美國奧數(shù)題撕碎AI數(shù)學(xué)神話,頂級模型現(xiàn)場翻車!最高得分5%,DeepSeek唯一逆襲
3月26號,ETH等團隊的一項研究一經(jīng)發(fā)布,就引起了圈內(nèi)熱議。
這項研究徹底撕開遮羞布,直接擊碎了「LLM會做數(shù)學(xué)題」這個神話!
 圖片
圖片
論文地址:https://files.sri.inf.ethz.ch/matharena/usamo_report.pdf
鑒于此前它們在AIME上的出色表現(xiàn),MathArena團隊使用最近的2025年美國數(shù)學(xué)奧林匹克競賽進行了詳細評估,結(jié)果令人大吃一驚——
所有大模型的得分,都低于5%!
DeepSeek-R1表現(xiàn)最好,得分為4.76%;而表現(xiàn)最差的OpenAI o3-mini(high)比上一代o1-pro(high)還差,得分為2.08%。
 各頂尖模型在2025 USAMO中的得分
各頂尖模型在2025 USAMO中的得分
就在今天,這項研究再次被關(guān)注到,直接成為了Reddit的熱議話題。
 圖片
圖片
具體來說,在這項研究中,模型需要在2025年USAMO的六道基于證明的數(shù)學(xué)題上進行了測試。每道題滿分7分,總分最高為42分。然后會由人類專家來給它們打分。
這些模型取得的最高平均分,也就5%,簡直慘不忍睹。
更好笑的是,這些模型對自己的解題進行評分時,還會一致高估自己的得分(此處點名O3-mini和Claude 3.7)。跟人類研究者相比,評分被夸大了能有20倍不止。
所以,此前模型之所以能騙過人類,營造出自己很擅長做數(shù)學(xué)的假象,純純是因為它們已經(jīng)在所有可以想象到的數(shù)學(xué)數(shù)據(jù)上進行了訓(xùn)練——國際奧數(shù)題、美國奧數(shù)檔案、教科書、論文,它們?nèi)家娺^!
而這次,它們一下子就暴露出了三大致命缺陷。
邏輯錯誤:模型在推理過程中做出了不合理的跳躍,或?qū)㈥P(guān)鍵步驟標(biāo)記為「微不足道」。
缺乏創(chuàng)造力:大多數(shù)模型反復(fù)堅持相同的有缺陷策略,未能探索替代方案。
評分失敗:LLMs 的自動評分顯著提高了分數(shù),表明他們甚至無法可靠地評估自己的工作。
這,就是人類投入數(shù)十億美元后造出的成果。
DeepSeek,唯一亮眼的選手
好在,這項研究中,多少還是有一些令人鼓舞的跡象。
比如「全村的希望」DeepSeek,在其中一次嘗試中,幾乎完全解決了問題4。
 圖片
圖片
問題4大意為:
設(shè)H為銳角三角形ABC的垂心,F(xiàn)為從C向AB所作高的垂足,P為H關(guān)于BC的對稱點。假設(shè)三角形AFP的外接圓與直線BC相交于兩個不同的點X和Y。證明:C是XY的中點。
LLM數(shù)學(xué)能力,到底強不強?
LLM的數(shù)學(xué)能力,早已引起了研究人員的懷疑。
在AIME 2025 I中,OpenAI的o系列模型表現(xiàn)讓人嘆服。
對此,來自蘇黎世聯(lián)邦理工學(xué)院的研究人員Mislav Balunovi?,在X上公開表示:「在數(shù)學(xué)問題上,LLM到底具有泛化能力,還是學(xué)會了背題,終于有了答案。」
 圖片
圖片
然而,馬上有人發(fā)現(xiàn),測試的題目網(wǎng)上就有「原題」,質(zhì)疑LLM根本沒學(xué)懂?dāng)?shù)學(xué),只是記下了答案。
 圖片
圖片
在AIME 2025 II中,o3-mini(high)準確率更是高達93%!
而來自普林斯頓的華人團隊,研究顯示LLM可能只是學(xué)會了背題 ——
將MATH數(shù)據(jù)集中的問題,做一些改動,多個模型的性能顯著下降!
 圖片
圖片
美國數(shù)學(xué)奧林匹克競賽的選拔賽AIME 2025 I和AIME 2025 II是,成績優(yōu)異者才能參加2025年的USAMO
那問題來了,LLM的數(shù)學(xué)泛化能力到底強不強?
