













剛剛!DeepSeek梁文鋒親自掛名,公開新注意力架構(gòu)NSA
DeepSeek 新論文來了!相關(guān)消息剛剛發(fā)布到 ?? 就吸引了大量用戶點(diǎn)贊、轉(zhuǎn)發(fā)、評(píng)論三連。
據(jù)介紹,DeepSeek 的這篇新論文提出了一種新的注意力機(jī)制 ——NSA。這是一個(gè)用于超快長(zhǎng)上下文訓(xùn)練和推斷的本地可訓(xùn)練的稀疏注意力機(jī)制,并且還具有與硬件對(duì)齊的特點(diǎn)。

新研究發(fā)布兩個(gè)小時(shí),就有近三十萬的瀏覽量。現(xiàn)在看來,DeepSeek 發(fā)布成果,比 OpenAI 關(guān)注度都高。

論文標(biāo)題:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
論文鏈接:https://arxiv.org/abs/2502.11089
值得一提的是,幻方科技、DeepSeek 創(chuàng)始人梁文鋒也是論文的作者之一。這成了眾多網(wǎng)友討論的話題。

接下來,讓我們看下梁文鋒親自參與的研究,講了什么內(nèi)容。
論文概覽
長(zhǎng)上下文建模是下一代大型語言模型(LLM)的關(guān)鍵能力,這一需求源于多樣化的實(shí)際應(yīng)用,包括深度推理、倉(cāng)庫(kù)級(jí)代碼生成以及多輪自動(dòng)智能體系統(tǒng)等。
最近大模型的突破 —— 如 OpenAI 的 o 系列模型、DeepSeek-R1 和 Gemini 1.5 Pro—— 已經(jīng)能使得模型能夠處理整個(gè)代碼庫(kù)、長(zhǎng)文檔、在數(shù)千個(gè) token 上保持連貫的多輪對(duì)話,并在長(zhǎng)距離依賴關(guān)系中進(jìn)行復(fù)雜推理。然而,隨著序列長(zhǎng)度的增加,普通注意力機(jī)制的高復(fù)雜性成為關(guān)鍵的延遲瓶頸。理論估計(jì)表明,在使用 softmax 架構(gòu)進(jìn)行 64k 長(zhǎng)度上下文的解碼時(shí),注意力計(jì)算占總延遲的 70-80%,這凸顯了對(duì)更高效注意力機(jī)制的迫切需求。
實(shí)現(xiàn)高效長(zhǎng)上下文建模的自然方法是利用 softmax 注意力的固有稀疏性,通過選擇性計(jì)算關(guān)鍵 query-key 對(duì),可以顯著減少計(jì)算開銷,同時(shí)保持性能。最近這一路線的進(jìn)展包括多種策略:KV 緩存淘汰方法、塊狀 KV 緩存選擇方法以及基于采樣、聚類或哈希的選擇方法。盡管這些策略前景廣闊,現(xiàn)有的稀疏注意力方法在實(shí)際部署中往往表現(xiàn)不佳。許多方法未能實(shí)現(xiàn)與其理論增益相媲美的加速;此外,大多數(shù)方法主要關(guān)注推理階段,缺乏有效的訓(xùn)練時(shí)支持以充分利用注意力的稀疏模式。
