單一ViT模型執(zhí)行多模態(tài)多任務(wù),谷歌用協(xié)同訓練策略實現(xiàn)多個SOTA
Transformer 真的很全能。
Transformers 是一個靈活的神經(jīng)端到端模型族(family),最開始是為自然語言處理任務(wù)設(shè)計的。近來,Transformers 已經(jīng)在圖像分類、視頻和音頻等一系列感知任務(wù)上得到應用。雖然近來在不同領(lǐng)域和任務(wù)上取得了進展,但當前 SOTA 方法只能為手頭的每個任務(wù)訓練具有不同參數(shù)的單一模型。
近日,谷歌研究院、劍橋大學和阿蘭 · 圖靈研究所的幾位研究者在其論文《 PolyViT: Co-training Vision Transformers on Images, Videos and Audio 》提出了一種簡單高效的訓練單個統(tǒng)一模型的方法,他們將該模型命名為 PolyViT,它實現(xiàn)了有競爭力或 SOTA 的圖像、視頻和音頻分類結(jié)果。
在設(shè)計上,研究者不僅為不同的模態(tài)使用一個通用架構(gòu),還在不同的任務(wù)和模態(tài)中共享模型參數(shù),從而實現(xiàn)了潛在協(xié)同作用。從技術(shù)上來講,他們的方法受到了「transformer 是能夠在任何可以 tokenized 的模態(tài)上運行的通用架構(gòu)」這一事實的啟發(fā);從直覺上來講,是由于人類感知在本質(zhì)上是多模態(tài)的,并由單個大腦執(zhí)行。

論文地址:https://arxiv.org/abs/2111.12993
下圖 1 為 PolyViT 的結(jié)構(gòu)概覽。
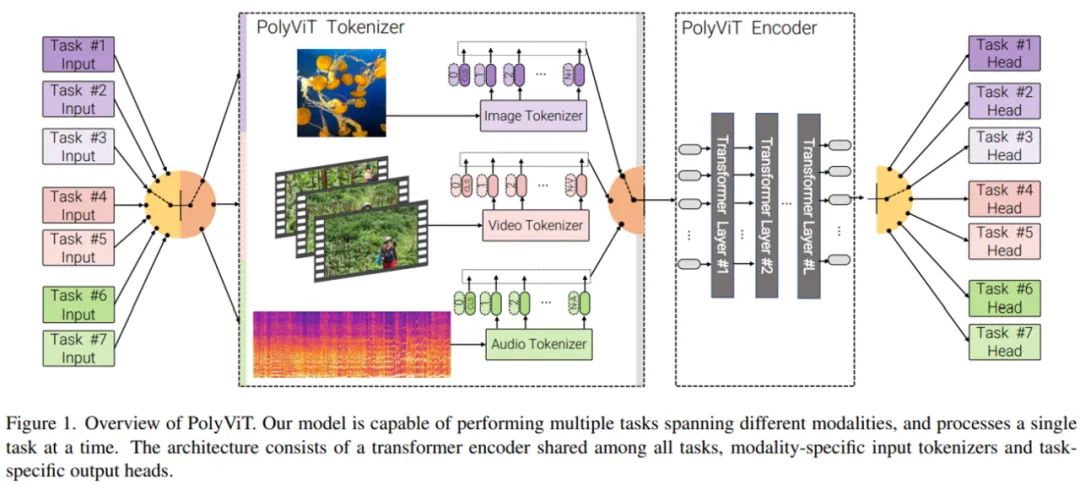