LLM真學(xué)會了數(shù)學(xué)證明嗎?
這次,來自ETH Zurich等研究團隊,終于證明:實際上,LLM幾乎從未沒有學(xué)會數(shù)學(xué)證明!
研究團隊邀請了具有奧數(shù)評審經(jīng)驗的專家,評估了頂尖模型(如o3-mini、Claude 3.7和Deepseek-R1)的證明過程。
在評估報告中,研究人員重點指出了幾個常見問題。
比如,AI會使用未經(jīng)證明的假設(shè),
再比如,模型總是執(zhí)著于輸出格式漂亮的最終答案,即便并未要求它們這樣做。
美國奧賽,LLM表現(xiàn)堪憂
這是首次針對2025年美國數(shù)學(xué)奧林匹克競賽(USAMO)的難題,系統(tǒng)評估LLM的自然語言證明能力。
USAMO作為美國高中數(shù)學(xué)競賽的最高殿堂,要求證明與國際數(shù)學(xué)奧林匹克(IMO)同等級別的嚴密與詳細闡述。
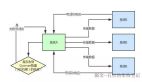
美國數(shù)學(xué)奧林匹克(USAMO)是美國國家級邀請賽,是國際數(shù)學(xué)奧林匹克隊伍選拔中的關(guān)鍵一步。
 美國國際數(shù)學(xué)奧林匹克競賽隊員選拔流程
美國國際數(shù)學(xué)奧林匹克競賽隊員選拔流程
USAMO和USAJMO是為期兩天、共包含六個問題、9小時的論文/證明考試。
USAMO完美契合評估LLM的目標(biāo):題目難度高、要求完整證明過程才能得分,且未經(jīng)公開數(shù)據(jù)污染。
參賽者雖通過AIME等賽事晉級,但USAMO問題對解題的嚴謹性與解釋深度要求顯著更高。
整體而言,當(dāng)前LLMs在USAMO問題中表現(xiàn)堪憂,最優(yōu)模型的平均得分不足5%。
在生成嚴格數(shù)學(xué)證明方面,現(xiàn)有LLM還有重大局限!
本報告中,首先在§2闡述方法論,§3詳述結(jié)果并分析核心弱點,§4則討論多項定性觀察結(jié)論。
LLM評估方法
在評估過程中,為每個模型提供題目,并明確要求其生成格式規(guī)范的LaTeX詳細證明。
完整的提示詞說明,原文如下:
 圖片
圖片
提示詞大意為:
請對以下問題給出詳盡的答案。你的答案將由人工評委根據(jù)準確性、正確性以及你證明結(jié)果的能力來評分。你應(yīng)包含證明的所有步驟。不要跳過重要步驟,因為這會降低你的分數(shù)。僅僅陳述結(jié)果是不夠的。請使用LaTeX來格式化你的答案
{問題}
為降低方差,每個模型對每道題獨立求解4次。
所有解答(不含推理過程)經(jīng)匿名化處理后統(tǒng)一轉(zhuǎn)換為PDF格式供評分使用。
改卷專家與流程
評分團隊由四位專家組成,每位專家都擁有豐富的數(shù)學(xué)解題經(jīng)驗,他們曾是國家國際數(shù)學(xué)奧林匹克(IMO)代表隊成員,或者參加過各自國家的最終階段國家隊選拔。
在評分之前,評委們收到了詳細說明評估目標(biāo)和方法的指導(dǎo)意見。
2025年美國數(shù)學(xué)奧林匹克競賽(USAMO)共有六道題目。
 圖片
圖片
每一道都由2名評估人員獨立進行評估,每位評委負責(zé)批改三道不同的題目。
這種雙評的評分方法仿照了國際數(shù)學(xué)奧林匹克競賽(IMO)的評估流程,確保了評分的一致性,并減少了個人偏見。
由于美國數(shù)學(xué)奧林匹克競賽官方并不公布標(biāo)準答案或評分方案,研究人員依靠數(shù)學(xué)界資源,尤其是「解題的藝術(shù)」(Art of Problem Solving,簡稱AoPS)論壇,為每一道題目精心制定了標(biāo)準化的評分方案。
在制定評分方案之前,評估人員對來自這些資源的所有解答進行了準確性驗證。