為了克服這些限制,部署有效的稀疏注意力必須應(yīng)對(duì)兩個(gè)關(guān)鍵挑戰(zhàn):
1、硬件對(duì)齊的推理加速:將理論計(jì)算減少轉(zhuǎn)化為實(shí)際速度提升,需要在預(yù)填充和解碼階段設(shè)計(jì)硬件友好的算法,以緩解內(nèi)存訪問和硬件調(diào)度瓶頸;
2、訓(xùn)練感知的算法設(shè)計(jì):通過可訓(xùn)練的操作符實(shí)現(xiàn)端到端計(jì)算,以降低訓(xùn)練成本,同時(shí)保持模型性能。
這些要求對(duì)于實(shí)際應(yīng)用實(shí)現(xiàn)快速長(zhǎng)上下文推理或訓(xùn)練至關(guān)重要。在考慮這兩方面時(shí),現(xiàn)有方法仍顯不足。
為了實(shí)現(xiàn)更有效和高效的稀疏注意力,DeepSeek 研究人員提出了一種原生可訓(xùn)練的稀疏注意力架構(gòu) NSA,它集成了分層 token 建模。
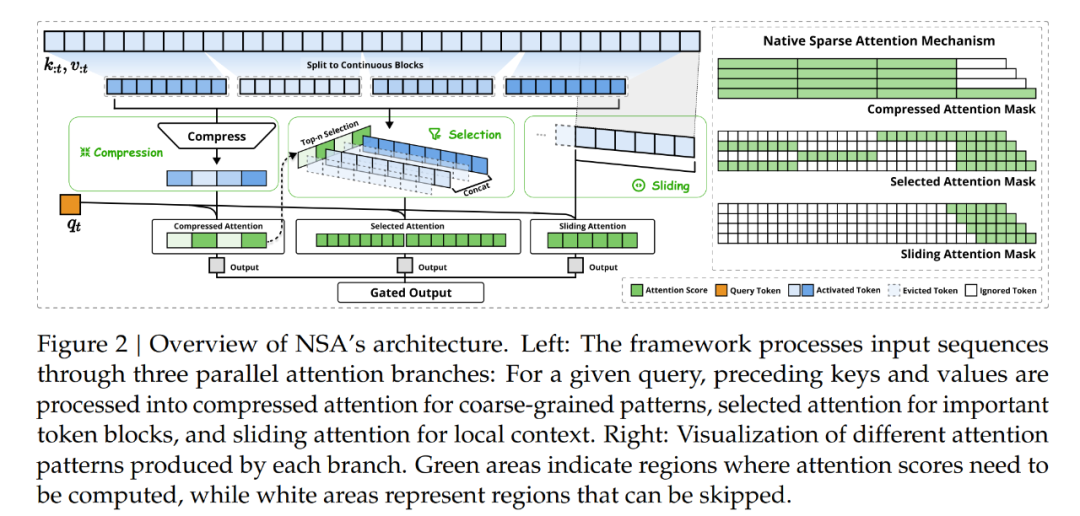
如圖 2 所示,NSA 通過將鍵和值組織成時(shí)間塊(temporal blocks)并通過三條注意力路徑處理它們來減少每查詢計(jì)算量:壓縮的粗粒度 token、選擇性保留的細(xì)粒度 token 以及用于局部上下文信息的滑動(dòng)窗口。隨后,作者實(shí)現(xiàn)了專門的核以最大化其實(shí)際效率。
NSA 引入了兩個(gè)核心創(chuàng)新以對(duì)應(yīng)于上述關(guān)鍵需求:
1、硬件對(duì)齊的系統(tǒng):優(yōu)化塊狀稀疏注意力以利用 Tensor Core 和內(nèi)存訪問,確保算術(shù)強(qiáng)度平衡;
2、訓(xùn)練感知的設(shè)計(jì):通過高效算法和反向操作符實(shí)現(xiàn)穩(wěn)定的端到端訓(xùn)練。這一優(yōu)化使 NSA 能夠支持高效部署和端到端訓(xùn)練。
研究通過對(duì)現(xiàn)實(shí)世界語言語料庫(kù)的綜合實(shí)驗(yàn)來評(píng)估 NSA。在具有 260B token 的 27B 參數(shù) Transformer 骨干上進(jìn)行預(yù)訓(xùn)練,作者評(píng)估了 NSA 在通用語言評(píng)估、長(zhǎng)上下文評(píng)估和鏈?zhǔn)酵评碓u(píng)估中的表現(xiàn)。作者還進(jìn)一步比較了在 A100 GPU 上內(nèi)核速度與優(yōu)化 Triton 實(shí)現(xiàn)的比較。實(shí)驗(yàn)結(jié)果表明,NSA 實(shí)現(xiàn)了與 Full Attention 基線相當(dāng)或更優(yōu)的性能,同時(shí)優(yōu)于現(xiàn)有的稀疏注意力方法。
