基于Dify動態解析異構銀行流水:架構拆解→風控報告生成

兩個月前,知識星球中有個關于銀行流水分析的提問:
想問問對于流水識別是否有比較好的解決方案呢?我們現在想用大模型能夠對多家銀行進行識別,但是發現識別準確率很一般,經常出現表格識別數據錯亂的情況,而且效率也不太行

這個問題在企業信貸的貸前風控場景經常出現,不同銀行的流水格式一般有所區別,而且一家企業往往涉及多家銀行的賬戶使用。這也導致了流水解析和分析工作復雜度確實高很多。
我其實去年底在 Github 上開源過一個見知流水格式的流水分析報告Demo,當時是針對單一銀行格式,不過也是完整實現了指標加工邏輯的和報告生成方法的介紹,感興趣的可以瞅瞅:https://github.com/weiwill88/bank-statement-analysis
這篇試圖說清楚:
信貸場景的貸前盡調背景、多銀行流水的非標特點,以及如何基于 Dify 實現對多源異構銀行流水的自動化分析報告生成。

基于Dify動態解析異構銀行流水,韋東東,8分鐘
以下,enjoy:
1、項目背景
熟悉信貸行業的盆友應該都知道,在貸前風控體系中,通過線上方式獲取到的企業的工商、司法、稅務及征信等多類型數據,因為有非常多成熟的解析和清洗做法,各家更多的是基于經驗來構建規則引擎進行自動化審批。但是,這套體系存在一個關鍵的盲區,也就是下述要展開提到企業真實的經營現金流情況。
分析企業銀行流水,是判斷企業經營穩定性和真實貿易背景的最重要手段之一。尤其是其中收入是否穩定、支出是否合理、是否存在異常的資金往來。當然,既然大家都沒普遍采用這類數據肯定是因為有眾多顯示的難點:
1.1線下獲取問題
銀行流水不像稅務數據一樣,可以線下或線上完成授權后,直接線上獲取后處理分析。而且一家企業往往會涉及多個常用的銀行賬戶,所以需要業務人員線下方式向企業收集,最常見的格式是 Excel 或 PDF 格式(這篇以 EXCEL 格式為例進行演示)。
1.2人工分析的瓶頸
拋開純線上的企業貸款產品不談,一般線下授信的貸前盡調環節,客戶經理都需要從客戶收集多家銀行格式各異的流水表格,然后再手動進行匯總和分析。這個過程不僅效率低下,更容易因人為疏忽而遺漏關鍵的風險點,比如一筆偽裝成正常經營的大額融資款流入,或一筆隱藏的關聯方資金占用等。
2、核心挑戰
要利用 LLM Agent 實現對銀行流水的全自動分析,我們必須克服幾個現實的技術難題:
2.1表頭位置不固定
不同銀行的流水導出格式差異很大。最棘手的問題是,列標題(Header)并不是總在文件的第一行,有的在第二行,有的甚至在第四、第五行,上方可能包含銀行 Logo、賬戶信息等元數據。
這種不確定性也讓傳統的硬編碼腳本(如 pandas.read_excel(header=0))完全失效。所以,現在市面上多家
SaaS 的做法就是窮舉所有銀行或支付公司的模板。雖然這種做法看起來和務實,但確實屬于上一個時代的做法,既不優雅也無法應對銀行未來可能發生的格式調整。

2.2核心字段名稱不統一
即便定位了表頭,還需要把不同銀行的列名映射到統一的分析字段上。例如,關注的核心指標是“交易時間”、“收入”、“支出”、“賬戶余額”、“交易對手”和“摘要”。但在實際流水中,它們可能被命名為“記賬日”、“貸方發生額(收入)”、“借方發生額(支出)”、“余額”、“對方戶名”、“附言”等等。如何準確理解這些“同義詞”,是實現自動化的關鍵。

2.3摘要信息定性難
判斷一筆交易的真實性質(如銷售回款、采購支出、工資發放),強依賴于對“摘要”或“附言”字段的理解。人工判斷不僅耗時,且極度依賴個人經驗。要讓機器做出精準判斷,就必須為其注入兩類核心知識:
交易分類知識:如何根據摘要關鍵詞(如“貨款”、“工資”)將交易歸入正確的業務類別?
風險分析知識:當某些數據模式出現時(如客戶高度集中、大額對私轉賬),它們具體意味著什么風險?

