













全網最全-混合精度訓練原理
通常我們訓練神經網絡模型的時候默認使用的數據類型為單精度FP32。近年來,為了加快訓練時間、減少網絡訓練時候所占用的內存,并且保存訓練出來的模型精度持平的條件下,業界提出越來越多的混合精度訓練的方法。這里的混合精度訓練是指在訓練的過程中,同時使用單精度(FP32)和半精度(FP16)。
1、浮點數據類型
浮點數據類型主要分為雙精度(Fp64)、單精度(Fp32)、半精度(FP16)。在神經網絡模型的訓練過程中,一般默認采用單精度(FP32)浮點數據類型,來表示網絡模型權重和其他參數。在了解混合精度訓練之前,這里簡單了解浮點數據類型。
根據IEEE二進制浮點數算術標準(IEEE 754)的定義,浮點數據類型分為雙精度(Fp64)、單精度(Fp32)、半精度(FP16)三種,其中每一種都有三個不同的位來表示。FP64表示采用8個字節共64位,來進行的編碼存儲的一種數據類型;同理,FP32表示采用4個字節共32位來表示;FP16則是采用2字節共16位來表示。如圖所示:
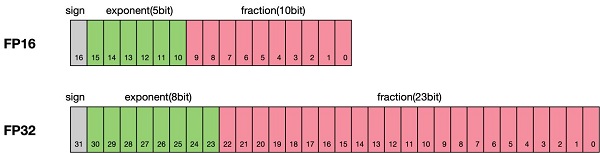
從圖中可以看出,與FP32相比,FP16的存儲空間是FP32的一半,FP32則是FP16的一半。主要分為三個部分:
最高位表示符號位sign bit。
中間表示指數位exponent bit。
低位表示分數位fraction bit。以FP16為例子,第一位符號位sign表示正負符號,接著5位表示指數exponent,最后10位表示分數fraction。公式為:
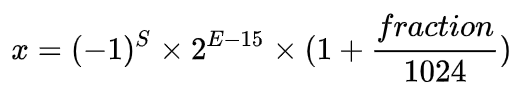
同理,一個規則化的FP32的真值為:
一個規格化的FP64的真值為:
FP16可以表示的最大值為 0 11110 1111111111,計算方法為:
FP16可以表示的最小值為 0 00001 0000000000,計算方法為:
因此FP16的最大取值范圍是[-65504 - 66504],能表示的精度范圍是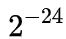 ,超過這個數值的數字會被直接置0。
,超過這個數值的數字會被直接置0。
2、使用FP16訓練問題
首先來看看為什么需要混合精度。使用FP16訓練神經網絡,相對比使用FP32帶來的優點有:
1.減少內存占用:FP16的位寬是FP32的一半,因此權重等參數所占用的內存也是原來的一半,節省下來的內存可以放更大的網絡模型或者使用更多的數據進行訓練。
2.加快通訊效率:針對分布式訓練,特別是在大模型訓練的過程中,通訊的開銷制約了網絡模型訓練的整體性能,通訊的位寬少了意味著可以提升通訊性能,減少等待時間,加快數據的流通。
3.計算效率更高:在特殊的AI加速芯片如華為Ascend 910和310系列,或者NVIDIA VOTAL架構的Titan V and Tesla V100的GPU上,使用FP16的執行運算性能比FP32更加快。
但是使用FP16同樣會帶來一些問題,其中最重要的是1)精度溢出和2)舍入誤差。
1.數據溢出:數據溢出比較好理解,FP16的有效數據表示范圍為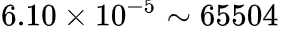 ,FP32的有效數據表示范圍為