此外,與 Full Attention 相比,NSA 在解碼、前向和后向階段提供了明顯的加速,且加速比隨著序列長(zhǎng)度的增加而增加。這些結(jié)果驗(yàn)證了分層稀疏注意力設(shè)計(jì)有效地平衡了模型能力和計(jì)算效率。
方法概覽
本文的技術(shù)方法涵蓋算法設(shè)計(jì)和內(nèi)核優(yōu)化。作者首先介紹了方法背景,然后介紹了 NSA 的總體框架以及關(guān)鍵算法組件,最后詳細(xì)介紹了針對(duì)硬件優(yōu)化的內(nèi)核設(shè)計(jì),以最大限度地提高實(shí)際效率。
背景
注意力機(jī)制在語言建模中被廣泛使用,其中每個(gè)查詢 token q_??計(jì)算與所有前面鍵 k_:??的相關(guān)性分?jǐn)?shù),以生成值 v_:??的加權(quán)和。從形式上來說,對(duì)于長(zhǎng)度為??的輸入序列,注意力操作定義如下:

其中 Attn 表示注意力函數(shù)。
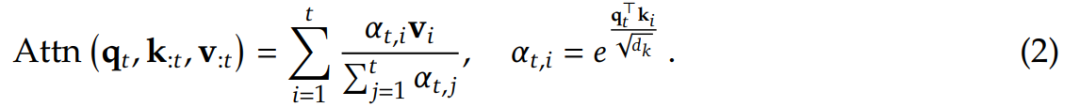
這里,??_??,?? 表示 q_?? 和 k_?? 之間的注意力權(quán)重,??_??是鍵的特征維度。隨著序列長(zhǎng)度的增加,注意力計(jì)算在總計(jì)算成本中變得越來越占主導(dǎo)地位,對(duì)長(zhǎng)上下文處理提出了重大挑戰(zhàn)。
算術(shù)強(qiáng)度(Arithmetic Intensity)是計(jì)算操作與內(nèi)存訪問的比率,本質(zhì)上決定了硬件的算法優(yōu)化。每個(gè) GPU 都有一個(gè)由其峰值計(jì)算能力和內(nèi)存帶寬決定的臨界算術(shù)強(qiáng)度,以這兩個(gè)硬件限制的比率計(jì)算。對(duì)于計(jì)算任務(wù),高于此臨界閾值的算術(shù)強(qiáng)度將構(gòu)成計(jì)算限制(受限于 GPU FLOPS),而低于此閾值的算術(shù)強(qiáng)度將構(gòu)成內(nèi)存限制(受限于內(nèi)存帶寬)。
具體來說,對(duì)于因果自注意力機(jī)制,在訓(xùn)練和預(yù)填充階段,批量矩陣乘法和注意力計(jì)算表現(xiàn)出高算術(shù)強(qiáng)度,使得這些階段在現(xiàn)代加速器上計(jì)算受限。相反,自回歸解碼會(huì)受到內(nèi)存帶寬的限制,因?yàn)樗看吻跋騻鬟f都會(huì)生成一個(gè) token,同時(shí)需要加載整個(gè)鍵值緩存,從而導(dǎo)致算術(shù)強(qiáng)度較低。這樣就出現(xiàn)了不同的優(yōu)化目標(biāo),即減少訓(xùn)練和預(yù)填充期間的計(jì)算成本,同時(shí)減少解碼期間的內(nèi)存訪問。
