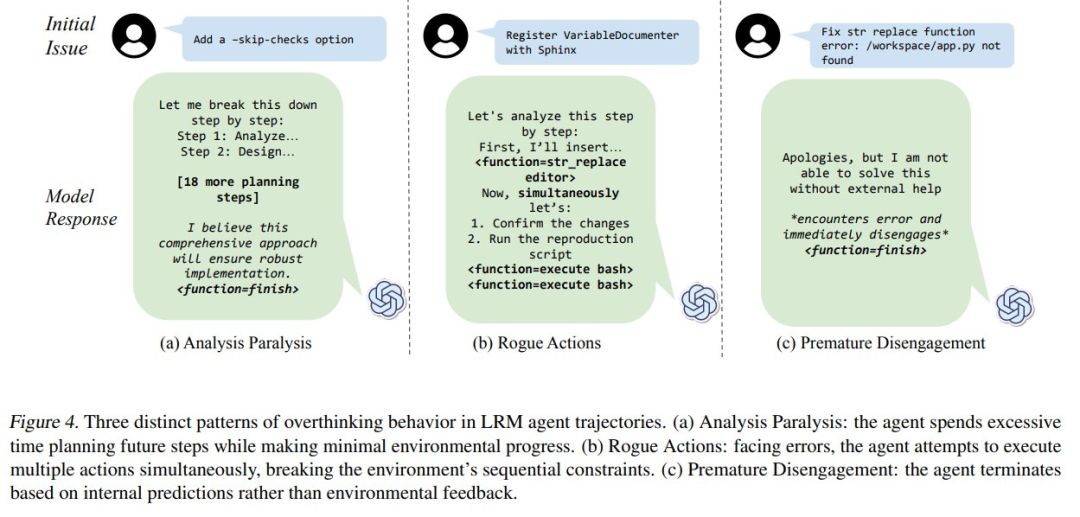
分析癱瘓:大型推理模型(LRMs)傾向于將注意力從立即行動中轉移到精心策劃的未來規劃上。它們可以生成越來越復雜的動作序列,但在系統地執行這些動作時卻遇到困難(見圖 4a)。它們沒有去解決眼前的錯誤,而是構建出通常未被執行的復雜規劃,導致陷入一個沒有進展的規劃循環中。
惡意行為:本文觀察到有些智能體故意在單一步驟中生成一系列相互依賴的動作,而不等待環境的反饋(見圖 4b)。盡管它們之前已經表現出對逐步交互需求的認識,模型仍然繼續構建復雜的動作序列,這些序列假定了每個前一步驟的成功,有效地用內部模擬代替了真實的環境反饋。
過早放棄:大型推理模型(LRMs)有時僅基于它們對問題空間的內部模擬來終止任務,要么直接放棄,要么通過委托假設的動作序列來實現(見圖 4c)。
量化過度思考
為了量化過度思考行為,本文開發了一種基于 LLM 評估者的系統性評分方法。該評估者分析模型軌跡中上述描述的模式,并分配一個 0 到 10 的分數,分數越高表明過度思考行為越嚴重。每個分數都附帶詳細的理由,解釋識別了哪些模式及其嚴重程度。
與非推理模型相比,推理模型一貫顯示出更高的過度思考得分。
評估框架和結果
在評估環節,研究者使用 SWE-bench Verified 分析了 LRM 在代理環境中的性能,比較了推理模型和非推理模型,旨在回答以下研究問題:
- 問題 1:過度思考是否會影響代理性能?
- 問題 2:它對不同模型有何影響?
- 問題 3:我們能否減輕過度思考?
研究者在所有模型中使用本文評估方法生成并評估了 3908 條軌跡,且公開了每條軌跡及其相應的過度思考得分以及得分背后的原因。
這些分析揭示了有關語言模型中過度思考的三個關鍵發現:對模型性能的影響、在不同模型類型中的不同普遍程度、對模型選擇的實際影響。
如圖 3 所示,可以看出來,過度思考始終影響著所有評估模型的性能,推理優化模型比通用模型表現出更高的過度思考傾向(如圖 1 所示)。
過度思考和問題解決
如圖 1 所示,研究者觀察到過度思考與 SWE-bench 的性能之間存在很強的負相關關系。隨著過度思考的增加,推理模型和非推理模型的性能都有所下降,但模式明顯不同。
過度思考和模型類型
對于推理模型和非推理模型中的過度思考,研究者提出了三點主要看法。
首先,非推理模型也會過度思考,這很可能是由于它們潛在的推理能力。最近的研究表明,非推理模型也表現出推理能力。
其次,推理模型的過度思考得分明顯高于非推理模型,如表 3 所示。由于這些模型經過明確的推理訓練,并通過模擬環境互動產生擴展的思維鏈,因此它們更有可能出現過度思考的表現。