研究者主要使用的方法是協(xié)同訓練(co-training),即同時在多個分類任務(wù)(可能跨多個模態(tài))上訓練單個模型。他們考慮了不同的設(shè)置,同時解決多達 9 個不同的圖像、視頻和音頻分類任務(wù)。如上圖 1 所示,PolyViT 模型能夠執(zhí)行多個任務(wù),但對于給定的輸入一次只能執(zhí)行一個任務(wù)。雖然計算機視覺和自然語言領(lǐng)域探索過類似的方法,但研究者不清楚以往的工作是否考慮了多種模態(tài)以及是否使用這種方法實現(xiàn)了 SOTA 結(jié)果。
我們的協(xié)同訓練設(shè)置簡單實用。它不需要對協(xié)同訓練數(shù)據(jù)集的每個組合進行超參數(shù)調(diào)整,因為我們可以很容易地調(diào)整標準單任務(wù)訓練的設(shè)置。此外,協(xié)同訓練也不會增加整體訓練成本,因為訓練步驟的總數(shù)不超過每個單任務(wù)基線的總和。
圖像、音頻和視頻上的 Co-training ViT
PolyViT 架構(gòu)
PolyViT 是一個能夠處理來自多種模態(tài)的輸入的單一架構(gòu)。如上圖 1 所示,研究者在不同的任務(wù)和模態(tài)中共享一個 transformer 編碼器,使得參數(shù)隨任務(wù)數(shù)量呈線性減少。注意,在處理圖像時,具有 L 個層的 PolyViT 表現(xiàn)得像 L 層的 ViT,處理音頻時表現(xiàn)得像 L 層的 AST,處理視頻時表現(xiàn)得像 L 層的未因式分解(unfactorized)的 ViViT。雖然 PolyViT 能夠處理多種模態(tài),但在給定前向傳遞時只能基于一種模態(tài)執(zhí)行一個任務(wù)。
PolyViT 部署模態(tài)特定的類 token,即
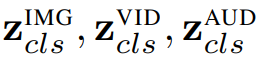
輸入嵌入算子
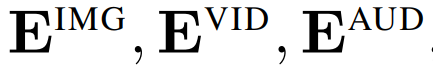