為了系統性地解決這個問題,我提供了兩個核心知識庫作為示例:銀行流水交易分類規則.md 和風險分析規則與文本模板.md。這兩個文件把風控專家的經驗規則化、文本化,是驅動 LLM 進行貼合場景深度分析的必要參考。
3、解決方案架構
為了解決上述提到的問題,下面演示一個基于 Dify 的工作流方案。其核心思想是“分而治之”,引入了很多代碼和 LLM 節點,讓不同的節點各司其職,最后完成一份流水分析報告。核心架構參考下圖:

3.1動態識別與解析
核心節點:打印流水前十行 (Code) -> 定位表頭位置 (LLM)
實現方式:不直接讓 LLM 處理整個流水文件,而是先用一個 Code 節點(打印流水前十行)提取每個文件的前 10 行作為“預覽”。這一般足以暴露表頭的位置和命名方式。
然后把這些預覽喂給定位表頭位置 LLM 節點,并給它一個非常明確的指令(來自 定位表頭位置 節點):

"你是一個專業的銀行流水數據解析專家。你的任務是分析下面提供的多個銀行流水文件預覽...確定哪個自然行是真正的列標題行...找出它在預覽中對應的原始列名...嚴格按照下面的JSON格式輸出你的分析結果。"LLM 會輸出一個結構化的 JSON 指令,精確地告訴后續節點每個文件的表頭在哪一行,以及“收入”、“支出”等標準字段對應原始表中的哪一列。
3.2標準化與計算
核心節點:標準化合并 (Code) -> 核心指標計算 (Code)
實現方式:標準化合并 Code 節點接收上一步 LLM 生成的 JSON 指令和原始文件全文。它會嚴格按照指令解析每一個格式各異的文件,把所有交易記錄清洗、轉換并合并成一個統一格式的 JSON 數組。
# 解析LLM輸出的JSON指令
instructions = json.loads(clean_json_str)
for instruction in instructions:
file_index = instruction['file_index'] - 1
header_row_index = instruction['header_row_index']
column_mapping = instruction['column_mapping']
# ...根據上述指令進行CSV讀取和列映射...
rename_map = {v: k for k, v in column_mapping.items() if v is not None}
# ...隨后,核心指標計算 Code 節點對標準化的數據進行純粹的數學計算,得出月度趨勢、流入流出構成、核心對手方等關鍵指標,并輸出為 JSON。值得一提的是,在此節點中,引用了銀行流水交易分類規則.md 的核心思想。 對于高頻且明確的交易類型,我們直接在代碼中內置了關鍵詞分類邏輯,以保證計算的效率和準確性。
這個知識庫定義了如何將模糊的交易摘要映射到標準的財務類別:
## 流入分類 (Inflow Categories)
### 銷售回款 (Sales Revenue)
- 關鍵詞: 貨款, 銷售, 收款, 工程款...
### 人力及稅費 (HR & Tax)
- 關鍵詞: 工資, 薪金, 薪酬, 社保, 稅...在 核心指標計算 節點的代碼中,實現了下述這個邏輯。這種“規則代碼化”的方式確保了基礎分類的穩定,而完整的知識庫文件則用于后續 LLM 的深度理解。

