為MoE解綁:全新「專家即服務」推理架構發布,超細粒度擴展銳減37.5%成本
本文第一作者劉子銘為新加坡國立大學三年級博士生,本科畢業于北京大學,研究方向為機器學習系統中的并行推理與訓練效率優化。通信作者為上海創智學院馮思遠老師和新加坡國立大學尤洋老師。共同作者來自于上海奇績智峰智能科技有限公司,北京基流科技有限公司等。
近年來,大型語言模型的參數規模屢創新高,隨之而來的推理開銷也呈指數級增長。如何降低超大模型的推理成本,成為業界關注的焦點之一。Mixture-of-Experts (MoE,混合專家) 架構通過引入大量 “專家” 子模型,讓每個輸入僅激活少數專家,從而在參數規模激增的同時避免推理計算量同比增長。這一稀疏激活策略使模型能擴展到數萬億參數規模,但也給推理系統帶來了新的挑戰:
- 擴展性差:現有主流 MoE 推理框架大多要求使用大規模同步通信組來部署模型,一次性占用大量 GPU 資源,使彈性資源伸縮變得十分困難。這種粗粒度伸縮方式導致資源供給無法嚴格按照當前用戶流量進行調整,只能按整塊單元增加或減少,造成資源浪費。
- 容錯性低:傳統 MoE 推理采用全局緊耦合架構,各 GPU 間通過 All-to-All 等大規模集體通信協同工作。在這種高度依賴統一通信組的設計下,任意一個節點故障都可能迫使整個服務集群重啟,導致服務中斷。也就是說,系統缺乏容錯能力,一處故障即全局崩潰。
- 負載不均:MoE 中的專家調用是動態稀疏的,哪個專家被激活取決于輸入內容,在不同的工作負載下被激活的分布有很大區別。固定的專家映射和資源分配策略難以適應這種波動。某些專家所在 GPU 因頻繁命中而過載,而其他專家節點長期閑置,造成資源利用低下。
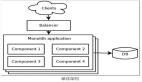
通過觀察,作者發現這些問題其實有共同的根本原因:整個系統被當作一個龐大的 “有狀態整體” 去管理。事實上,專家層本質上是無狀態的,它對輸入執行純函數計算,不依賴歷史上下文。作者利用這一特性,將專家層的計算抽象為獨立的無狀態服務,與維護 KV 緩存的 Attention 前端解耦部署。盡管近期也有研究嘗試解耦 Attention 層與專家層、按不同組件拆分部署,但仍未根本解決伸縮僵化、大規模容錯等問題。為此,本文作者提出了一種全新的 MoE 模型推理系統 ——Expert-as-a-Service (EaaS),旨在通過架構層面的創新來提升大規模 MoE 推理的效率、擴展性和魯棒性。

方法

EaaS 的 “專家即服務” 的架構轉變,使 MoE 推理能夠像微服務一樣靈活調度。在這一前提下,作者對系統進行了如下設計:
- 專家服務化、無狀態設計:EaaS 將每個專家拆分成獨立服務模塊,專家不維護會話狀態,僅根據請求計算輸出。Attention 層(客戶端)通過 gating 動態選取需要調用的專家服務。由于專家之間相互獨立,整個模型不再是一個龐大的緊耦合應用,而是由許多可獨立擴展的服務組成,為精細擴展奠定基礎。在這種架構下,模型初始部署規模可以很小(例如 16 塊 GPU 起步),可以一次增加 / 減少一塊 GPU 來精確匹配負載需求。

EaaS 專家服務器的動態批處理機制。
- 解耦 Attention 層與專家層:在傳統架構中,Attention 計算和專家計算放置在同一組計算節點內,而 EaaS 將 Attention 客戶端與專家服務端職責解耦開來,二者通過高效通信機制銜接。這樣一方面減少了全局同步點,Attention 端可以異步等待專家結果,同時著手處理下一批次計算,從而提升流水線利用率;另一方面 Attention 和專家可以獨立擴展,互不影響,突破了傳統架構中必須同步擴容的限制。