和位置嵌入
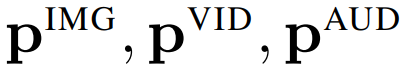
這使得網(wǎng)絡(luò)可以編碼模態(tài)特定的信息,這些信息又可以被隨后的、共享 transformer 主干所利用。
為了實現(xiàn)大量任務(wù)和模態(tài)協(xié)同訓練的同時增加模型容量,研究者可以選擇性地納入 L_adapt ≥ 0 模態(tài)特定 transformer 層(他們表示為模態(tài) - 適配器層),這些 transformer 層在 tokenization 之后直接應用。在這種情況下,所有模態(tài)和任務(wù)中會共享 L_=shared = L − L_adapt 層。
協(xié)同訓練流程
在使用隨機梯度下降(SGD)協(xié)同訓練的所有任務(wù)中,研究者同時優(yōu)化所有的 PolyViT 模型參數(shù) θ。因此,在決定如何構(gòu)建訓練 batch、計算梯度以更新模型參數(shù)以及使用哪些訓練超參數(shù)時有很多設(shè)計上的選擇。
在所有情況下,研究者使用來自單個任務(wù)中的示例來構(gòu)建自己的訓練 minibatch。這一設(shè)計選擇使得他們在使用相同的訓練超參數(shù)(如學習率、batch 大小和動量)作為傳統(tǒng)單一任務(wù)基線時,可以評估梯度和更新參數(shù)。這樣一來,與單一任務(wù)基線相比,研究者無需任何額外的超參數(shù)就可以執(zhí)行多個任務(wù)上的協(xié)同訓練,從而使得協(xié)同訓練在實踐中易于執(zhí)行,并減少執(zhí)行大規(guī)模超參數(shù)掃描(sweep)的需求以實現(xiàn)具有競爭力的準確性。
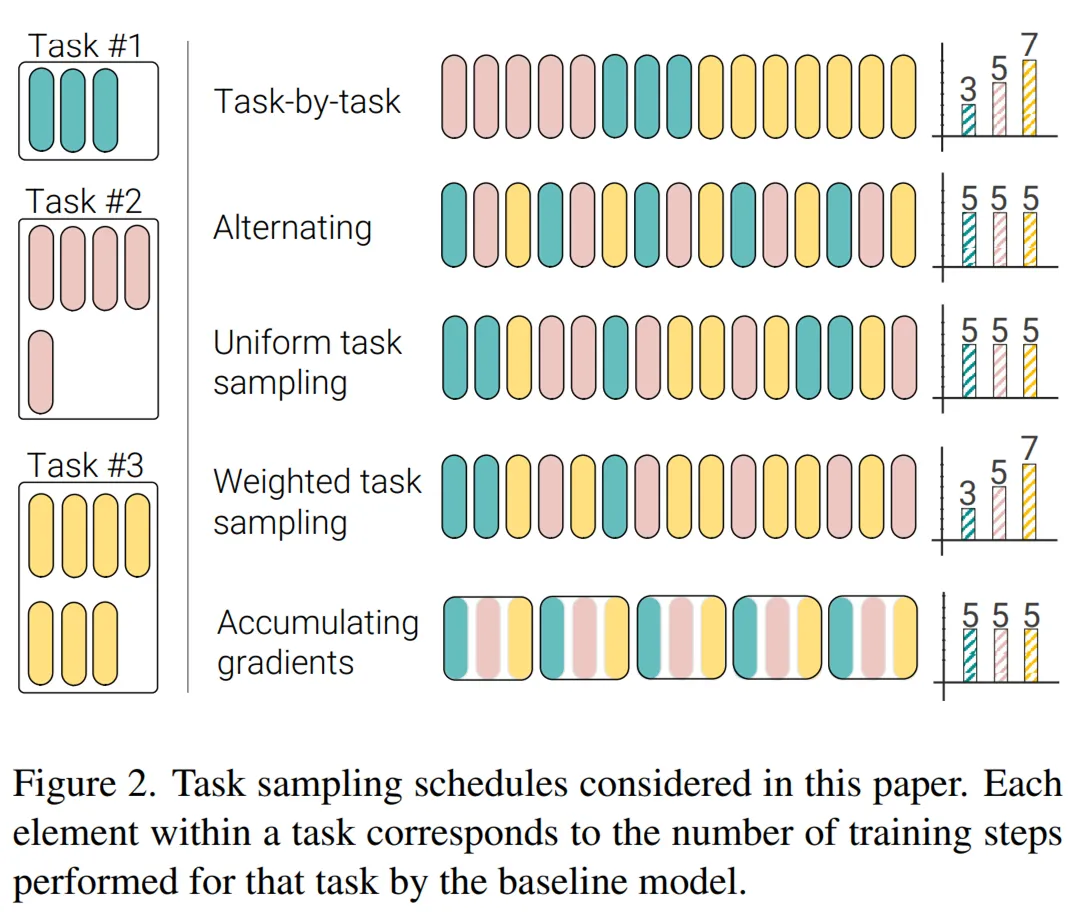
