譯者 | 核子可樂
審校 | 重樓
引言
隨著機器學習模型在眾多應用領域的蓬勃發展,AI對于海量用戶數據的依賴度也隨之提升,進而引發人們對于隱私及信息安全的擔憂。行業如今面臨著雙重挑戰:既要構建高精度模型,又須避免泄露敏感數據。傳統的集中數據收集方式存在明顯風險,即使是最安全的服務器也可能成為攻擊者、監管機構及訴訟的指向目標。
隱私保護機器學習(PPML)技術,特別是聯邦學習(FL)與差分隱私(DP),為這些相互交織的挑戰提供了有力支持。聯邦學習避免了原始數據過于集中,差分隱私則有助于量化并限制模型輸出造成的隱私外泄。兩者相結合,有望在不犧牲模型性能的前提下帶來強大的隱私保護效果。
下面我們將從技術運作方式、常見陷阱、先進方法以及相關代碼片段等層面,共同了解其核心概念。
聯邦學習:模型訓練的范式性轉變
概述
傳統集中機器學習強調將數據聚合至單一存儲庫,并據此訓練模型。這種方法雖簡單卻風險極高:單一數據聚合點可能成為攻擊目標。而聯邦學習則通過訓練流程的去中心化解決這一難題。
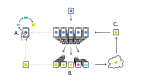
在聯邦學習中,數據駐留在用戶本地設備上,模型通過通信迭代進行訓練。在每輪迭代中,全局模型都將被發送至一組設備,利用設備中駐留的本地數據集進行訓練。這樣中央服務器上聚合的就永遠是最新的全局模型,而非原始數據。這種將數據存儲與模型訓練相互解耦的方式,顯著降低了數據泄露風險,提高了數據保護合規水平。
聯邦學習的技術流程
- 初始模型廣播:服務器與指定的客戶端共享初始全局模型。
- 本地訓練:各客戶端使用本地數據執行多步驟訓練。
- 更新聚合:客戶端將模型更新(參數增量)發回服務器,再由服務器聚合更新以生成新的全局模型。
- 迭代:此過程重復進行,直到模型收斂或達到性能目標。
聯邦學習的挑戰
- 統計異質性:用戶數據并非獨立同分布(IID,指一組隨機變量既相互獨立又服從同一概率分布)。不同設備間的分布可能差異巨大,導致模型更新沖突。可使用FedProx或Scaffold等專項聚合方法,在非獨立同分布環境下實現穩定訓練。
- 通信開銷:聯邦學習需要在客戶端與服務器間頻繁交換模型參數。可使用壓縮、量化、稀疏更新等技術降低通信成本。
- 隱私與安全:盡管聯邦學習減少了原始數據的直接傳輸,但單憑它并不足以保證強大的隱私保護。模型更新本身可能會泄露敏感信息,因此需要采取差分隱私等額外隱私保護措施。
差分隱私:量化隱私保障
基礎概念
差分隱私(DP)提供一套數學框架,可保證攻擊者無法從模型輸出中推斷特定個人信息。簡單講,差分隱私確保數據集中任何個人數據的存在與否不會顯著改變模型輸出的分布。
通過在計算過程中引入精心校準的噪聲(如梯度、模型參數或匯總統計數據),差分隱私能夠掩蓋任何單條記錄的明顯影響。
關鍵要素
- 隨機化響應:差分隱私的基本形式是以概率方式翻轉答案,提高對特定數據點是否存在的判斷難度。
- 拉普拉斯與高斯機制:這些機制能夠從特定概率分布中提取校準噪聲并添加至輸出中。噪聲幅度經過調整以保證差分隱私的預算維持在特定區間間,通常用ε表示,用于量化可承受的隱私損失。
- 模型訓練中的差分隱私:在模型訓練期間,可通過在梯度聚合前剪切梯度并添加噪聲的方式強勢實施差分隱私,確保沒有任何單一數據點對最終模型造成顯著影響。
隱私與實用間的權衡
差分隱私面臨的最大挑戰,在于如何在隱私與實用間尋求平衡。隱私保障更強,往往需要添加更多噪聲,而這很可能降低模型準確率。研究人員已經開發出自適應噪聲添加、隱私核算與訓練流程優化技術,最大限度將二者維持在最佳平衡。
將差化隱私融入聯邦學習
將聯邦學習與差分隱私相結合,即可形成強大的解決方案,在多個層面保護隱私。聯邦學習確保原始數據永不離開客戶端,差分隱私則確保聚合后的模型更新也可受到隱私保護。
目前常見的實現方式,是在將本地更新發送回服務器前,先對其應用差分隱私。如此一來,最終聚合模型就能夠保留差分隱私帶來的保護效果。
如何將差分隱私融入聯邦學習
- 梯度剪切:由各客戶端剪切其本地梯度,確保任何單一梯度更新均不超過預定義的閾值,借此防止異常梯度主導更新、也防止稀有或特定數據點泄露。
- 添加噪聲:剪切后,添加根據所需隱私預算校準的噪聲。噪聲指標決定了隱私保障的強度。
- 隱私核算:跟蹤多輪累積的隱私預算,可使用Momnets Accountant等技術確保重復訓練迭代不致過早耗盡隱私預算。
實際考量因素與工具
框架和庫
- TensorFlow Federated (TFF): 提供用于去中心化訓練的構建模型,且包含用于集成差分隱私的基礎機制。