# ...
classification_rules = {
'inflow': {
'銷售回款': ['貨款', '銷售', '收款', ...],
# ...
},
'outflow': {
'人力及稅費': ['工資', '薪金', '薪酬', ...],
# ...
}
}
# ...
if any(kw in summary for kw in keywords):
composition_stats['inflow'][cat] += inflow
# ...3.3知識增強與洞察
核心節點:生成分析查詢 (Code) -> 知識庫召回 (Knowledge Retrieval) -> 生成分析報告 (LLM)
實現方式:這一步是提升分析深度的關鍵。此階段深度依賴第二個知識庫 風險分析規則與文本模板.md。這個知識庫以“規則-模板”的形式存在。它告訴 AI 在發現特定數據模式時,應該生成什么樣的風險提示。

## 經營穩定性分析 (Business Stability Analysis)
- 規則: 前三大流入對手方合計占比 > 70%
- 模板: "客戶集中度風險:企業經營收入高度依賴前三大客戶(合計占比 {concentration_ratio}%)..."
## 交易行為異常 (Abnormal Transaction Behavior)
- 規則: 存在大額資金從對公賬戶流向個人賬戶...
- 模板: "對私轉賬風險:系統監測到公司向個人賬戶‘{personal_account_name}’合計轉賬 {total_amount} 萬元..."工作流程如下:
1、生成分析查詢 節點基于計算指標,動態生成查詢,如“客戶集中度為 85%,這存在什么風險?”。
2、知識庫召回 節點接收到這個問題后,從風險分析規則與文本模板.md 中精確匹配到“客戶集中度風險”的規則和模板。
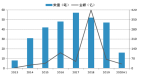
3、最后,生成分析報告 LLM 節點會拿到三樣東西:數據(指標 JSON)、問題(動態查詢)、以及答案模板(從知識庫召回的文本)。LLM 最后把實時計算出的數據(如{concentration_ratio}的值)填充到分析模板中,最終生成一份數據翔實分析報告。


4、工程經驗與架構升級方向
4.1工程經驗提煉
LLM 與 Code 的“指令-執行”模式
這個項目演示的一大亮點在于,把 LLM 定位成生成結構化指令(JSON)的“動態解析器生成器”。由確定性的 Code 節點來執行這些指令,確保了數據處理的穩定性和可靠性。
“預覽+認知”策略的有效性
通過讓 LLM 先看“預覽”來降低問題難度,可以顯著提升其識別復雜格式的準確率,并節約處理 Token 的成本。
動態 RAG
相比于用一個籠統的問題去檢索知識庫,先通過 Code 節點先分析數據,再提出“數據驅動”的、具體的問題。這使得 RAG 的召回內容更具針對性,極大地提升了最終報告的分析深度。
混合分類方法
在 核心指標計算 節點中,內置了基于關鍵詞的簡單分類規則,用于處理明確的交易(如“工資”、“稅”)。這是一種有效的“人機協作”,將簡單、高頻的任務交給代碼,把復雜、模糊的定性任務留給知識庫和 LLM,實現了效率和質量的平衡。
4.2架構升級參考
引入多模態能力處理 PDF 和圖片
當前工作流主要處理 Excel(文本化后)。下一步可以集成其他工具作為前置節點,把掃描版的 PDF 或圖片格式的流水單據轉換為文本,從而將處理范圍擴大到所有常見流水格式。
構建交易對手知識圖譜
當前的對手方分析停留在 TOP N 列表。未來可以引入知識圖譜技術,將所有交易對手構建成一個網絡,用于挖掘隱性的關聯關系、識別資金的循環流動(空轉)或疑似的殼公司交易。
增加自修正的閉環反饋機制
可以在標準化合并節點后增加一個校驗環節。如果解析失敗或數據出現邏輯錯誤(如余額對不平),可以將錯誤信息和原始預覽再次反饋給定位表頭位置 LLM 節點,讓其再試一次,形成一個自修正的循環,提升魯棒性。
人機協同
對于 LLM 無法準確分類的“未分類交易”,可以設計一個簡單的標注界面。系統將這些模糊的交易推送給人工進行標注,標注結果再反哺到知識庫,使系統在持續使用中變得越來越聰明。