在協(xié)同訓練過程中,對于每個 SGD 步,研究者采樣一個任務(wù)(或數(shù)據(jù)集),然后采樣來自這個任務(wù)中的 minibatch,評估梯度并隨后執(zhí)行參數(shù)更新。需要著重考慮的是采樣任務(wù)的順序以及是否在不同的 minibatch 和任務(wù)上累積梯度。研究者在下圖 2 中描述了幾個任務(wù)采樣計劃,包括如下:
- 任務(wù) 1:逐任務(wù)(Task-by-task)
- 任務(wù) 2:交替(Alternating)
- 任務(wù) 3:統(tǒng)一任務(wù)采樣(Uniform task sampling)
- 任務(wù) 4:加權(quán)任務(wù)采樣(Weighted task sampling)
- 任務(wù) 5:累積梯度(Accumulating gradients)
實驗
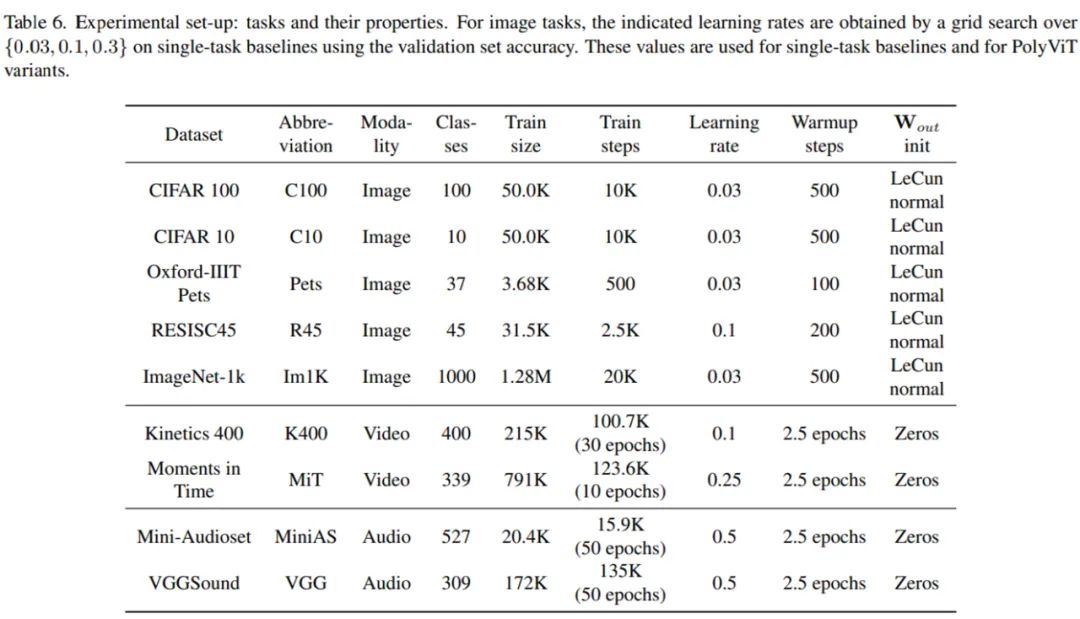
研究者在圖像、音頻和視頻三種模態(tài)的 9 個不同分類任務(wù)上同時訓練了 PolyViT。在圖像分類協(xié)同訓練時,他們使用了 ImageNet-1K、 CIFAR-10/100、Oxford-IIIT Pets 和 RESISC45 數(shù)據(jù)集;對于視頻任務(wù),他們使用了 Kinetics 400 和 Moments in Time 數(shù)據(jù)集;對于音頻任務(wù),他們使用了 AudioSet 和 VGGSound 數(shù)據(jù)集。
下表 6 為具體實驗設(shè)置:
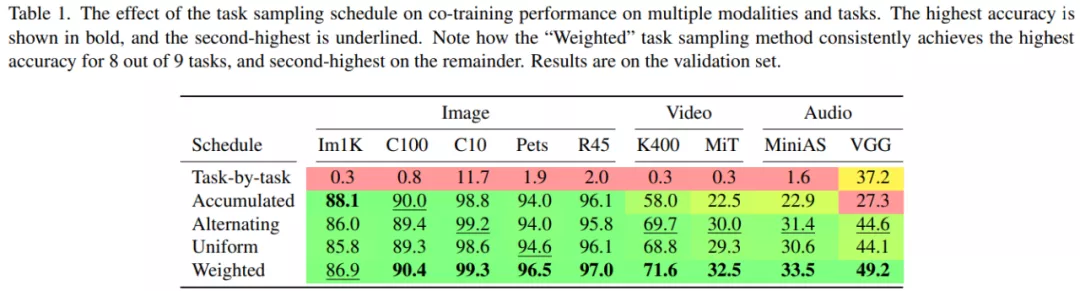
下表 1 展示了不同任務(wù)采樣計劃在不同模態(tài)和任務(wù)上對協(xié)同訓練性能的影響,粗體表示最高準確率,下劃線表示次最高準確率。其中,「Task-by-task」采樣計劃表現(xiàn)糟糕,僅在一項任務(wù)上實現(xiàn)了不錯的性能,這是災難性遺忘(catastrophic forgetting)造成的。
