













隱私保護新突破:高斯差分隱私框架與深度學(xué)習(xí)結(jié)合
人工智能中的隱私問題已經(jīng)公認(rèn)為一個重要并且嚴(yán)肅的問題。近日,賓夕法尼亞大學(xué)的研究組開發(fā)了一個新的數(shù)據(jù)隱私分析框架,可以在多個類型的機器學(xué)習(xí)問題中有效保護個人隱私。這個框架現(xiàn)已成功和深度學(xué)習(xí)結(jié)合,并在多個需要保障隱私的深度學(xué)習(xí)任務(wù)中達到最高準(zhǔn)確率。
什么是差分隱私
在這個大數(shù)據(jù)時代,如何妥善獲取和使用與真人相關(guān)的數(shù)據(jù),漸漸成為迫切需要解決的問題。沒有人希望自己生個病,上個網(wǎng),買件衣服都會被人隨意知曉,更別提手機里沒有修過的自拍了。一種簡單的隱私保護方法就是「匿名」:將收集到的數(shù)據(jù)中涉及個人信息的特征剔除。可惜這種方法并不可靠,曾有研究將 Netflix 匿名處理過的觀影記錄通過交叉對比 IMDb 數(shù)據(jù)庫解匿成功,這直接導(dǎo)致了第二屆 Netflix 數(shù)據(jù)分析大獎賽的取消。
2006 年,隱私算法的研究迎來了新的里程碑。Cynthia Dwork, Frank McSherry, Kobbi Nissim 和 Adam Smith 四位科學(xué)家定義了「差分隱私」(以下縮寫為 DP),來嚴(yán)謹(jǐn)?shù)胤治鲭[私這個概念。差分隱私很快被證明是個強有效的工具,并被谷歌、蘋果、微軟、阿里巴巴等各大機構(gòu)使用。而四位發(fā)明者于 2017 年獲得了被譽為理論計算機科學(xué)界諾貝爾獎的 Godel 獎。
要理解差分隱私,我們可以看看下面這個簡單的假設(shè)檢驗:假設(shè)有兩個數(shù)據(jù)集 S, S'
S={小明,小剛,小美};S'={小紅,小剛,小美}
我們說這兩個數(shù)據(jù)集是鄰近的,因為它們的差異僅體現(xiàn)在一個人上。我們的目的是檢驗我們的模型是否是基于 S 訓(xùn)練的,這等價于檢驗小明是否存在于我們的數(shù)據(jù)中。如果這個假設(shè)檢驗非常困難,那么想要獲取小明信息的攻擊者就難以得逞。嚴(yán)謹(jǐn)來說,一個隨機算法 M 符合 (epsilon,delta)-DP 意味著對于任何的事件 E,
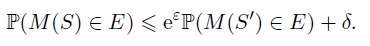
從定義不難看出,epsilon 和 delta 越小,隱私性越好。那么,如何實現(xiàn)能保證算法的隱私性呢?
具體做法是衡量算法的中間產(chǎn)物(比如梯度)的敏感性,并根據(jù)其大小施加一個成正比的噪音。由于噪音的存在,想要竊取小明信息的攻擊者便無法確定小明是否在訓(xùn)練集中。在深度神經(jīng)網(wǎng)絡(luò)中,每一次迭代都會犧牲一部分隱私來換取性能的提高。我們可以對每個批(batch)的梯度加噪音,從而達到混淆攻擊者的目的。

