













26億參數(shù),智源、清華開源中文大規(guī)模預(yù)訓(xùn)練模型
近日,北京智源人工智能研究院和清華大學(xué)研究團隊聯(lián)合發(fā)布了以中文為核心的大規(guī)模預(yù)訓(xùn)練語言模型 CPM-LM,參數(shù)規(guī)模達(dá) 26 億,預(yù)訓(xùn)練中文數(shù)據(jù)規(guī)模 100 GB。
自 2018 年谷歌發(fā)布 BERT 以來,預(yù)訓(xùn)練模型在自然語言處理(NLP)領(lǐng)域逐漸成為主流。今年 5 月份,OpenAI 推出的史上最大 AI 模型 GPT-3更是引起了大量討論。但是,目前 NLP 領(lǐng)域的預(yù)訓(xùn)練模型多針對英語語言,以英語語言數(shù)據(jù)為訓(xùn)練數(shù)據(jù),例如 GPT-3:
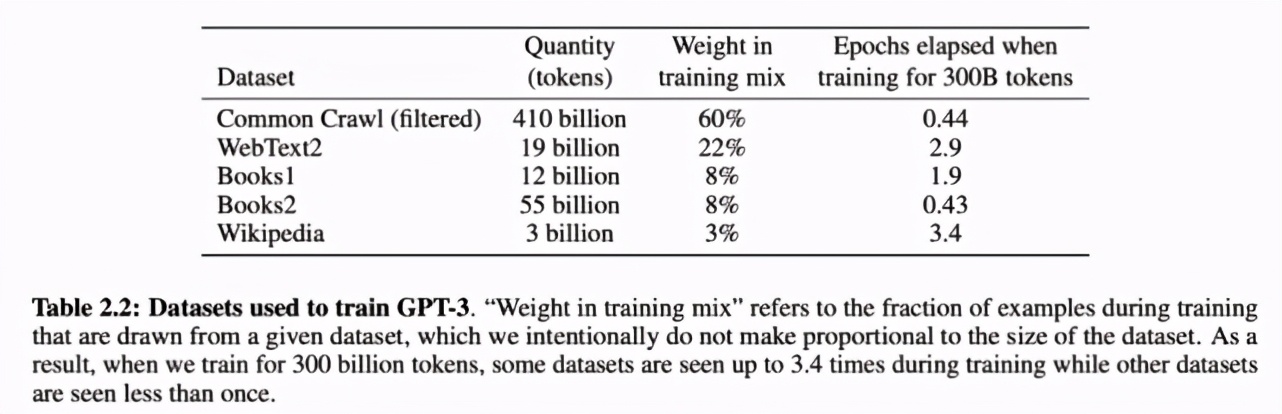
用于訓(xùn)練 GPT-3 的數(shù)據(jù)集。
近日,北京智源人工智能研究院和清華大學(xué)研究團隊合作開展了一項名為「清源 CPM (Chinese Pretrained Models)」的大規(guī)模預(yù)訓(xùn)練模型開源計劃,旨在構(gòu)建以中文為核心的大規(guī)模預(yù)訓(xùn)練模型。首期開源內(nèi)容包括預(yù)訓(xùn)練中文語言模型和預(yù)訓(xùn)練知識表示模型,可廣泛應(yīng)用于中文自然語言理解、生成任務(wù)以及知識計算應(yīng)用,所有模型免費向?qū)W術(shù)界和產(chǎn)業(yè)界開放下載,供研究使用。
清源 CPM 主頁:https://cpm.baai.ac.cn/