「Accumulated」采樣計劃需要在所有任務(wù)上使用單一的學習率,這是由于所有任務(wù)上的累積梯度被用于執(zhí)行參數(shù)更新。因此,該計劃僅在圖像數(shù)據(jù)集上表現(xiàn)良好。
「Alternating」、「Uniform」和「Weighted」采樣計劃表現(xiàn)最好,表明任務(wù)特定的學習率以及不同任務(wù)的梯度更新之間的轉(zhuǎn)換對于準確率至關(guān)重要。
使用 PolyViT 的協(xié)同訓練
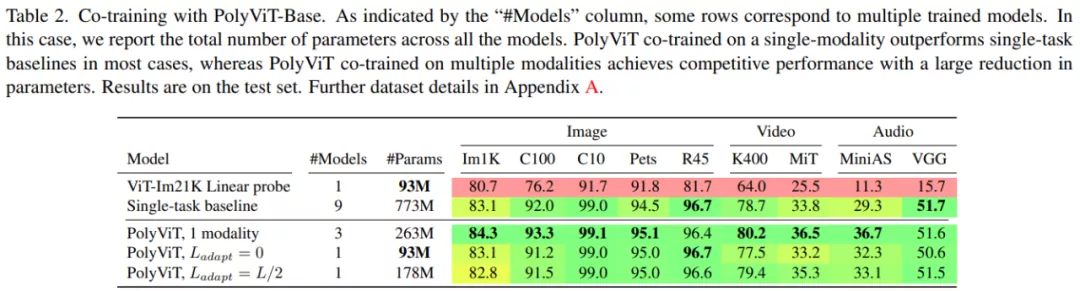
下表 2 展示了用于解決跨圖像、音頻和視頻三種模態(tài)的 9 個不同任務(wù)的模型訓練方法,包括 ViT-Im21K Linear probe、Single-task baseline 和本文的 PolyViT 及變體(分別是 PolyViT L_adapt = 0 和 PolyViT Ladapt = L/2)。
結(jié)果顯示,在單模態(tài)上訓練的 PolyViT 在 9 個數(shù)據(jù)集的 7 個上實現(xiàn)了 SOTA 性能,其余 2 個數(shù)據(jù)集上的準確率差異可以忽略不計,不超過 0.3%。此外,參數(shù)的總數(shù)量比單個任務(wù)基線少了 2/3。同時,在使用參數(shù)大大減少的情況下,多模態(tài) PolyViT 也實現(xiàn)了有競爭力的性能。
使用 linear probe 評估學習到的表示
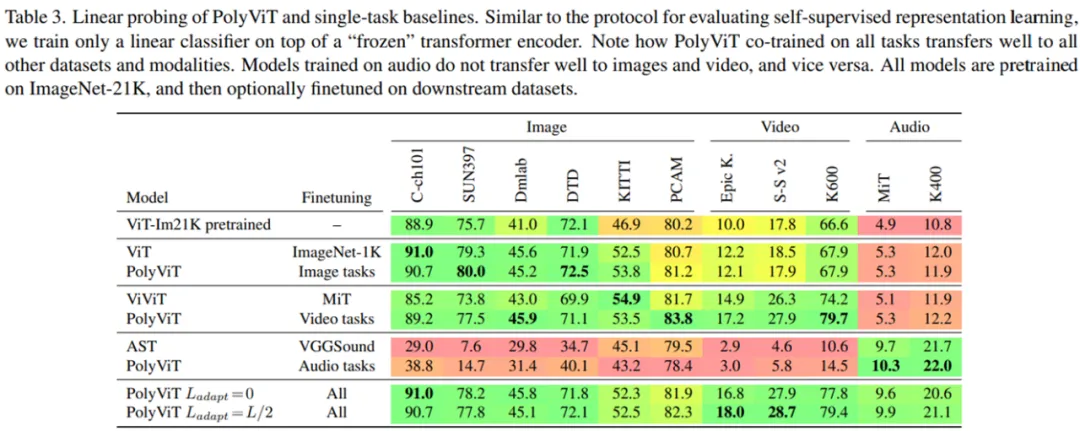
通過為一個新任務(wù)僅僅添加和訓練一個新的線性頭(linear head),研究者對 PolyViT 學習到的特征表示進行評估。下表 3 展示了多種模態(tài)上訓練的 PolyViT 如何學習「在跨圖像、音頻和視頻三種模態(tài)的 11 個線性評估任務(wù)上均表現(xiàn)良好的」跨模態(tài)特征表示。同時,表 3 還展示了多種模態(tài)上的協(xié)同訓練如何有益于學習強大、可遷移且可用于多個下游任務(wù)的特征表示。