,FP32的有效數據表示范圍為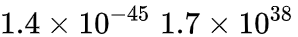 。可見FP16相比FP32的有效范圍要窄很多,使用FP16替換FP32會出現上溢(Overflow)和下溢(Underflow)的情況。而在深度學習中,需要計算網絡模型中權重的梯度(一階導數),因此梯度會比權重值更加小,往往容易出現下溢情況。
。可見FP16相比FP32的有效范圍要窄很多,使用FP16替換FP32會出現上溢(Overflow)和下溢(Underflow)的情況。而在深度學習中,需要計算網絡模型中權重的梯度(一階導數),因此梯度會比權重值更加小,往往容易出現下溢情況。
2.舍入誤差:Rounding Error指示是當網絡模型的反向梯度很小,一般FP32能夠表示,但是轉換到FP16會小于當前區間內的最小間隔,會導致數據溢出。如0.00006666666在FP32中能正常表示,轉換到FP16后會表示成為0.000067,不滿足FP16最小間隔的數會強制舍入。
3、混合精度相關技術
為了想讓深度學習訓練可以使用FP16的好處,又要避免精度溢出和舍入誤差。于是可以通過FP16和FP32的混合精度訓練(Mixed-Precision),混合精度訓練過程中可以引入權重備份(Weight Backup)、損失放大(Loss Scaling)、精度累加(Precision Accumulated)三種相關的技術。
3.1、權重備份(Weight Backup)
權重備份主要用于解決舍入誤差的問題。其主要思路是把神經網絡訓練過程中產生的激活activations、梯度 gradients、中間變量等數據,在訓練中都利用FP16來存儲,同時復制一份FP32的權重參數weights,用于訓練時候的更新。具體如下圖所示。
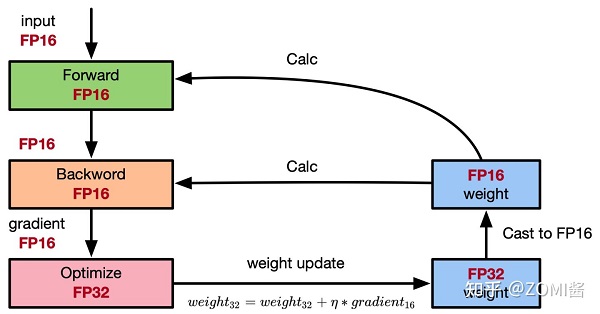
從圖中可以了解,在計算過程中所產生的權重weights,激活activations,梯度gradients等均使用 FP16 來進行存儲和計算,其中權重使用FP32額外進行備份。由于在更新權重公式為:
深度模型中,lr x gradent的參數值可能會非常小,利用FP16來進行相加的話,則很可能會出現舍入誤差問題,導致更新無效。因此通過將權重weights拷貝成FP32格式,并且確保整個更新過程是在 fp32 格式下進行的。即:
權重用FP32格式備份一次,那豈不是使得內存占用反而更高了呢?是的,額外拷貝一份weight的確增加了訓練時候內存的占用。 但是實際上,在訓練過程中內存中分為動態內存和靜態內容,其中動態內存是靜態內存的3-4倍,主要是中間變量值和激活activations的值。而這里備份的權重增加的主要是靜態內存。只要動態內存的值基本都是使用FP16來進行存儲,則最終模型與整網使用FP32進行訓練相比起來, 內存占用也基本能夠減半。
3.2、損失縮放(Loss Scaling)
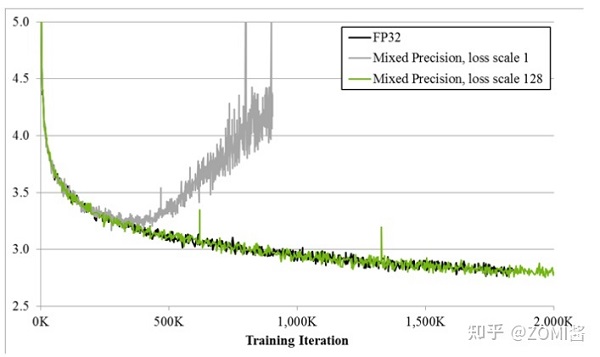
如圖所示,如果僅僅使用FP32訓練,模型收斂得比較好,但是如果用了混合精度訓練,會存在網絡模型無法收斂的情況。原因是梯度的值太小,使用FP16表示會造成了數據下溢出(Underflow)的問題,導致模型不收斂,如圖中灰色的部分。于是需要引入損失縮放(Loss Scaling)技術。