- PySyft: 用于安全及隱私機器學習的Python庫,支持聯邦學習、安全多方計算(SMPC)與差分隱私集成。
- Opacus (for PyTorch): 用于將差分隱私引入模型訓練。盡管最初并非專為聯邦學習設計,但可通過在客戶端更新中應用差分隱私的方式被整合進聯邦管線當中。
示例代碼
以下是高度簡化的聯邦學習與差分隱私概念集成演示,雖無法直接支持生產級應用,但足以在概念上提供啟發。
聯邦均值(無差分隱私):
import numpy as np
# Assume global_model is a NumPy array of parameters
# local_updates is a list of parameter updates from clients
def federated_averaging(global_model, local_updates):
# local_updates is a list of parameter arrays, one per client
update_sum = np.zeros_like(global_model)
for update in local_updates:
update_sum += update
new_model = global_model + (update_sum / len(local_updates))
return new_model
# Example usage:
global_model = np.zeros(10) # Dummy model of 10 parameters
local_updates = [np.random.randn(10) for _ in range(5)]
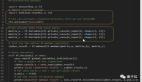
global_model = federated_averaging(global_model, local_updates)為客戶端添加差分隱私:
import numpy as np
def add_dp_noise(update, clip_norm=1.0, noise_scale=0.1):
# Clip
norm = np.linalg.norm(update)
if norm > clip_norm:
update = (update / norm) * clip_norm
# Add noise
noise = np.random.normal(0, noise_scale, size=update.shape)
return update + noise
# Example usage:
client_update = np.random.randn(10)
dp_client_update = add_dp_noise(client_update, clip_norm=2.0, noise_scale=0.5)在實際應用中,各客戶端在將更新發送至服務器前會先應用add_dp_noise。之后,服務器會聚合帶有這些噪聲的更新,進而生成一套差分隱私全局模型。
新興趨勢與研究方向
- 安全聚合:盡管添加了噪聲,服務器仍可觀察到客戶端更新。安全的多方計算協議(如安全聚合)可確保服務器無法獲取單一更新,而只能獲取其總和。將安全聚合與差分隱私相結合,即可提供更強大的隱私保障。
- 用差分隱私實現個性化聯邦模型:現有聯邦模型往往只提供單一全局模型。個性化技術可根據各客戶端的局部分布調整全局模型。未來的研究可將差分隱私集成至個性化算法中,確保個性化步驟不致泄露隱私信息。
- 自適應隱私預算:靜態隱私預算可能并非最優。自適應機制可在整個訓練過程中調整噪聲指標,或動態為模型中的不同部分分配不同預算,進一步改善隱私與實效間的平衡。
總結
隨著機器學習模型與敏感應用的深度融入,隱私保護已經成為一種實踐奢求。聯邦學習與差分隱私提供兩款互補工具:前者通過分布式訓練盡量減少原始數據暴露,后者則提供可量化的隱私保障以抵御推理攻擊。
通過將二者相結合,同時引入安全聚合及基于硬件的安全保護等先進技術,組織可以在不損害用戶隱私的前提下構建高精度模型。隨著這些技術的成熟,我們期待看到更廣泛的應用、更明確的監管指引、蓬勃發展的工具與融合最佳實踐的生態系統,真正讓隱私保護始終在AI創新中得到關注。
原文標題:Enhancing AI Privacy: Federated Learning and Differential Privacy in Machine Learning,作者:Shaurya Jain