清源 CPM Github 托管代碼主頁:https://github.com/TsinghuaAI/
模型特點
根據(jù)清源 CPM 主頁介紹,該計劃發(fā)布的預(yù)訓(xùn)練模型具備以下特點:
模型規(guī)模大:本次發(fā)布的CPM-LM 參數(shù)規(guī)模達(dá) 26 億,預(yù)訓(xùn)練中文數(shù)據(jù)規(guī)模 100 GB,使用了 64 塊 V100 GPU,訓(xùn)練時間約為 3 周;CPM-KG 的參數(shù)規(guī)模為 217 億,預(yù)訓(xùn)練結(jié)構(gòu)化知識圖譜為 WikiData 全量數(shù)據(jù),包含近 1300 個關(guān)系、8500 萬實體、4.8 億個事實三元組,使用了 8 塊 V100 GPU 訓(xùn)練時間約為 2 周。
語料豐富多樣:收集大量豐富多樣的中文語料,包括百科、小說、對話、問答、新聞等類型。
學(xué)習(xí)能力強:能夠在多種自然語言處理任務(wù)上進(jìn)行零次學(xué)習(xí)或少次學(xué)習(xí),并達(dá)到較好的效果。
行文自然流暢:基于給定上文,模型可以續(xù)寫出一致性高、可讀性強的文本,達(dá)到現(xiàn)有中文生成模型的領(lǐng)先效果。
在模型訓(xùn)練方面,CPM 模型預(yù)訓(xùn)練過程分布在多塊 GPU 上,采用層內(nèi)并行的方法進(jìn)行訓(xùn)練,并基于當(dāng)前已有的成熟技術(shù),減少同步提高通訊速率。
在硬件設(shè)施方面,為訓(xùn)練該 CPM 模型,共有 64 塊 V100 顯卡投入使用。經(jīng)過預(yù)訓(xùn)練的 CPM 模型可以用來促進(jìn)諸多下游中文任務(wù),如對話、論文生成、完形填空和語言理解等。