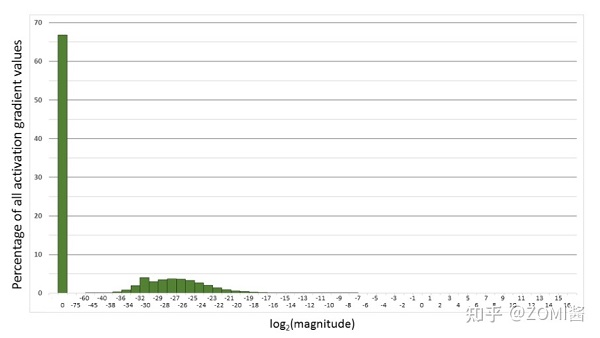
下面是在網絡模型訓練階段, 某一層的激活函數梯度分布式中,其中有68%的網絡模型激活參數位0,另外有4%的精度在2^-32~2^-20這個區間內,直接使用FP16對這里面的數據進行表示,會截斷下溢的數據,所有的梯度值都會變為0。
為了解決梯度過小數據下溢的問題,對前向計算出來的Loss值進行放大操作,也就是把FP32的參數乘以某一個因子系數后,把可能溢出的小數位數據往前移,平移到FP16能表示的數據范圍內。根據鏈式求導法則,放大Loss后會作用在反向傳播的每一層梯度,這樣比在每一層梯度上進行放大更加高效。
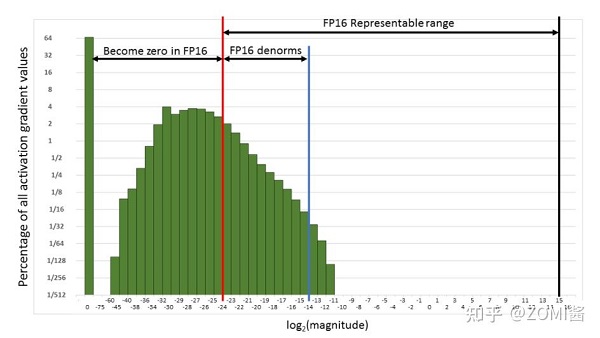
損失放大是需要結合混合精度實現的,其主要的主要思路是:
Scale up階段,網絡模型前向計算后在反響傳播前,將得到的損失變化值DLoss增大2^K倍。
Scale down階段,反向傳播后,將權重梯度縮2^K倍,恢復FP32值進行存儲。動態損失縮放(Dynamic Loss Scaling):上面提到的損失縮放都是使用一個默認值對損失值進行縮放,為了充分利用FP16的動態范圍,可以更好地緩解舍入誤差,盡量使用比較大的放大倍數。總結動態損失縮放算法,就是每當梯度溢出時候減少損失縮放規模,并且間歇性地嘗試增加損失規模,從而實現在不引起溢出的情況下使用最高損失縮放因子,更好地恢復精度。
動態損失縮放的算法如下:
動態損失縮放的算法會從比較高的縮放因子開始(如2^24),然后開始進行訓練迭代中檢查數是否會溢出(Infs/Nans);
如果沒有梯度溢出,則不進行縮放,繼續進行迭代;如果檢測到梯度溢出,則縮放因子會減半,重新確認梯度更新情況,直到數不產生溢出的范圍內;
在訓練的后期,loss已經趨近收斂穩定,梯度更新的幅度往往小了,這個時候可以允許更高的損失縮放因子來再次防止數據下溢。
因此,動態損失縮放算法會嘗試在每N(N=2000)次迭代將損失縮放增加F倍數,然后執行步驟2檢查是否溢出。
3.3、精度累加(Precision Accumulated)
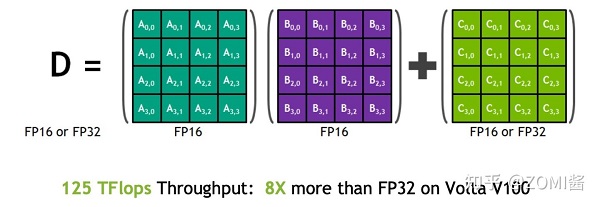
在混合精度的模型訓練過程中,使用FP16進行矩陣乘法運算,利用FP32來進行矩陣乘法中間的累加(accumulated),然后再將FP32的值轉化為FP16進行存儲。簡單而言,就是利用FP16進行矩陣相乘,利用FP32來進行加法計算彌補丟失的精度。 這樣可以有效減少計算過程中的舍入誤差,盡量減緩精度損失的問題。
例如在Nvidia Volta 結構中帶有Tensor Core,可以利用FP16混合精度來進行加速,還能保持精度。Tensor Core主要用于實現FP16的矩陣相乘,在利用FP16或者FP32進行累加和存儲。在累加階段能夠使用FP32大幅減少混合精度訓練的精度損失。
4、混合精度訓練策略(Automatic Mixed Precision,AMP)
混合精度訓練有很多有意思的地方,不僅僅是在深度學習,另外在HPC的迭代計算場景下,從迭代的開始、迭代中期和迭代后期,都可以使用不同的混合精度策略來提升訓練性能的同時保證計算的精度。以動態的混合精度達到計算和內存的最高效率比也是一個較為前言的研究方向。
