端到端自動駕駛新SOTA!港科大聯(lián)合元戎啟行共同提出PPAD端到端算法
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫在前面&筆者的個人理解
目前隨著深度學(xué)習(xí)技術(shù)的快速蓬勃發(fā)展為自動駕駛領(lǐng)域的研發(fā)提供了強(qiáng)大的助力。目前的自動駕駛系統(tǒng)由于其方便解耦和可解釋性的離散化模塊設(shè)計(jì)使得自動駕駛領(lǐng)域產(chǎn)生了很多令我們興奮的成績。自動駕駛系統(tǒng)中的傳統(tǒng)方法通常將系統(tǒng)分解為模塊化組件,包括定位、感知、跟蹤、預(yù)測、規(guī)劃和控制,以實(shí)現(xiàn)更好的可解釋性和可見性。然而這類系統(tǒng)卻存在著一些問題:(1)隨著系統(tǒng)復(fù)雜度的增加,模塊之間的誤差積累變得更加顯著,存在很大的誤差累計(jì)效應(yīng);(2)下游任務(wù)所表現(xiàn)出來的性能與上游模塊變得高度相關(guān),從而使得構(gòu)建統(tǒng)一的數(shù)據(jù)驅(qū)動網(wǎng)絡(luò)模型框架變得非常困難。
最近,端到端自動駕駛因其簡單性而受到歡迎。基于學(xué)習(xí)架構(gòu)提出了兩條主線。第一種方法以原始傳感器數(shù)據(jù)作為輸入,直接輸出規(guī)劃軌跡或控制命令,無需任何視圖變換,作為場景理解的中間表示。另外一類算法模型則是建立在BEV空間表示的基礎(chǔ)上,充分利用查詢來生成中間輸出作為生成規(guī)劃結(jié)果的指導(dǎo)。其中一個最顯著的優(yōu)勢在于可解釋性。
受到端到端自動駕駛工作VAD的啟發(fā),本文工作的目標(biāo)是將逐步預(yù)測規(guī)劃引入基于學(xué)習(xí)的框架當(dāng)中。直觀地說,預(yù)測和規(guī)劃模塊可以建模為運(yùn)動預(yù)測任務(wù),根據(jù)給定的歷史信息預(yù)測未來的路徑點(diǎn)。每個時間戳?xí)r刻的預(yù)測和規(guī)劃模塊的結(jié)果高度相互依賴。因此,我們需要迭代和雙向地考慮代理和代理之間以及代理和環(huán)境之間的相互作用,在給定其他代理觀測下實(shí)現(xiàn)代理預(yù)測期望的最大化。基于此,本文提出了PPAD端到端自動駕駛框架,可以逐步規(guī)劃自車代理的未來軌跡,在矢量學(xué)習(xí)框架下基于時間實(shí)現(xiàn)雙向交互,如下圖所示。

提出的PPAD算法模型的概括示意圖
論文鏈接:https://arxiv.org/pdf/2311.08100
官方倉庫鏈接:https://github.com/zlichen/PPAD;
網(wǎng)絡(luò)模型的整體架構(gòu)&細(xì)節(jié)梳理
在詳細(xì)介紹本文提出的PPAD端到端算法模型細(xì)節(jié)之前,下圖展示了我們提出的PPAD算法的整體網(wǎng)絡(luò)結(jié)構(gòu)圖。