總體框架
為了充分利用具有自然稀疏模式的注意力機(jī)制的潛力,作者提出將 (1) 式中原始的鍵 - 值對(duì)替換成更加緊湊和信息密集的表征鍵 - 值對(duì)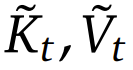 。具體而言,可將優(yōu)化的注意力輸出的形式定義成:
。具體而言,可將優(yōu)化的注意力輸出的形式定義成:
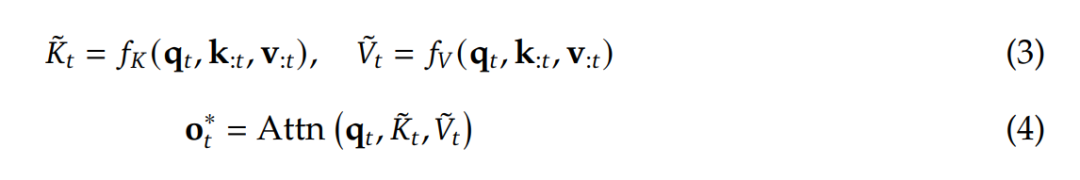
其中 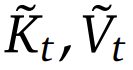 是基于當(dāng)前查詢 q_?? 和上下文記憶 k_:?? , v_:?? 動(dòng)態(tài)構(gòu)建的。通過設(shè)計(jì)不同的映射策略,可以得到
是基于當(dāng)前查詢 q_?? 和上下文記憶 k_:?? , v_:?? 動(dòng)態(tài)構(gòu)建的。通過設(shè)計(jì)不同的映射策略,可以得到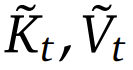 的不同類別,然后可將它們按以下方式組合起來
的不同類別,然后可將它們按以下方式組合起來

如圖 2 所示,NSA 有三種映射策略 C = {cmp, slc, win},分別表示鍵和值的壓縮、選取和滑動(dòng)窗口。??^??_?? ∈ [0, 1] 是對(duì)應(yīng)于策略 c 的門控分?jǐn)?shù),可通過 MLP 和 sigmoid 激活從輸入特征中得出。令 ??_?? 表示重新映射的鍵 / 值的總數(shù)

通過使 ??_?? ? ??,可保持較高的稀疏率。
接下來,DeepSeek 還介紹了重新映射策略的具體設(shè)計(jì),涵蓋 token 壓縮、token 選取和滑動(dòng)窗口。詳細(xì)的算法設(shè)計(jì)見原論文。下面來看看 NSA 為何具有 FlashAttention 相當(dāng)?shù)乃俣取?/span>
核設(shè)計(jì)
為了在訓(xùn)練和預(yù)填充期間實(shí)現(xiàn) FlashAttention 級(jí)別的加速,作者基于 Triton 實(shí)現(xiàn)了硬件對(duì)齊的稀疏注意力內(nèi)核。
由于多頭注意力(MHA)會(huì)占用大量?jī)?nèi)存且解碼效率低下,因此該團(tuán)隊(duì)選擇專注于遵循 SOTA LLM 的共享 KV 緩存架構(gòu),如 GQA 和 MQA。