當(dāng)然,噪音加的越大,隱私就越安全,但是隨之性能也自然越差。在有限的隱私預(yù)算下,很多時候隱私算法的性能表現(xiàn)會不如人意。
深度學(xué)習(xí)經(jīng)常需要敏感的個人信息來訓(xùn)練。現(xiàn)存的差分隱私定義以及隱私模型都試圖在性能和隱私中找到一個平衡。可惜的是,這些嘗試仍不能很好的處理兩個重要環(huán)節(jié):subsampling 和 composition。這導(dǎo)致了隱私算法的性能通常遠遜于非隱私算法。
高斯差分隱私
Gaussian differential privacy (GDP) 是最近被提出的一種隱私表示方法。它可以精確的刻畫 optimizer 在每個 epoch 所消耗的隱私。GDP 的表達簡潔且是廣義的(在 SGD, Adam, Adagrad 等多個優(yōu)化器上的刻畫是完全一樣的)。GDP 的分析被進一步推廣到 Poisson subsampling 和新的優(yōu)化器上。新的推廣得到了理論上嚴(yán)謹(jǐn)?shù)淖C明,尤其證明了它優(yōu)于此前最先進的 Moments accountant 方法。
在《Gaussian Differential Privacy》一文中,賓夕法尼亞大學(xué)的董金碩、Aaron Roth 和蘇煒杰創(chuàng)新性地定義了「f-DP」來刻畫隱私。如果用 alpha 來表示第一類錯誤,beta 來表示第二類錯誤,對于任何一種拒絕規(guī)則 (rejection rule) phi,都存在一個抵換函數(shù) (trade-off function) T:降低第一類錯誤會導(dǎo)致第二類錯誤增加,反之亦然。我們將兩類錯誤的和的最小值稱為最小錯誤和。
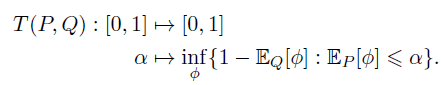
一個隨機算法 M 在 S 和 S』上的抵換函數(shù) T 如果始終大于函數(shù) f,那么它就滿足 f-DP。
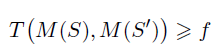
對比于傳統(tǒng)的 eps,delta-DP,f-DP 使用的是一個函數(shù) f,這也使得其刻畫更為自由和準(zhǔn)確。
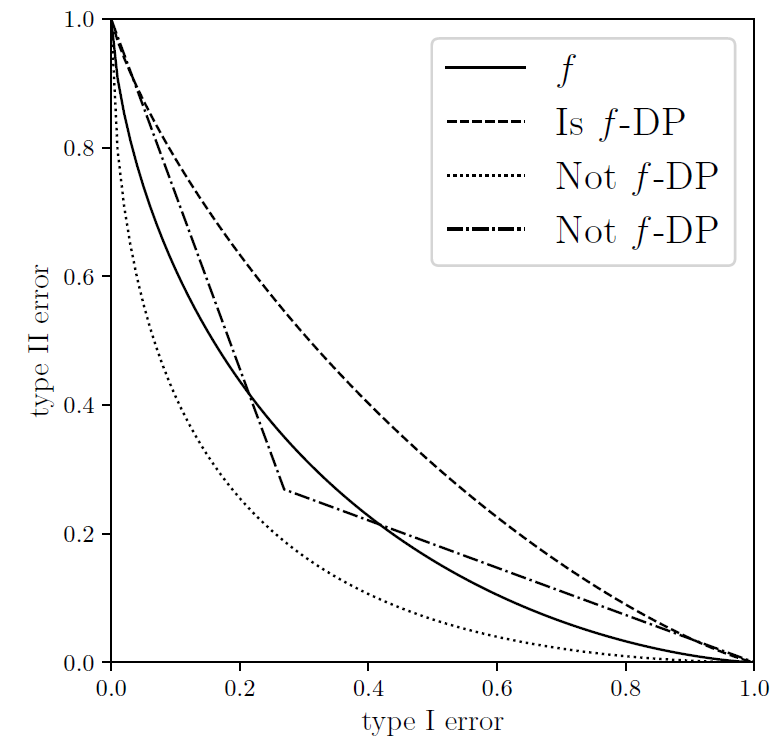
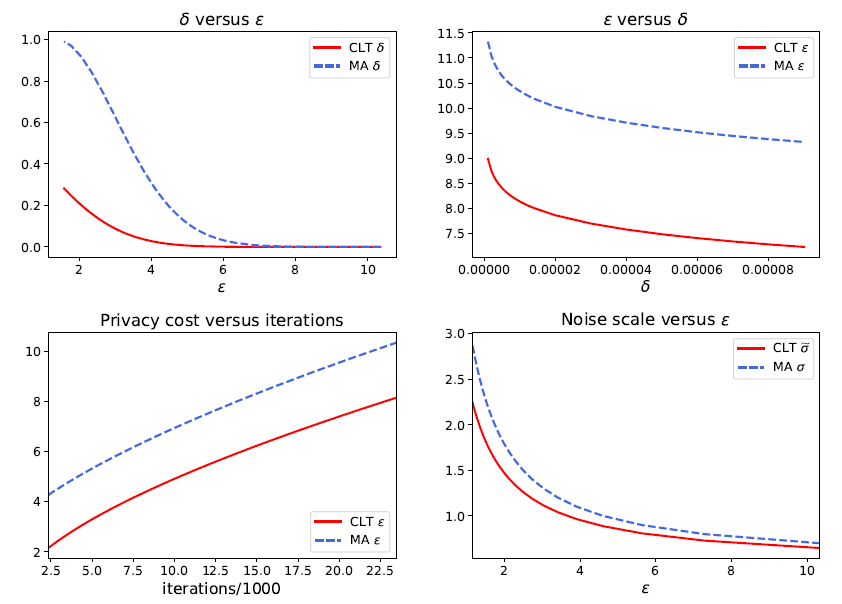