按照美國數(shù)學(xué)奧林匹克競賽的慣例,每道題目的最高分為7分,對于取得重大且有意義進展的解答會給予部分分數(shù)。
評審專家根據(jù)預(yù)先制定的評分標(biāo)準,對每份解答進行獨立評閱。當(dāng)答案與評分標(biāo)準存在偏差時,評審會在合理范圍內(nèi)給予部分得分。
每位專家均需詳細記錄評分依據(jù),包括所有部分得分的授予理由,相關(guān)評語已公開在項目網(wǎng)站。
錯誤模式歸檔
在評閱過程中,專家還需系統(tǒng)記錄典型的錯誤模式。
「錯誤模式」定義為解題過程中首次出現(xiàn)的推理缺陷,包括但不限于:邏輯謬誤、未驗證的假設(shè)、數(shù)學(xué)表述不嚴謹或計算錯誤。
具體而言,這些錯誤被劃分為以下四類:
1. 邏輯類錯誤:因邏輯謬誤或未經(jīng)論證的推理跳躍導(dǎo)致論證鏈斷裂;
2. 假設(shè)類錯誤:引入未經(jīng)證明或錯誤假設(shè),致使后續(xù)推導(dǎo)失效;
3. 策略類錯誤:因未能識別正確解題路徑而采用根本性錯誤解法;
4. 運算類錯誤:關(guān)鍵代數(shù)運算或算術(shù)計算失誤。
此外,對于模型生成的解答中值得關(guān)注的行為或趨勢,研究人員錄為文檔,以便進一步分析。
這些觀察結(jié)果被用于找出模型在推理能力方面常見的陷阱和有待改進的地方。
評估結(jié)果
在解決美國數(shù)學(xué)奧林匹克競賽(USAMO)的問題時,所有模型表現(xiàn)都很差。
此外,還會深入分析了常見的失敗模式,找出了模型推理過程中的典型錯誤和趨勢。
主要發(fā)現(xiàn)
針對2025年美國數(shù)學(xué)奧林匹克競賽(USAMO)的問題,對六個最先進的推理模型進行了評估,分別為QwQ、R1、Flash-Thinking、o1-Pro、o3-mini和Claude 3.7。
表1提供了每個問題的模型性能詳細分類,平均分數(shù)是通過四次評估運行計算得出的。
美國數(shù)學(xué)奧林匹克競賽的每個問題滿分為7分,每次運行的總最高分是42分。
該表還包括在所有問題和評估運行中運行每個模型的總成本。
成本以美元計算,各模型在所有題目上的最終得分取各評審所給分數(shù)的平均分呈現(xiàn)。
 圖片
圖片
表1:評估核心結(jié)果。每道題目采用7分制評分,滿分總計42分。表中分數(shù)為四次運行的平均值。
新的評估揭示了LLM在生成嚴謹數(shù)學(xué)證明方面的顯著不足。
所有受測模型的最高平均得分均低于5%,這一結(jié)果表明現(xiàn)有模型在處理USAMO級別問題的復(fù)雜性和嚴密性方面存在根本性局限。
值得注意的是,在所有模型提交的近150份解答中,沒有一份獲得滿分。
雖然USAMO的題目難度確實高于既往測試的競賽,但所有模型在不止一道題目上的全軍覆沒,充分證明當(dāng)前LLM仍無法勝任奧數(shù)級別的嚴格數(shù)學(xué)推理任務(wù)。
這一局限同時暗示,GRPO等現(xiàn)有優(yōu)化方法,對于需要高度邏輯精密度的任務(wù)可能仍然力有未逮。
常見的失效模式
人類參賽者往往找不到正確解題方法,不過一般能判斷自己的答案對不對。
反觀LLM,不管做沒做對,都一口咬定自己解出了題目。
這種反差,給LLM在數(shù)學(xué)領(lǐng)域的應(yīng)用出了難題——要是沒經(jīng)過人工嚴格驗證,這些模型給出的數(shù)學(xué)結(jié)論,都不太靠譜。
為了搞清楚LLM這一局限,按事先定義好的錯誤分類標(biāo)準,對評分時發(fā)現(xiàn)的錯誤展開了系統(tǒng)分析。
圖2呈現(xiàn)了評審判定的錯誤類型分布。
在所有錯誤類型里,邏輯缺陷最為普遍。
LLM經(jīng)常使用沒有依據(jù)的推理步驟,論證時出錯,或者誤解前面的推導(dǎo)過程。