雖然壓縮和滑動(dòng)窗口注意計(jì)算與現(xiàn)有的 FlashAttention-2 內(nèi)核很容易兼容,但他們卻引入了專門用于稀疏選擇注意的內(nèi)核設(shè)計(jì)。如果這時(shí)候遵循 FlashAttention 的做法,將時(shí)間連續(xù)的查詢塊加載到 SRAM 中,則會(huì)導(dǎo)致內(nèi)存訪問效率低下,因?yàn)閴K內(nèi)的查詢可能需要不相交的 KV 塊。
為了解決這個(gè)問題,這里的關(guān)鍵優(yōu)化在于不同的查詢分組策略:對(duì)于查詢序列上的每個(gè)位置,將 GQA 組內(nèi)的所有查詢頭(它們共享相同的稀疏 KV 塊)加載到 SRAM 中。圖 3 說明了其前向傳遞實(shí)現(xiàn)。

該設(shè)計(jì)能夠 (1) 通過分組共享消除冗余的 KV 傳輸,以及 (2) 跨 GPU 流式多處理器平衡計(jì)算工作負(fù)載,由此實(shí)現(xiàn)了近乎最佳的算術(shù)強(qiáng)度。
NSA 的實(shí)驗(yàn)表現(xiàn)
作者從三個(gè)角度對(duì)新提出的 NSA 進(jìn)行了評(píng)估:一般基準(zhǔn)性能、長(zhǎng)上下文基準(zhǔn)性能和思維鏈推理性能。
一般基準(zhǔn)性能
該團(tuán)隊(duì)在大量基準(zhǔn)上對(duì)比了 NSA 與 Full Attention 的表現(xiàn)。結(jié)果見下表 1。
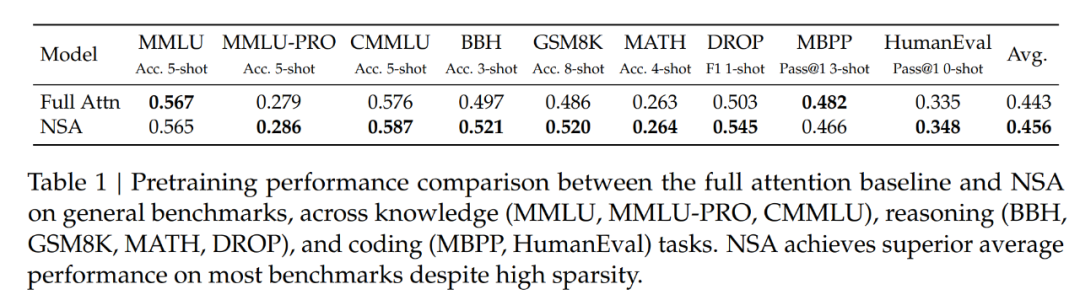
可以看到,盡管 NSA 比較稀疏,但它實(shí)現(xiàn)了卓越的整體性能,在 9 個(gè)指標(biāo)中的 7 個(gè)上都優(yōu)于包括 Full Attention 在內(nèi)的所有基線。
這表明,盡管 NSA 可能無法充分利用其在較短序列上的效率優(yōu)勢(shì),但它依然表現(xiàn)出了強(qiáng)勁的性能。值得注意的是,NSA 在推理相關(guān)基準(zhǔn)測(cè)試中表現(xiàn)出了顯著的提升(DROP:+0.042,GSM8K:+0.034),這表明 DeepSeek 的預(yù)訓(xùn)練有助于模型發(fā)展出專門的注意力機(jī)制。通過過濾掉不相關(guān)的注意力路徑中的噪音,這種稀疏注意力預(yù)訓(xùn)練機(jī)制可迫使模型專注于最重要的信息,有可能提高性能。在不同評(píng)估中的一致表現(xiàn)也證明了 NSA 作為通用架構(gòu)的穩(wěn)健性。
長(zhǎng)上下文基準(zhǔn)性能
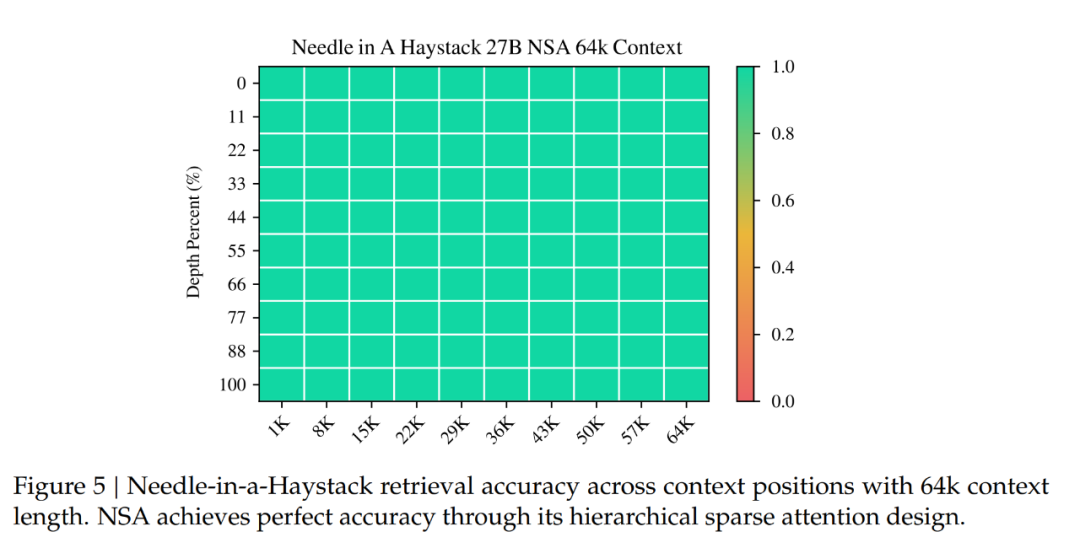
下圖 5 展示了 NSA 在 64k 上下文的大海撈針(needle-in-a-haystack) 測(cè)試中的結(jié)果,它在所有位置上都實(shí)現(xiàn)了完美的檢索準(zhǔn)確率。