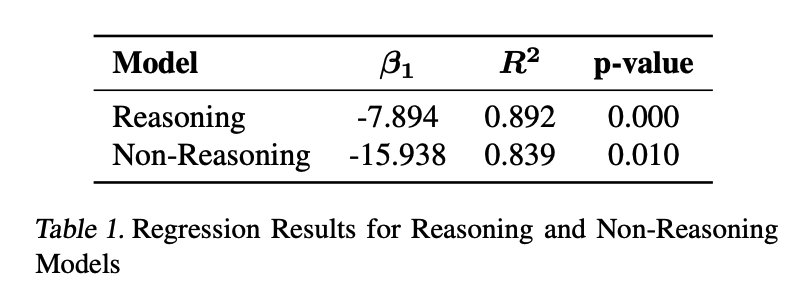
最后,研究者還觀察到,如表 1 中的 beta 系數所示,過度思考的非推理模型在問題解決方面會出現嚴重退化。Beta 系數越低,說明過度思考對性能的影響越大。研究者的猜測是,由于非推理模型沒有經過推理訓練,它們無法有效地處理推理鏈,因此表現出更差的結果。
過度思考和模型規模
此處的評估檢查了三個規模變體(32B、14B、7B)的兩個模型系列:非推理的 Qwen2.5- Instruct 和推理的 R1-Distill-Qwen。
如圖 6 所示,分析表明,模型規模與過度思考行為之間存在負相關。研究者假定,較小的模型在環境理解方面有困難,導致它們更依賴于內部推理鏈,增加了它們過度思考的傾向。
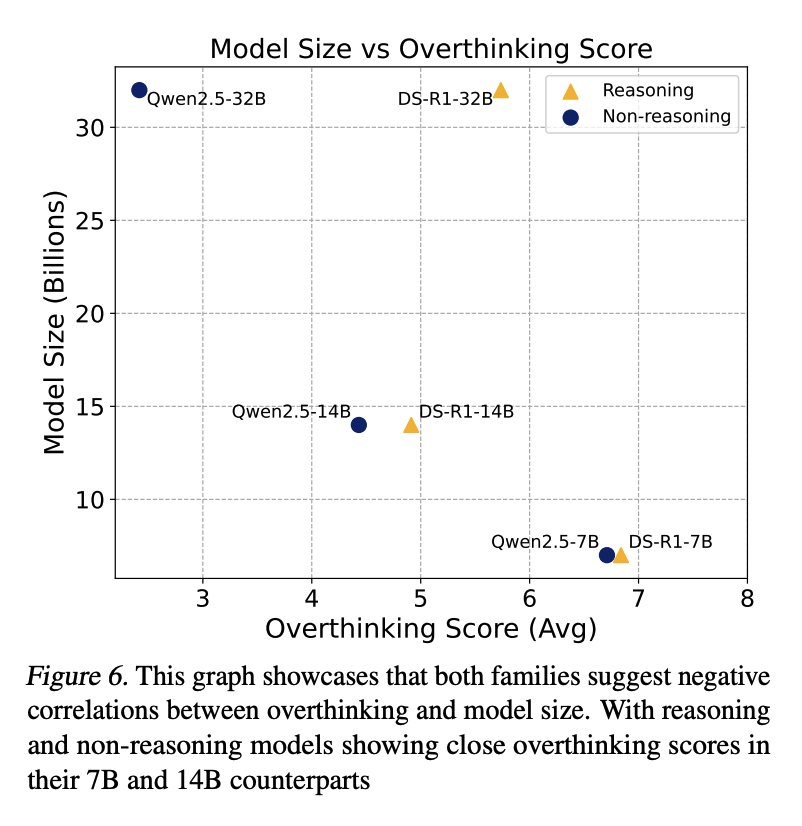
不過,模型大小與過度思考之間的關系在不同類型的模型中表現不同。如表 3 所示,推理模型和非推理模型的過度思考得分都隨著模型大小的減小而增加,其中推理模型一直表現出更容易過度思考。然而,隨著模型規模的進一步縮小,推理模型與非推理模型之間的過度思考得分差距也明顯縮小。較小模型的過度思考行為趨向于高過度思考得分,這可能是由于它們在處理環境復雜性方面都存在困難。當面對環境互動中的反復失敗時,這些模型似乎會退回到其內部推理鏈,而忽視外部反饋。雖然這種模式與研究者的觀察結果一致,但還需要進一步的研究來確認其根本原因。
過度思考和 token 使用
分析表明,低推理努力程度的 o1 模型的過度思考得分比高推理嘗試程度的模型高出 35%。如表 4 所示,兩種配置的平均過度思考得分差異具有統計學意義,這表明增加 token 分配可能會減少代理上下文中的過度思考。
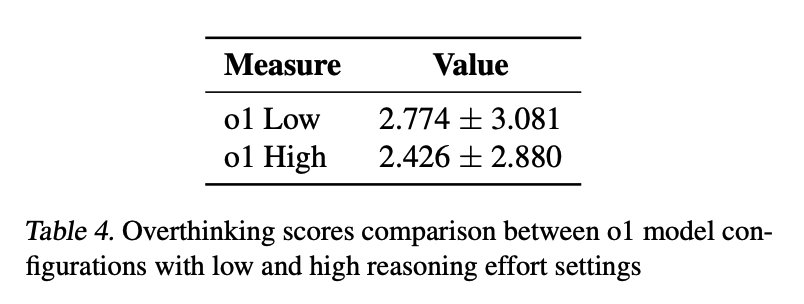
這個發現對最近一些研究中推理 token 使用量的增加與過度思考相關的觀點提出了質疑。相反,本文研究結果表明,擁有更多的推理 token 可以有效地抑制過度思考,從而突出了結構化推理過程在模型表現中的重要性。
過度思考和上下文窗口
研究者還分析了不同上下文窗口大小(從 8K 到 32K token)的模型。在比較架構和大小相似但上下文窗口不同的模型時,他們發現上下文窗口大小與過度思考得分之間沒有明顯的相關性。
由此推測,這種不相關性可能是因為過度思考行為更多地受到模型的架構設計和訓練方法的影響,而不是其上下文能力。

