以NVIDIA的APEX混合精度庫為例,里面提供了4種策略,分別是默認使用FP32進行訓練的O0,只優化前向計算部分O1、除梯度更新部分以外都使用混合精度的O2和使用FP16進行訓練的O3。具體如圖所示。
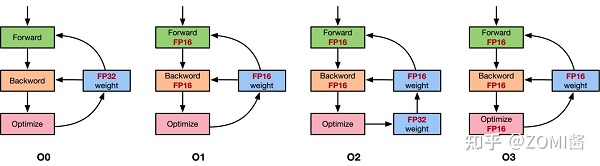
這里面比較有意思的是O1和O2策略。
O1策略中,會根據實際Tensor和Ops之間的關系建立黑白名單來使用FP16。例如GEMM和CNN卷積操作對于FP16操作特別友好的計算,會把輸入的數據和權重轉換成FP16進行運算,而softmax、batchnorm等標量和向量在FP32操作好的計算,則是繼續使用FP32進行運算,另外還提供了動態損失縮放(dynamic loss scaling)。
而O2策略中,模型權重參數會轉化為FP16,輸入的網絡模型參數也轉換為FP16,Batchnorms使用FP32,另外模型權重文件復制一份FP32用于跟優化器更新梯度保持一致都是FP32,另外還提供動態損失縮放(dynamic loss scaling)。使用了權重備份來減少舍入誤差和使用損失縮放來避免數據溢出。
當然上面提供的策略是跟硬件有關系,并不是所有的AI加速芯片都使用,這時候針對自研的AI芯片,需要找到適合得到混合精度策略。
5、實驗結果
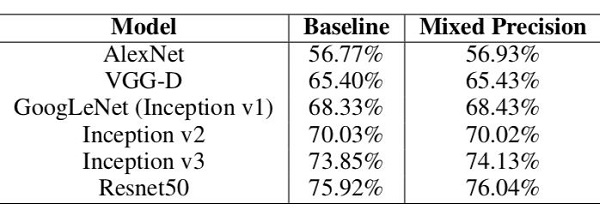
從下圖的Accuracy結果可以看到,混合精度基本沒有精度損失:
Loss scale的效果:

題外話,前不久去X公司跟X總監聊下一代AI芯片架構的時候,他認為下一代芯片可以不需要加入INT8數據類型,因為Transformer結構目前有大一統NLP和CV等領域的趨勢,從設計、流片到量產,2年后預計Transformer會取代CNN成為最流行的架構。我倒是不同意這個觀點,目前來看神經網絡的4個主要的結構MLP、CNN、RNN、Transformer都有其對應的使用場景,并沒有因為某一種結構的出現而推翻以前的結構。只能說根據使用場景的側重點比例有所不同,我理解Int8、fp16、fp32的數據類型在AI芯片中仍然會長期存在,針對不同的應用場景和計算單元會有不同的比例。
參考文獻:
Micikevicius, Paulius, et al. "Mixed precision training."arXiv preprint arXiv:1710.03740(2017).
Ott, Myle, et al. "Scaling neural machine translation."arXiv preprint arXiv:1806.00187(2018).
https://en.wikipedia.org/wiki/Half-precision_floating-point_format
apex.amp - Apex 0.1.0 documentation.
Automatic Mixed Precision for Deep Learning.
Training With Mixed Precision.
Dreaming.O:淺談混合精度訓練.


