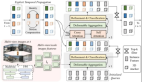
提出的PPAD算法模型的整體網(wǎng)絡(luò)結(jié)構(gòu)圖
通過上圖的整體網(wǎng)絡(luò)結(jié)構(gòu)可以看出,提出的PPAD算法模型主要包括感知Transformer和我們提出的迭代預(yù)測規(guī)劃模塊。整體而言,感知Transformer將場景上下文信息編碼為BEV空間特征圖,并進(jìn)一步解碼為矢量化代理和地圖表示。迭代預(yù)測規(guī)劃模塊通常由預(yù)測和規(guī)劃兩個過程組成。它剖析了自車和其他代理在時間維度上的動態(tài)交互。最終,該模塊預(yù)測代理的運(yùn)動并規(guī)劃自車的未來行駛軌跡。
具體而言,對于輸入到網(wǎng)絡(luò)模型中的環(huán)視圖像特征,我們采用一個共享的圖像主干網(wǎng)絡(luò)來提取每個視角的圖像特征。再得到每個視角的圖像特征之后,我們采用了BEVFormer中的Encoder模塊來得到統(tǒng)一的BEV空間特征。此外,受到端到端自動駕駛框架VAD的啟發(fā),我們也通過解碼器和地圖元素解碼器將場景上下文信息完成矢量化的表示,進(jìn)而得到可學(xué)習(xí)的代理查詢和可學(xué)習(xí)的地圖查詢。單獨(dú)的基于多層感知機(jī)的解碼器通過采用學(xué)習(xí)到的查詢作為輸入,并使用代理的屬性和地圖屬性進(jìn)行預(yù)測得到最終的輸出。此外,代理查詢將與可學(xué)習(xí)的運(yùn)動嵌入相結(jié)合,以對代理的各種運(yùn)動進(jìn)行建模。具有運(yùn)動的代理表示為。類似的,自車采用三種方式進(jìn)行建模,代表直行、左轉(zhuǎn)和右轉(zhuǎn)的高級駕駛命令,表示為。
然后我們采用迭代預(yù)測規(guī)劃模塊以交錯的方式預(yù)測自車和其他代理的未來軌跡。與一次性預(yù)測所有軌跡的傳統(tǒng)做法不同,我們提出的PPAD算法框架通過迭代代理運(yùn)動預(yù)測和自車規(guī)劃過程來表示運(yùn)動規(guī)劃的每個步驟。借助提出的PPAD框架,我們可以進(jìn)行深入設(shè)計(jì),以精修的方式在場景上下文中執(zhí)行關(guān)鍵對象的交互過程。
預(yù)測和規(guī)劃的迭代交互
在現(xiàn)實(shí)世界中,駕駛交通狀況不斷變化。駕駛員通過不斷推理場景中交通參與者之間的關(guān)系來規(guī)劃和執(zhí)行他們的決策。規(guī)劃任務(wù)需要自動駕駛系統(tǒng)對場景有很好的理解,并能夠解決時空因果因素。因此,我們對提出的PPAD進(jìn)行了創(chuàng)新,將規(guī)劃任務(wù)分解為代理預(yù)測和自車規(guī)劃過程的多步驟,并最終促進(jìn)自車和代理的未來軌跡達(dá)成共識。提出的PPAD框架將交通交互體現(xiàn)為沿時空的游戲,為自車提供更準(zhǔn)確的規(guī)劃軌跡。具體而言,自車和代理繼承了相同的理念,即在每個未來時間戳?xí)r刻中根據(jù)彼此的運(yùn)動預(yù)測交替優(yōu)化其運(yùn)動行為。
預(yù)測過程
代理在預(yù)測過程中預(yù)測其后續(xù)的運(yùn)動,以自車在先前規(guī)劃過程中的結(jié)果輸出為條件。具體而言,代理查詢的初始狀態(tài)包括其駕駛意圖。然后,它將與從先前規(guī)劃過程更新的自車查詢進(jìn)行交互,這表明自車當(dāng)前最新駕駛規(guī)劃。然后,它將與地圖元素交互以選擇駕駛路徑。最后,它通過與BEV空間特征進(jìn)行交互來收集詳細(xì)的幾何信息,并得出其精確的下一步運(yùn)動。
規(guī)劃過程
我們用來表示歷史時期,來代表未來時期。自車的未來軌跡可以表示為。對于每一個代理,其軌跡可以表示為。檢測到的地圖元素位置可以表示為。
代理交互

地圖交互
現(xiàn)有的一些研究工作試圖通過簡單地應(yīng)用一次全局級別的交互來總結(jié)規(guī)劃所需的所有地圖信息。但他們忽略了不斷發(fā)展的運(yùn)動動態(tài)的復(fù)雜性,高估了自車可以通過與地圖信息的單次交互進(jìn)行長期精確規(guī)劃。
利用我們提出的PPAD算法框架,我們可以根據(jù)自車的最新位置考慮其本地道路狀況,從而豐富自車與地圖的交互。這樣可以更好地識別規(guī)劃每個步驟所需的有用地圖信息。自車查詢與地圖查詢的交互方式與代理的交互方式類似。不同之處在于地圖實(shí)例在未來的時間步驟中不可移動。多頭交叉注意力機(jī)制可以將本地和全局地圖信息抽象到自車查詢中:


分層特征學(xué)習(xí)
層次結(jié)構(gòu)具有更好的捕捉和識別細(xì)粒度模式的能力。對于駕駛場景,駕駛行為基于對全局和局部場景的理解。駕駛往往只關(guān)注少數(shù)關(guān)鍵物體,這表明了空間局部性或局部注意力。因此,我們設(shè)計(jì)了分層關(guān)鍵對象注意力來利用由粗糙到精細(xì)的場景上下文。具體來說,給定一組距離范圍,我們首先找到給定范圍內(nèi)的關(guān)鍵對象。因此,我們應(yīng)用動態(tài)局部注意力,它只考慮局部區(qū)域中代理或地圖元素之間的相互作用。下面展示的偽代碼描述了動態(tài)關(guān)鍵對象注意力的實(shí)現(xiàn)。

噪聲軌跡作為預(yù)測
PPAD算法模型將預(yù)測和規(guī)劃過程交錯起來,逐步規(guī)劃自車和代理的軌跡。然后通過模仿學(xué)習(xí)將專家駕駛知識強(qiáng)化到模型中。在訓(xùn)練過程中,將噪聲軌跡作為預(yù)測引入PPAD框架。具體來說,我們通過添加噪聲來擾亂真值目標(biāo)自車軌跡的每一步。然后訓(xùn)練自車預(yù)測自車的原始下一步路徑點(diǎn)偏移,而不管其起始噪聲位置受到何種干擾。即使系統(tǒng)從不準(zhǔn)確的位置開始,它也會通過與矢量化實(shí)例和環(huán)境交互來學(xué)習(xí)預(yù)測準(zhǔn)確的路徑點(diǎn)偏移。這種策略提高了規(guī)劃性能。
實(shí)驗(yàn)結(jié)果&評價指標(biāo)
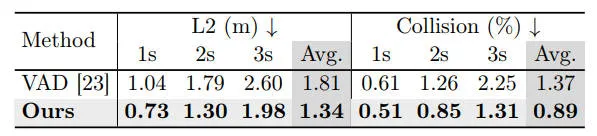
為了驗(yàn)證我們提出算法模型的有效性,我們在nuScenes數(shù)據(jù)集上進(jìn)行了開環(huán)實(shí)驗(yàn),相關(guān)的實(shí)驗(yàn)結(jié)果如下表所示。

在nuScenes 數(shù)據(jù)集上的開環(huán)規(guī)劃結(jié)果
通過實(shí)驗(yàn)結(jié)果可以看出,我們提出的PPAD算法模型大大超越了當(dāng)前最先進(jìn)算法的表現(xiàn)性能。特別是對于L2距離指標(biāo),在時間范圍內(nèi)可以觀察到約20%的持續(xù)提升。得益于提出的預(yù)測和規(guī)劃的迭代交互,PPAD算法模型可以幫助避免碰撞,與其他端到端自動駕駛算法模型VAD相比,在碰撞率方面取得了更好的結(jié)果。
此外,我們也在Argoverse2數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn)進(jìn)一步公平地比較我們的方法和基線算法模型,相關(guān)的實(shí)驗(yàn)結(jié)果如下表所示。
在Argoverse 數(shù)據(jù)集上的開環(huán)規(guī)劃結(jié)果
通過實(shí)驗(yàn)結(jié)果也可以看出,我們的方法可以在 L2 距離和碰撞率指標(biāo)方面始終以明顯優(yōu)勢超越基線。
此外,為了展示我們的PPAD整體性能,我們還在下表中提供了傳統(tǒng)感知和運(yùn)動預(yù)測任務(wù)的規(guī)劃指標(biāo)之外的評估結(jié)果。我們的 PPAD 在上游感知和預(yù)測任務(wù)中也取得了令人鼓舞的性能,這表明整個系統(tǒng)是聯(lián)合優(yōu)化的。

規(guī)劃任務(wù)以外的任務(wù)的結(jié)果比較
為了更加直觀的展示我們提出算法模型的表現(xiàn)性能,下圖是相關(guān)的可視化結(jié)果。PPAD 可以精確地感知場景,并以合理和多樣化的動作預(yù)測周圍的代理。它還為自身車輛規(guī)劃了一條平滑而準(zhǔn)確的軌跡。

結(jié)論
在本文中,我們提出了一種新穎的自動駕駛框架 PPAD。與以前缺乏深入交互建模的方法不同,我們將規(guī)劃問題提出為自我車輛和代理之間的多步驟預(yù)測和規(guī)劃過程,并且實(shí)現(xiàn)了SOTA的效果。