PyTorch1.6:新增自動(dòng)混合精度訓(xùn)練、Windows版開發(fā)維護(hù)權(quán)移交微軟
剛剛,F(xiàn)acebook 通過 PyTorch 官方博客宣布:PyTorch 1.6 正式發(fā)布!新版本增加了一個(gè) amp 子模塊,支持本地自動(dòng)混合精度訓(xùn)練。Facebook 還表示,微軟已擴(kuò)大了對(duì) PyTorch 社區(qū)的參與,現(xiàn)在擁有 PyTorch 在 Windows 上的開發(fā)和維護(hù)所有權(quán)。
相比于以往的 PyTorch 版本,本次即將發(fā)布的 PyTorch 1.6 有哪些吸引人的地方呢?
總的來說,PyTorch 1.6 版本包括許多新的 API、用于性能改進(jìn)和性能分析的工具,以及對(duì)基于分布式數(shù)據(jù)并行(DDP)和遠(yuǎn)程過程調(diào)用(RPC)的分布式訓(xùn)練的重大更新。一些亮點(diǎn)包括:
在英偉達(dá)的幫助下增加了對(duì)自動(dòng)混合精度(AMP)訓(xùn)練的本地支持,并且具有穩(wěn)定的功能;
增加了對(duì) TensorPipe 的本地支持;
在前端 API 增加了對(duì)復(fù)雜張量的支持;
提供張量級(jí)內(nèi)存消耗信息的新分析工具;
分布式數(shù)據(jù)并行(DDP)訓(xùn)練和遠(yuǎn)程過程調(diào)用(RPC)包的大量改進(jìn)和新功能。
PyTorch 官方博客表示,從此版本開始,PyTorch 的特性將分為 Stable(穩(wěn)定版)、Beta(測(cè)試版)和 Prototype(原型版)。需要注意的是,Prototype 特性不包含在二進(jìn)制包中,但可以通過使用 Nightly 從源代碼構(gòu)建或通過編譯器標(biāo)志(compiler flag)來使用。
此外,F(xiàn)acebook 還宣布,他們將把 Windows 版 PyTorch 的開發(fā)維護(hù)權(quán)移交給微軟。
在 Windows 系統(tǒng)上運(yùn)行 PyTorch 一直都是一種不愉快的體驗(yàn),顯然微軟也看到了這一點(diǎn)。他們?cè)?Pytorch 的博客中表示:
「在 PyTorch 1.6 中,我們?yōu)楹诵?PyTorch 及其域庫提供了與 Linux 相同的測(cè)試覆蓋率,同時(shí)將教程測(cè)試自動(dòng)化,以此來改進(jìn) Windows 的核心質(zhì)量。在 PyTorch 社區(qū)的幫助下,我們將測(cè)試覆蓋范圍添加到三個(gè)域庫中:TorchVision、TorchText 和 TorchAudio。在 PyTorch 的后續(xù)版本中,我們將繼續(xù)改進(jìn)。根據(jù)收到的社區(qū)反饋,下一步的改進(jìn)方向應(yīng)該會(huì)聚焦于分布式訓(xùn)練支持和更好的 pip 安裝體驗(yàn)。」
除了本地 Windows 體驗(yàn),在今年的 Build 2020 大會(huì)上,微軟還宣布了一個(gè)為 WSL 提供 GPU 計(jì)算支持的計(jì)劃,PyTorch 將在其中起到不小的作用。現(xiàn)階段,WSL2 已獲得對(duì) GPU 的初始支持,其中就包含對(duì) PyTorch 的支持,WSL 用戶可以直接運(yùn)行本地 PyTorch 程序,進(jìn)行機(jī)器學(xué)習(xí),不需要傳統(tǒng)的虛擬機(jī)或雙引導(dǎo)設(shè)置。
性能與分析
[STABLE] 自動(dòng)混合精度(AMP)訓(xùn)練
AMP 使用戶可以輕松啟用自動(dòng)混合精度訓(xùn)練,從而在 Tensor Core GPU 上實(shí)現(xiàn)更高的性能并節(jié)省多達(dá) 50%的內(nèi)存。使用本地支持的 torch.cuda.amp API,AMP 為混合精度提供了方便的方法,其中某些運(yùn)算使用 torch.float32 (float)。其他運(yùn)算使用 torch.float16(half)。有些運(yùn)算,如線性層和卷積,在 float16 中要快得多。而另一些運(yùn)算,比如縮減,通常需要 float32 的動(dòng)態(tài)范圍。混合精度嘗試將每個(gè)運(yùn)算與其相應(yīng)的數(shù)據(jù)類型相匹配。
[BETA] FORK/JOIN 并行