為了促進(jìn)中文自然語言處理研究的發(fā)展,該項目還提供了 CPM-LM (2.6B) 模型的文本生成代碼,可用于文本生成的本地測試,并以此為基礎(chǔ)進(jìn)一步研究零次學(xué)習(xí) / 少次學(xué)習(xí)等場景,詳情參見項目 GitHub 主頁。
模型性能
清源 CPM 使用新聞、百科、對話、網(wǎng)頁、故事等不同類型的中文語料數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練。在多個公開的中文數(shù)據(jù)集上的實驗表明,清源 CPM 在少樣本或無樣本的情況下均能夠?qū)崿F(xiàn)較好的效果。
中文成語填空 ChID
ChID 是 2019 年清華大學(xué)對話交互式人工智能實驗室(CoAI)收集的中文成語填空數(shù)據(jù)集,其目標(biāo)是對于給定的段落,在 10 個候選項中選擇最符合段意的成語進(jìn)行填空。

其中有監(jiān)督設(shè)定是指在 ChID 的訓(xùn)練集上進(jìn)行訓(xùn)練,隨后在測試集上測試;無監(jiān)督設(shè)定是指不經(jīng)過任何額外訓(xùn)練,直接使用預(yù)訓(xùn)練模型進(jìn)行測試。具體做法是,將候選項依次填入段落中,計算填充后段落的困惑度 (Perplexity),選擇困惑度最小的候選項作為預(yù)測結(jié)果。表中匯報了預(yù)測的準(zhǔn)確率,可以看到,CPM (大) 在無監(jiān)督設(shè)定下甚至達(dá)到了比有監(jiān)督 CPM (小) 更好的結(jié)果,反映出清源 CPM 強大的中文語言建模能力。
對話生成 STC