這一性能源于 DeepSeek 團(tuán)隊(duì)的分層稀疏注意力設(shè)計(jì),該設(shè)計(jì)結(jié)合壓縮 token 來實(shí)現(xiàn)高效的全局上下文掃描,以及結(jié)合選擇 token 來實(shí)現(xiàn)精確的局部信息檢索。粗粒度壓縮以較低的計(jì)算成本識(shí)別相關(guān)的上下文塊,而對(duì)選定 token 的 token 級(jí)注意力可確保關(guān)鍵細(xì)粒度信息的保留。這種設(shè)計(jì)使得 NSA 能夠同時(shí)保持全局意識(shí)和局部精度。
作者還在 LongBench 上對(duì) NSA 進(jìn)行了評(píng)估,并與 SOTA 稀疏注意力方法和 Full Attention 基線進(jìn)行了比較。為了確保一致的稀疏性,他們將所有稀疏注意力基線中每個(gè)查詢激活的 token 設(shè)置為 2560 個(gè) tokens,這對(duì)應(yīng)于 NSA 在處理 32k 序列長(zhǎng)度時(shí)激活的 token 的平均數(shù)量。按照 StreamLLM,此 token 預(yù)算包括前 128 個(gè) tokens 和 512 個(gè)本地 tokens。
作者從 LongBench 中排除了某些子集,因?yàn)樗鼈冊(cè)谒心P椭械牡梅侄驾^低,可能無法提供有意義的比較。結(jié)果如下表 2 所示,NSA 獲得了最高平均分?jǐn)?shù) 0.469,優(yōu)于所有基線,其中比 Full Attention 高出 0.032,比 Exact-Top 高出 0.046。
這一改進(jìn)源于兩個(gè)關(guān)鍵創(chuàng)新,分別是(1)原生的稀疏注意力設(shè)計(jì),能夠在預(yù)訓(xùn)練期間對(duì)稀疏模式進(jìn)行端到端優(yōu)化,促進(jìn)稀疏注意力模塊與其他模型組件之間的同步適應(yīng);(2)分層稀疏注意力機(jī)制實(shí)現(xiàn)了局部和全局信息處理之間的平衡。
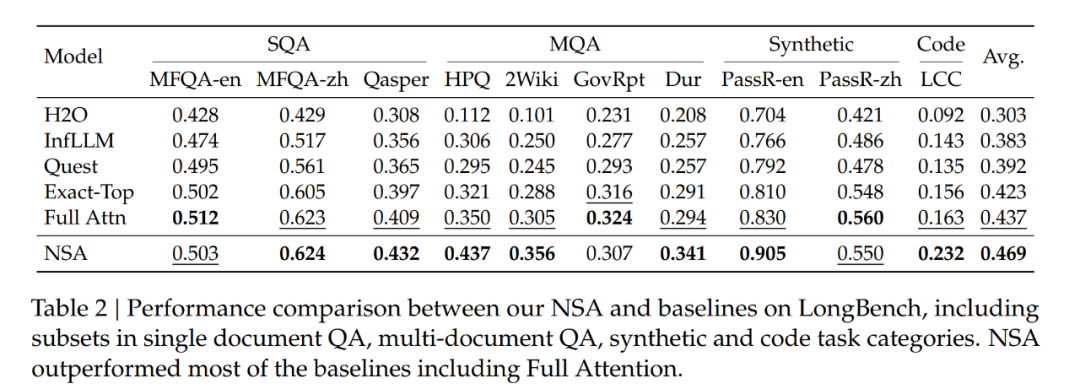
值得注意的是,NSA 在需要對(duì)長(zhǎng)上下文進(jìn)行復(fù)雜推理的任務(wù)上表現(xiàn)出色,在兩項(xiàng)多跳 QA 任務(wù)(HPQ 和 2Wiki)上比 Full Attention 實(shí)現(xiàn)了 + 0.087 和 +0.051 的改進(jìn),在代碼理解方面超過了基線(LCC 上實(shí)現(xiàn) + 0.069 的改進(jìn)),并在段落檢索方面優(yōu)于其他方法(PassR-en 上實(shí)現(xiàn) + 0.075 的改進(jìn))。