使用單模態(tài)協(xié)同訓練實現(xiàn) SOTA 性能
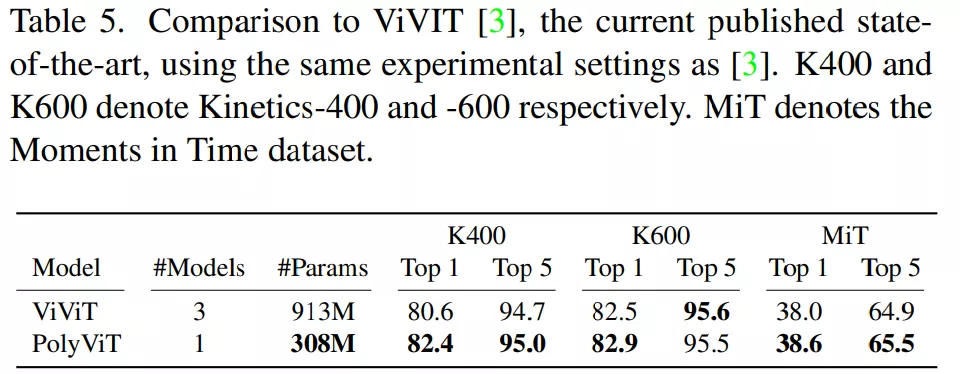
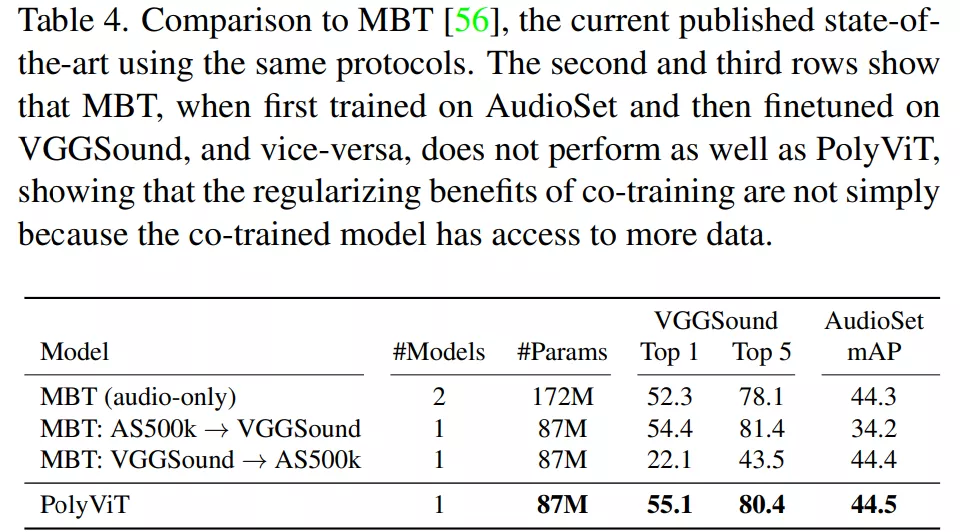
受到上表 2 中單模態(tài)協(xié)同訓練性能的啟發(fā),研究者使用這種方法在音頻和視頻分類任務(wù)上執(zhí)行了大規(guī)模協(xié)同訓練實驗。下表 4 和表 5 顯示,在使用的參數(shù)明顯更少的同時,他們實現(xiàn)了 SOTA 結(jié)果。
如下表 4 所示,對于音頻分類,研究者將 PolyViT 與當前 SOTA 方法 MBT(audio-only) 及相關(guān)變體 MBT: AS-500k→VGGSound 和 MBT: VGGSound→AS-500k。結(jié)果表明,PolyViT 在兩個數(shù)據(jù)集上超越了 SOTA 方法,同時使用的參數(shù)大約是 MBT(audio-only) 的一半。此外,PolyViT 在更小的數(shù)據(jù)集 VGGSound 上實現(xiàn)了 2.8% 的 Top 1 準確率提升。
對于視頻分類,研究者在 Kinetics-400、Kinetics-600 和 Moments in Time 數(shù)據(jù)集上協(xié)同訓練了具有較小 tubelet size 的 PolyViT-Large 模型,并與當前 SOTA 模型 ViViT(使用相同的初始化、主干和 token 數(shù)量)進行了比較。結(jié)果如下表 5 所示,表明 PolyViT 在三個數(shù)據(jù)集上均超越了 ViViT。