STC 是 2015 年華為諾亞方舟實驗室提出的短文本對話數(shù)據(jù)集,要求在給定上文多輪對話的條件下預(yù)測接下來的回復(fù)。
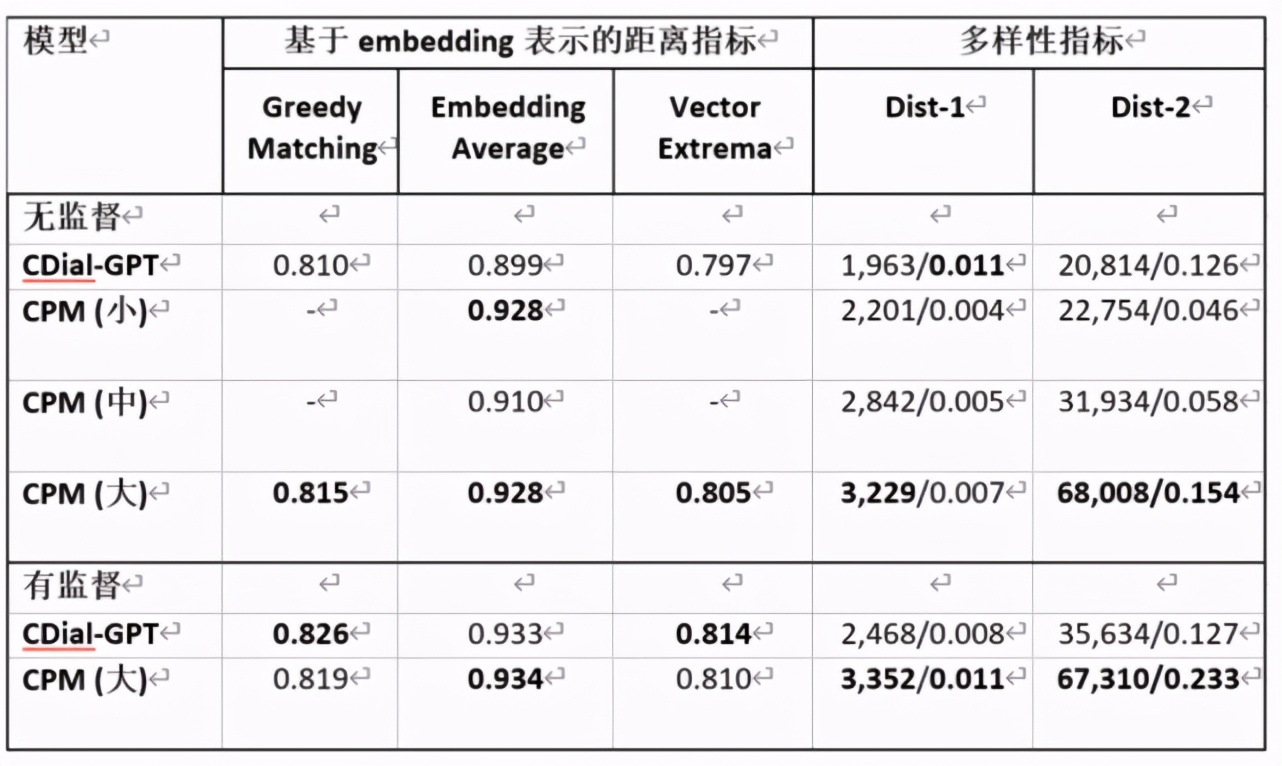
其中 CDial-GPT 是清華大學(xué)對話交互式人工智能(CoAI)實驗室 2020 年提出的中文對話預(yù)訓(xùn)練模型。用于衡量多樣性的 Dist-n 指標(biāo)的兩個數(shù)字分別是所有不重復(fù)的 N-Gram 的數(shù)量及占所有 N-Gram 的比例。可以看到,在無監(jiān)督的設(shè)定下,清源 CPM 具有更好的泛化性,在有監(jiān)督設(shè)定下,清源 CPM 能達(dá)到比 CDial-GPT 更優(yōu)的效果,尤其在多樣性指標(biāo)上表現(xiàn)更佳。
文本分類
清源 CPM 使用頭條新聞標(biāo)題分類(TNEWS,采樣為 4 分類)、IFLYTEK 應(yīng)用介紹分類(IFLYTEK,采樣為 4 分類)、中文自然語言推斷(OCNLI,3 分類)任務(wù)作為文本分類任務(wù)的基準(zhǔn)。具體做法是,先輸入分類樣本,再輸入「該文章的類別為 / 該介紹的類別為 / 兩句話的關(guān)系為」,要求模型直接生成標(biāo)簽,四個標(biāo)簽中概率最高的標(biāo)簽作為預(yù)測結(jié)果。在無監(jiān)督設(shè)定下,不同規(guī)模的清源 CPM 在文本分類任務(wù)上的精確度如下表所示:

清源 CPM 能夠在無監(jiān)督的設(shè)定下達(dá)到比隨機預(yù)測好得多的精確度(TNEWS/IFLYTEK/OCNLI 隨機預(yù)測精確度分別為 0.25/0.25/0.33)。