另外,模型還有個大問題:碰到關(guān)鍵證明步驟,就敷衍地歸為「顯然成立」或「標(biāo)準流程」,不做論證。
就連o3-mini也多次把核心證明步驟標(biāo)成「顯然」,直接跳過。可這些步驟是不是嚴謹,對解題特別關(guān)鍵。
除了前面提到的問題,研究人員還發(fā)現(xiàn),模型推理特別缺乏創(chuàng)造性。
好多模型在反復(fù)嘗試解題時,總是沿用同一套(還可能錯誤的)解題策略,壓根不去探索其他辦法。
不過,F(xiàn)lash-Thinking模型是個例外。它在解一道題時,會嘗試多種策略。但因為想做的太多,每種策略都沒深入,最后也沒能得出有效的結(jié)論。
值得一提的是,這些模型在代數(shù)運算上表現(xiàn)不錯。
面對復(fù)雜的符號運算,不用借助外部計算工具,就能輕松搞定。
但R1模型的代數(shù)/算術(shù)錯誤率偏高,還需針對性優(yōu)化。
 圖片
圖片
共性問題
在評估過程中,評審專家還記錄了模型的共性問題和顯著的特征。
答案框定問題
當(dāng)下,像GRPO這類基于強化學(xué)習(xí)的優(yōu)化技術(shù),需要從清晰標(biāo)注的最終答案里提取獎勵信號。
所以,模型常常被要求把最終答案放在\boxed{}里。
但這一要求,在USAMO解題過程中引發(fā)了異常情況。大部分賽題其實并不強制框定最終答案,但模型卻非要這么做。
以第五題為例,QwQ模型在解題時,自行排除了非整數(shù)解的可能,即便題目沒這個限制。
它還錯誤地認定最終答案是2。
QwQ可把自己「繞暈」啦!
它想要一個整數(shù)答案,可實際上,答案明明是所有偶數(shù)整數(shù)的集合。

這一現(xiàn)象說明,GRPO等對齊技術(shù)在不經(jīng)意間,讓模型形成了「所有數(shù)學(xué)問題都要框定答案」的固定思維,反倒削弱了模型的推理能力。
盲目泛化傾向
模型有個常見毛病,喜歡把在小規(guī)模數(shù)值案例里觀察到的模式,一股腦套用到還沒驗證的場景中。
在只求算出數(shù)值答案的題目里,這種方法或許還行得通。可一旦碰上需要嚴格證明的問題,它的弊端就暴露無遺。
模型經(jīng)常不做任何證明,就直接宣稱局部觀察到的模式放之四海而皆準。
比如說,在問題2的求解過程中,F(xiàn)LASH-THINKING模型選擇了一個具體的多項式進行驗證,但隨后卻錯誤地將結(jié)論推廣至所有多項式。
這種從特殊案例直接跳躍到普遍結(jié)論的做法,暴露了當(dāng)前模型在數(shù)學(xué)歸納推理能力上的根本缺陷——
它們?nèi)狈Α赋浞中宰C明」這一數(shù)學(xué)核心原則的理解,無法區(qū)分「舉例驗證」與「完備證明」的本質(zhì)區(qū)別。
 圖片
圖片
Gemini Flash-Thinking的盲目泛化
解答結(jié)構(gòu)與清晰度
不同模型的解答在結(jié)構(gòu)清晰度上差異顯著。
1. 優(yōu)質(zhì)范例:o3-mini和o1-Pro的解答邏輯清晰、層次分明
2. 典型缺陷:Flash-Thinking和QwQ常產(chǎn)生混亂難解的應(yīng)答,有時在同一解法中混雜多個無關(guān)思路
OpenAI訓(xùn)練模型在可讀性上超厲害!這說明,專門針對解答連貫性開展訓(xùn)練,能大幅提升輸出質(zhì)量。
反觀其他模型,在這方面明顯不夠上心。
參考資料:
https://files.sri.inf.ethz.ch/matharena/usamo_report.pdf
https://x.com/mbalunovic/status/1904539801728012545
https://maa.org/maa-invitational-competitions/