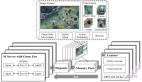
只要科學任務能打分,AI就能實現SOTA結果 | 谷歌最新論文
只要科學任務可以評分,AI就能找到超越人類專家的方法,實現SOTA結果?
這是谷歌一篇最新論文里的內容:
使用大模型+樹搜索,讓AI大海撈針就行。
他們還開發了一個幫助科學家編寫專家級實證軟件的AI系統。
該系統在生物信息學、流行病學、地理空間分析等領域發明的新方法,都達到了SOTA的水平。

網友表示:任何可量化的東西都將被AI征服。

這篇論文目前在X上獲得了2.6K贊,引發了廣泛的討論。
讓我們一起看看。

可評分任務在科學中無處不在
實證軟件指的是以最大化可定義或可度量的質量指標(通常指對現有觀測數據的擬合度)為設計目標的軟件。
如果一個任務可以用實證軟件解決,就可以被稱為可評分任務。
論文表示,他們構建這個系統主要是基于兩個原因:
一方面,可評分任務在科學界無處不在。如今幾乎每個科學子領域、應用數學和工程領域都依賴軟件,其中大部分軟件都是解決可量化任務的實證軟件。
另一方面,科學實證軟件的開發過程緩慢且艱難。特定領域的實證軟件需要繁瑣的工作,通常需要數年才能完成。

而這個新系統能夠系統地自動創建實證軟件,以解決可評分任務。
簡單地說,該方法基于大語言模型(LLM),通過讓LLM重寫代碼來提升軟件的質量評分。系統首先生成大量的候選軟件解決方案,然后運用樹搜索算法篩選值得進一步優化的候選方案。

雖然代碼變異系統的設計方式多樣,但研究人員通過設計基于基礎Kaggle競賽基準的對抗測試,持續改進了該方法。

研究人員通過注入研究思想來增強代碼變異能力——這些思想來源廣泛,涵蓋從高被引論文、專業教科書到搜索引擎結果等多個渠道。
在實際應用中,用戶既可直接注入這些思想,也可通過搜索引擎自動獲取文獻研究成果。
LLMs在代碼編寫過程中會充分利用這些注入的指導信息。

結果顯示,該系統可廣泛應用于科學領域的各類可評分任務,生成的軟件性能超越了科學家開發的最先進水平。
這種超人類性能的實現,源于系統能夠在前所未有的規模上、徹底且不知疲倦地進行解決方案搜索,從而發現“滄海遺珠”式的高質量解決方案。
在生物信息學領域,這個新系統發現了40種用于單細胞數據分析的新方法,在公開排行榜上超越了人類專家開發的最頂尖方法。

在地理空間分析方法上,系統開發出的三個新方法在DLRSD基準測試上顯著優于近期學術論文報道的結果,mIoU指標均突破0.80大關。

在神經科學領域,斑馬魚活動預測基準(ZAPBench)上,該系統的解決方案有效地利用了跨神經元信息來生成預測,雖然沒有超過表現最好的視頻模型,但它與時序基線模型相比仍然具有競爭力,并且在訓練速度上比表現最佳的視頻模型快幾個數量級。
(這個基準Y軸越低越好)
此外,在流行病學、時間序列預測、數值分析領域,新系統都能取得和人類頂級方法相當、甚至超越人類的結果。
總而言之,研究團隊開發了一種新方法:把基于樹搜索的代碼變異系統和整合復雜研究思路的能力相結合。
這些研究思路可以來自已發表的論文、研究智能體,也可以是LLM已有思路和方案的組合。
網友評價:這種新方法正在為未來的AI創造更好的算法。



但同樣的,問題也隨之而來:把科學研究的權限交給AI真的合適么?



頂尖的AI研究員也像我們一樣使用提示
有細心的網友發現,在這篇論文里,研究人員使用的提示詞和我們也沒什么差別:
請創建一個算法,利用兩種策略的優點,創建一個真正出色的混合策略,并且得分要高于任何一種單獨的策略!!

全都用的都是大寫字母,和中文里瘋狂敲感嘆號沒什么差別。
網友笑評:就像答辯的前一周,簡直火燒眉毛了。


也有網友表示這是一個很好的現象。它證明好結果并不總是需要復雜的指令,能夠清晰表達需求就足夠有效。


創造力才是進步的核心。