自動問答
CPM 使用 DuReader 和 CMRC2018 作為自動問答任務(wù)的基準(zhǔn),要求模型從給定段落中抽取一個片段作為對題目問題的答案,其中 DuReader 由百度搜索和百度知道兩部分?jǐn)?shù)據(jù)組成。在無監(jiān)督的設(shè)定下,不同規(guī)模的 CPM 模型的表現(xiàn)如下表所示:
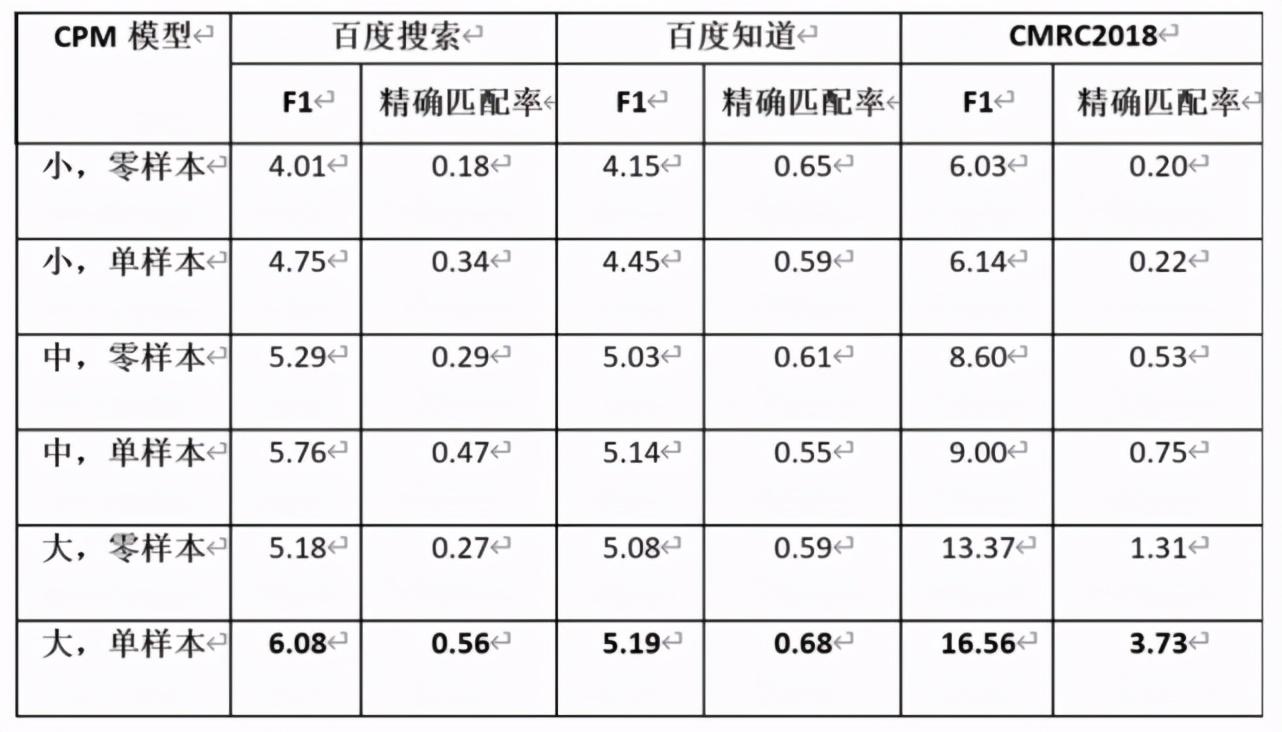
其中單樣本是指在測試時,從數(shù)據(jù)集中隨機抽取一個正確的「(段落,問題,答案)」三元組,插入到用于評價的樣例前,作為 CPM 模型生成答案的提示;零樣本是指直接使用 CPM 模型預(yù)測給定段落和問題的答案。在單樣本設(shè)定下,CPM 能從給定的樣本中學(xué)習(xí)到生成答案的模式,因此效果總是比零樣本設(shè)定更好。由于模型的輸入長度有限,多樣本輸入的場景將在未來進(jìn)行探索。
模型效果展示
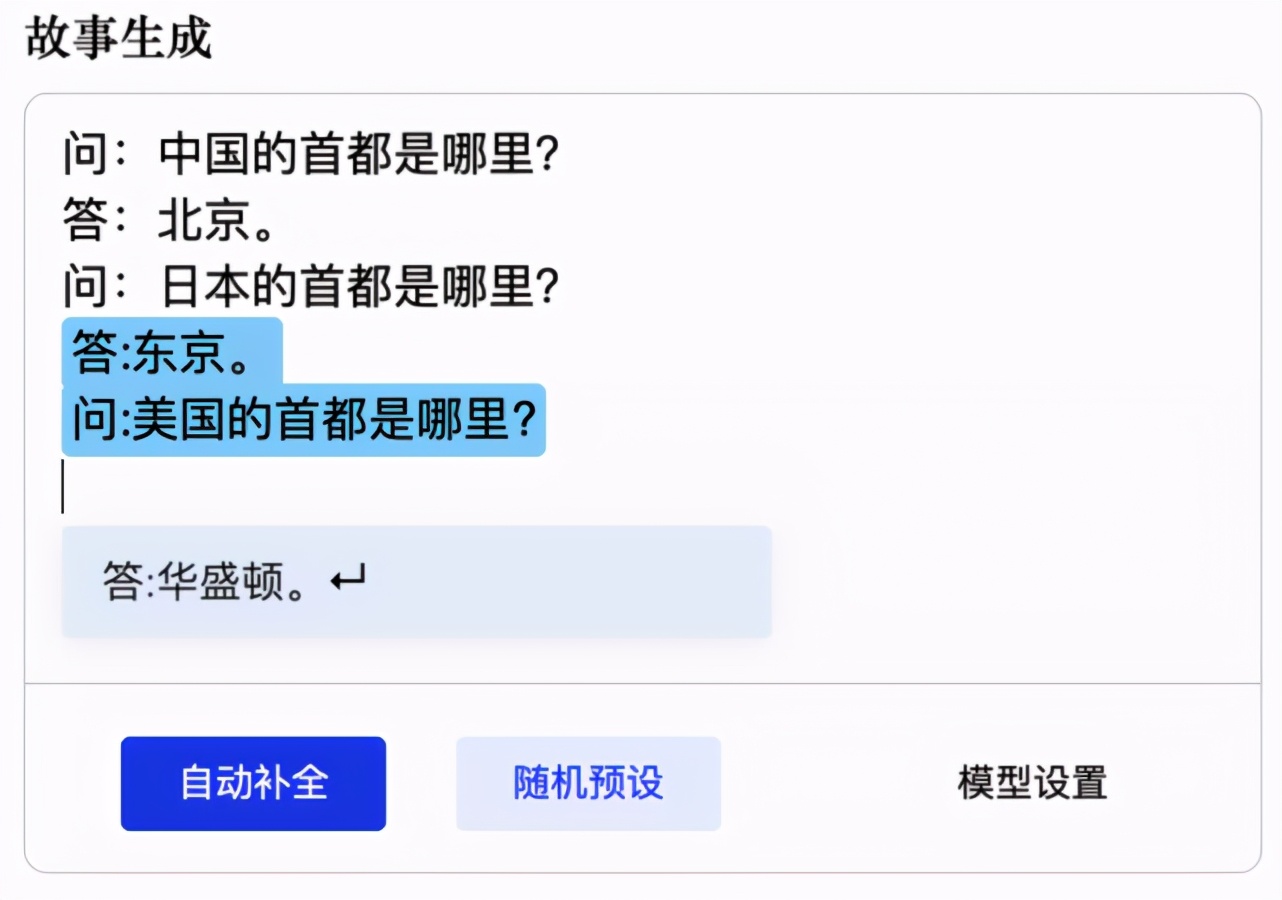
我們可以從以下示例中,觀察 CPM 預(yù)訓(xùn)練中文語言模型的效果。比如基于對單個常識性問題的學(xué)習(xí),依照規(guī)律進(jìn)行提問和正確回答:
根據(jù)前文真實的天氣預(yù)報,繼續(xù)報道天氣預(yù)報(不保證正確性):

執(zhí)行數(shù)理推理:

甚至續(xù)寫《紅樓夢》片段:

據(jù)了解,清源 CPM 未來計劃開源發(fā)布更大規(guī)模的預(yù)訓(xùn)練中文語言模型、以中文為核心的多語言預(yù)訓(xùn)練模型、融合大規(guī)模知識的預(yù)訓(xùn)練語言模型等。

