作為 f-DP 的一個重要案例,作者隨后介紹了高斯差分隱私(GDP)來區(qū)分兩個高斯分布。根據(jù)中心極限定理(CLT),任何基于假設(shè)檢驗的隱私定義在極限情況下都會收斂于 GDP。事實上,相對于谷歌在 2016 年提出的,適用于計算 epsilon,delta-DP 的 Moments Accountant (MA) 方法,本文提出的 CLT 方法可以更簡易地計算 GDP,而且非常準(zhǔn)確。值得注意的是,該文章最近被國際頂級統(tǒng)計學(xué)雜志 Journal of the Royal Statistical Society: Series B 接收為 Discussion paper,這是數(shù)據(jù)科學(xué)界對該工作的一種認(rèn)可。
GDP 與深度學(xué)習(xí)的結(jié)合
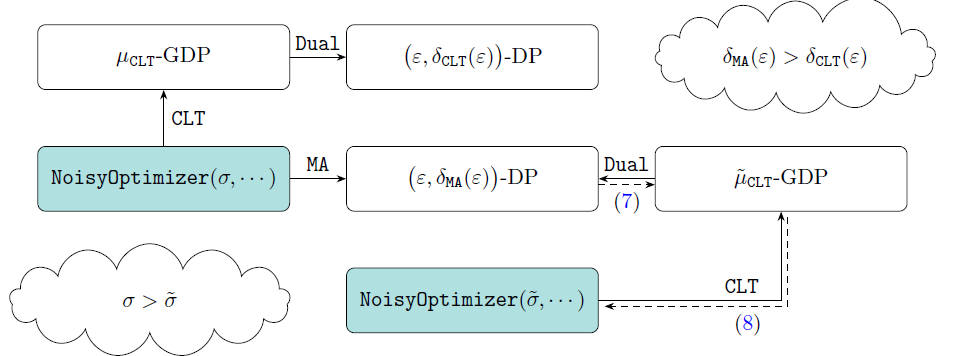
GDP 的好處還不止于此。在最新工作《Deep Learning with Gaussian Differential Privacy》中,卜至祺、董金碩,龍琦和蘇煒杰等作者指出 GDP 和 eps,delta-DP 可以通過他們設(shè)計的 Dual 函數(shù)互相轉(zhuǎn)換。也就是說,研究者可以在 f-DP 的框架下分析算法再轉(zhuǎn)成傳統(tǒng)的 dp,或者從傳統(tǒng)領(lǐng)域中拿來已有的理論和技巧,不必二次開發(fā)。這項技術(shù)現(xiàn)在已經(jīng)在 TensorFlow 中實現(xiàn)。
- 論文地址:https://arxiv.org/abs/1911.11607
- 項目實現(xiàn):https://github.com/tensorflow/privacy/blob/master/tensorflow_privacy/privacy/analysis/gdp_accountant.py
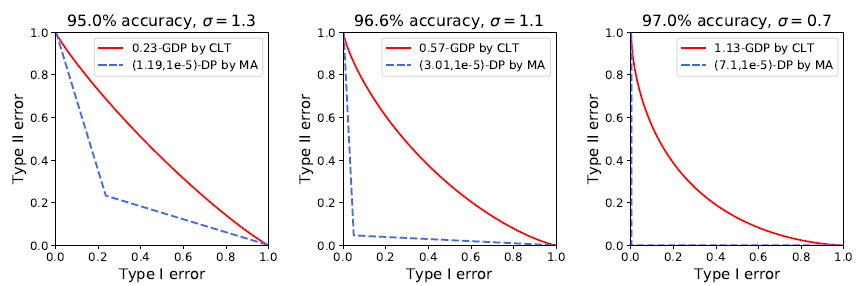
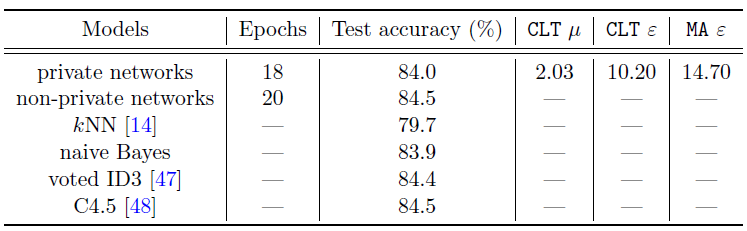
在實驗中,作者們將 GDP 和深度學(xué)習(xí)結(jié)合,并在多種類型的任務(wù)上取得了不俗的成績。此前谷歌也曾將 epsDP 和深度學(xué)習(xí)結(jié)合,雖然在 MNIST 圖像識別上取得了 97% 的正確率(無隱私算法可達到 99% 以上),在 CIFAR10 上卻止步于 73% 的正確率(無隱私算法可達 86%)。而利用 GDP 的精確刻畫,作者們在 MNIST 上取得了 98% 的準(zhǔn)確率。不僅如此,MA 計算的結(jié)果表示 MNIST 的 96.6% 正確率對應(yīng)的是 9.4% 的最小錯誤和,意味著攻擊者有超過九成的概率猜對一張圖片是否在數(shù)據(jù)集中。而 CLT 的計算表明 epsDP 太過于保守:同樣的模型同樣的表現(xiàn),實際對應(yīng)的最小錯誤和其實是 77.6%,也就是說隱私并沒有損失很多。