新版本增加了對(duì)語言級(jí)構(gòu)造的支持,以及對(duì) TorchScript 代碼中粗粒度并行的運(yùn)行時(shí)的支持。這種支持對(duì)于一些情況非常有用,比如在集成中并行運(yùn)行模型,或者并行運(yùn)行循環(huán)網(wǎng)絡(luò)的雙向組件,它還允許為任務(wù)級(jí)并行釋放并行架構(gòu)(例如多核 CPU)的計(jì)算能力。
TorchScript 程序的并行執(zhí)行是通過 torch.jit.fork 和 torch.jit.wait 兩個(gè) primitive 實(shí)現(xiàn)的。下面的例子展示了 foo 的并行執(zhí)行:
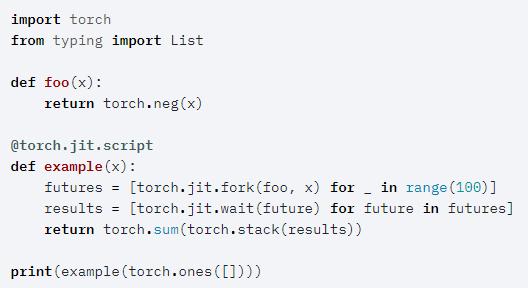
[BETA] 內(nèi)存分析器
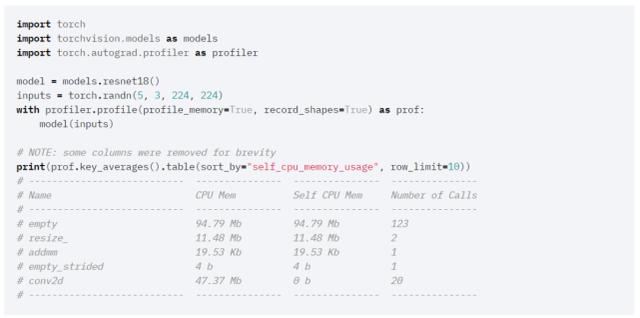
「torch.autograd.profiler」API 現(xiàn)在包含一個(gè)可以讓你檢查 CPU 和 GPU 模型內(nèi)不同算子的張量?jī)?nèi)存開銷的內(nèi)存分析器。
該 API 的用法如下所示:
分布式訓(xùn)練 & RPC
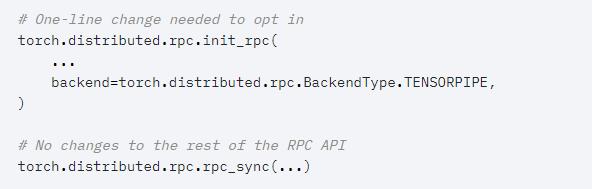
[BETA] 用于 RPC 的 TENSORPIPE 后端
PyTorch 1.6 為 RPC 模塊引入了一個(gè)新的后端,它利用了 TensorPipe 庫(一個(gè)針對(duì)機(jī)器學(xué)習(xí)的 tensor-aware 點(diǎn)對(duì)點(diǎn)通信 primitive,旨在補(bǔ)充 PyTorch 中分布式訓(xùn)練的現(xiàn)有 primitive)。TensorPipe 的成對(duì)和異步特性使其能夠應(yīng)用于數(shù)據(jù)并行之外的新的網(wǎng)絡(luò)范式:客戶端 - 服務(wù)器方法以及和模型和 pipeline 并行訓(xùn)練。
[BETA] DDP+RPC
PyTorch Distributed 支持兩種強(qiáng)大的范式:用于對(duì)模型進(jìn)行完全同步數(shù)據(jù)并行訓(xùn)練的 DDP 和支持分布式模型并行的 RPC 框架。在此之前,這兩個(gè)特性是獨(dú)立工作的,用戶不能混用它們來嘗試混合并行范式。
從 PyTorch 1.6 開始,該框架允許 DDP 和 RPC 無縫協(xié)作,這樣用戶就可以結(jié)合這兩種技術(shù)來實(shí)現(xiàn)數(shù)據(jù)并行和模型并行。

[BETA] RPC - 異步用戶函數(shù)
RPC 異步用戶函數(shù)( Asynchronous User Function)支持執(zhí)行用戶定義函數(shù)時(shí)在服務(wù)器端生成和恢復(fù)的能力。在此特性之前,當(dāng)被調(diào)用方處理請(qǐng)求時(shí),一個(gè) RPC 線程將一直等待,直到用戶函數(shù)返回。

前端 API 更新
[BETA] 復(fù)數(shù)
Pythorch1.6 版本提供了對(duì)復(fù)雜張量的 beta 級(jí)支持。包括 torch.complex64 和 torch.complex128 dtypes。
復(fù)數(shù)在數(shù)學(xué)和工程中經(jīng)常出現(xiàn),特別是在信號(hào)處理中,復(fù)值神經(jīng)網(wǎng)絡(luò)是一個(gè)活躍的研究領(lǐng)域。復(fù)張量的 beta 版將支持通用的 PyTorch 和復(fù)張量功能,以及 Torchaudio、ESPne 等所需的功能。
更新的域庫
TORCHVISION 0.7
torchvision 0.7 引入了兩個(gè)新的預(yù)訓(xùn)練語義分割模型,即 FCN ResNet50 和 DeepLabV3 ResNet50,它們都在 COCO 上進(jìn)行了訓(xùn)練,并且使用的內(nèi)存占用空間小于 ResNet101。此外還引入了 AMP(自動(dòng)混合精度),該功能可為不同的 GPU 運(yùn)算自動(dòng)選擇浮點(diǎn)精度,從而在保持精度的同時(shí)提高性能。
TORCHAUDIO 0.6
torchaudio 現(xiàn)在正式支持 Windows,微軟負(fù)責(zé) Windows 版本。此版本還引入了一個(gè)新模塊(包含 wav2letter)、若干新功能(contrast, cvm, dcshift, overdrive, vad, phaser, flanger, biquad)、新數(shù)據(jù)集(GTZAN,CMU)和一個(gè)新的可選 sox 后端,支持 TorchScript。