EaaS 利用 InfiniBand GPUDirect Async (IBGDA) 來實現低通信延遲,并通過完全 CUDA graph 捕獲來最小化內核啟動開銷,從而實現無 CPU 控制的通信。
- 高性能異步通信 (IBGDA):為支撐上述解耦架構,EaaS 研發了定制的無通信組、非對稱、異步點對點通信庫。該庫基于 InfiniBand GPUDirect Async (IBGDA) 技術,實現了 GPU 直連網絡的通信模式,完全繞過 CPU 參與。具體來說,GPU 可以直接通過 InfiniBand 網卡收發數據,不需經由 CPU 協調。此外,該通信庫支持單邊 RDMA 操作和靈活的緩沖管理,不要求通信雙方對稱協同,突破了 NCCL 和 NVSHMEM 等通信庫需整組同步的限制。借助 IBGDA 通信,EaaS 實現了真正的 CPU-free 數據傳輸:網絡通信由 GPU 主動驅動,能夠與 CUDA Graph 等機制結合,將整個端到端計算過程封裝為單一調度單元,最大程度減少通信對計算流水線的干擾。
- 動態負載均衡:由于專家服務彼此獨立,EaaS 可以方便地引入實時負載均衡策略。例如,當監測到某個專家被請求的頻率過高(“熱” 專家)時,系統可動態增添該專家服務的實例來分攤流量;反之對于長期 “冷門” 的專家,可減少其實例以節省資源。

- 容錯與故障恢復機制:EaaS 通過客戶端 - 服務端的松耦合通信取代了集體通信,天然具備更強的容錯性。系統設置了一個中央監控組件,實時追蹤各實例健康狀態。當某個專家服務發生故障停止響應時,通知相關的 Attention 客戶端自動切換到該專家的其他可用實例繼續服務,無需重建全局通信組。同樣地,如果某個 Attention 客戶端節點故障,其他客戶端不會直接中斷,新客戶端加入也不會擾亂正在運行的專家服務。
實驗
論文通過一系列大規模實驗,利用端到端的 benchmark 對比了 EaaS 與當前主流 MoE 推理方案(如 SGLang + DeepEP、vLLM + DeepEP 以及 SGLang + TP 等組合)的性能,在擴展性和容錯等方面展現出 EaaS 的優勢。

- 擴展能力:在隨請求密度進行擴展(也即弱擴展)的實驗中,隨著 GPU 節點數從 32 增加到 64,EaaS 的總吞吐量幾乎按比例提升。同時,EaaS 打破了傳統架構對 GPU 數量整除比的要求。使用傳統專家并行的系統只能在 GPU 數量是既定專家總數因子的情況下擴容,而 EaaS 由于專家服務松耦合,支持任意數量 GPU 的部署組合,可以細粒度地按需增減算力。這意味著云服務商可以靈活地為 MoE 模型調配資源,例如在負載下降時將推理集群從 64 GPU 縮減到 40 GPU 仍保持同等吞吐。實驗顯示,與靜態架構相比,EaaS 能夠實現同等性能下最高約 37.5% 的 GPU 資源節省。

- 容錯與魯棒性:在模擬故障場景中,EaaS 展現出卓越的服務連續性。當實驗中隨機失效 GPU 節點時,EaaS 幾乎不中斷地完成了請求處理,吞吐量僅略微下降不到 2%。相比之下,采用 DeepEP 等傳統方案的系統由于所有解碼 GPU 綁定在單一通信組內,任一節點故障都會使整個組停止服務,無法在故障期間繼續推理。EaaS 中有故障的專家請求被即時路由到備用副本處理,客戶端自身故障也被其他實例接管,整個服務保持了高可用性。

- 高吞吐與低延遲兼顧:在端到端推理吞吐量上,EaaS 與現有最優系統表現相當,能夠達到媲美 SOTA 的生成速度。同時,EaaS 在響應延遲上保持穩定,得益于高效通信與動態資源調配,能將每個 token 的平均生成延遲維持在較低水平。整體評估顯示,EaaS 在吞吐 - 延遲權衡上達到優秀平衡,在保證用戶響應及時性的同時提供了強勁的處理能力。
 1 對 3 往返通信平均延遲
1 對 3 往返通信平均延遲

2 對 2 往返通信平均延遲
除此以外,作者也將 EaaS 的通信庫與當前開源的 Step3 中 StepMesh 使用的通信庫進行了 torch 側調用從端到端的延遲比較,并發現在對稱與非對稱的場景下,EaaS 的通信庫通過 IBGDA 本身的高效通信模式與僅 CPU-free 的結構支持的 CUDA graph 帶來的 kernel launch 開銷的 overlap,最多將延遲降低了 49.6%。
總結
面向未來,EaaS 展現出在云端大模型推理和模型即服務(MaaS)等場景中的巨大潛力。其細粒度的資源調配能力意味著云服務提供商可以根據實時負載彈性地調整 MoE 模型的算力分配,從而以更低的成本提供穩定可靠的模型推理服務。這種按需伸縮、平滑容錯的設計非常契合云計算環境下的多租戶和持續交付需求。另一方面,EaaS 的服務化架構具有良好的可運營和可演化特性:模塊化的專家服務便于獨立升級和維護,通信調度組件也可以逐步優化迭代,從而使整套系統能夠隨著模型規模和應用需求的變化不斷演進。