為了全面探討 GDP 的優(yōu)越性,作者在 GDP 框架下分析了神經(jīng)網(wǎng)絡(luò)的表現(xiàn)。作者實現(xiàn)了 SGD 和 Adam 的隱私版本,并通過讓神經(jīng)網(wǎng)絡(luò)不斷迭代直到 GDP 達到了 mu=2。在 IMDb(自然語言處理),MovieLens 1M(推薦系統(tǒng))和 Adult Income(非圖像型分類任務(wù))上,GDP 模型都取得了非常接近無隱私模型的性能。例如在 Adult Income 數(shù)據(jù)上,隱私神經(jīng)網(wǎng)絡(luò)和無隱私神經(jīng)網(wǎng)絡(luò)表現(xiàn)幾乎一樣好,意味著隱私也許并不需要以很大的性能犧牲為代價。更進一步的,作者強調(diào)文中的神經(jīng)網(wǎng)絡(luò)都相對簡單(不超過三層),如果使用更復(fù)雜更高級的神經(jīng)網(wǎng)絡(luò)可以在同樣的隱私保證下更顯著地提升性能。而另一方面,使用高效的優(yōu)化算法(減少迭代次數(shù),即隱私的損失次數(shù))也能讓性能變得更好。
既然 CLT 可以在同樣性能的條件下比 MA 更好地保護隱私,那么反過來想,在同樣的隱私預(yù)算下,GDP 也能顯示出更強的性能。作者構(gòu)思了一個實驗來說明這一點:訓(xùn)練一個加了 sigma 噪音的神經(jīng)網(wǎng)絡(luò)若干步,通過 MA 可以算出目前損失了多少隱私,通過 CLT 和 Dual 反解出真正必須的噪音 sigma hat。注意 sigma hat 必然小于 sigma,然后訓(xùn)練同一個神經(jīng)網(wǎng)絡(luò)但只加 sigma hat 噪音。由于噪音變小,新的神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)效果會更好,而且在每一次迭代,新神經(jīng)網(wǎng)絡(luò)都會更好地保護隱私。
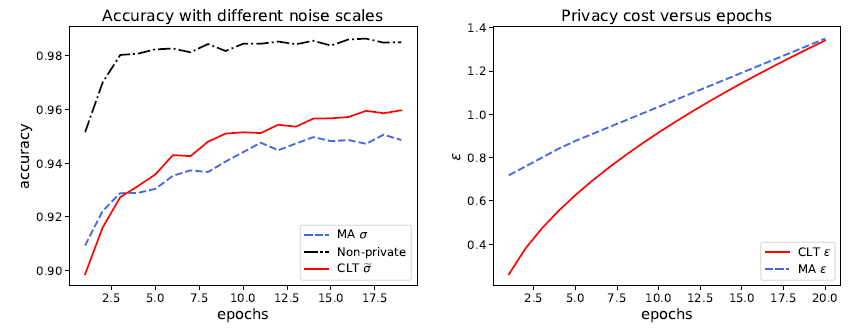
將神經(jīng)網(wǎng)絡(luò)和 GDP 結(jié)合,可以更精準(zhǔn)地呈現(xiàn)隱私損失,從而更好地保護隱私以及提升隱私算法的性能。另一方面,已有的 (epsilon,delta)-DP 研究也可以嫁接到 GDP 中,為兩個領(lǐng)域帶來了新的機遇。這一隱私算法領(lǐng)域的新進展給予了研究者們更大的信心去相信,隨著機器學(xué)習(xí)的進一步發(fā)展,我們也許在不遠的未來就能以可忽略不計的代價來保護我們的隱私。同時,它也鼓勵人們更愿意分享涉及個人信息的數(shù)據(jù),來推動機器學(xué)習(xí)的發(fā)展。






