這些結(jié)果驗(yàn)證了 NSA 處理各種長(zhǎng)上下文任務(wù)中的能力,其原生預(yù)訓(xùn)練的稀疏注意力在學(xué)習(xí)任務(wù)最優(yōu)模式方面提供了額外的助益。
思維鏈推理性能評(píng)估
為了評(píng)估 NSA 與前沿下游訓(xùn)練范式的兼容性,作者研究了其通過后訓(xùn)練獲得思維鏈數(shù)學(xué)推理能力的能力。
鑒于強(qiáng)化學(xué)習(xí)在較小模型上的有效性有限,作者從 DeepSeek-R1 進(jìn)行知識(shí)蒸餾,用 100 億個(gè) 32k 長(zhǎng)度的數(shù)學(xué)推理軌跡進(jìn)行監(jiān)督微調(diào)(SFT)。
這產(chǎn)生了兩個(gè)可比較的模型:Full Attention-R(全注意力基線)和 NSA-R(NSA 的稀疏變體)。
然后,作者在具有挑戰(zhàn)性的美國(guó)數(shù)學(xué)邀請(qǐng)賽(AIME 24)基準(zhǔn)上評(píng)估這兩個(gè)模型。使用采樣溫度為 0.7 和 top-??值為 0.95 的配置,為每個(gè)問題生成 16 個(gè)回答,并計(jì)算平均得分。為了驗(yàn)證推理深度的影響,作者在兩種生成上下文限制下進(jìn)行實(shí)驗(yàn):8k 和 16k token,測(cè)量擴(kuò)展的推理鏈?zhǔn)欠裉岣吡藴?zhǔn)確性。模型預(yù)測(cè)的示例比較見附錄 A。
如表 3 所示,在 8k 上下文設(shè)置下,NSA-R 的準(zhǔn)確性顯著高于 Full Attention-R(+0.075),這一優(yōu)勢(shì)在 16k 上下文設(shè)置下仍然保持(+0.054)。
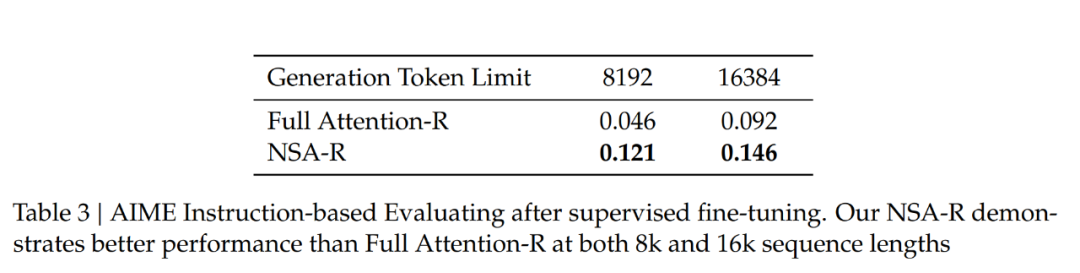
這些結(jié)果驗(yàn)證了原生稀疏注意力的兩個(gè)關(guān)鍵優(yōu)勢(shì):
(1)預(yù)訓(xùn)練的稀疏注意力模式能夠高效捕捉對(duì)復(fù)雜數(shù)學(xué)推導(dǎo)至關(guān)重要的長(zhǎng)距離邏輯依賴關(guān)系;
(2)該架構(gòu)的硬件對(duì)齊設(shè)計(jì)保持了足夠的上下文密度,以支持不斷增長(zhǎng)的推理深度,而不會(huì)出現(xiàn)災(zāi)難性遺忘。在不同上下文長(zhǎng)度下的一致優(yōu)勢(shì)證實(shí)了稀疏注意力在原生集成到訓(xùn)練流程中時(shí),對(duì)于高級(jí)推理任務(wù)的可行性。
效率分析
作者在一個(gè) 8-GPU A100 系統(tǒng)上評(píng)估了 NSA 相對(duì)于 Full Attention 的計(jì)算效率。
訓(xùn)練速度
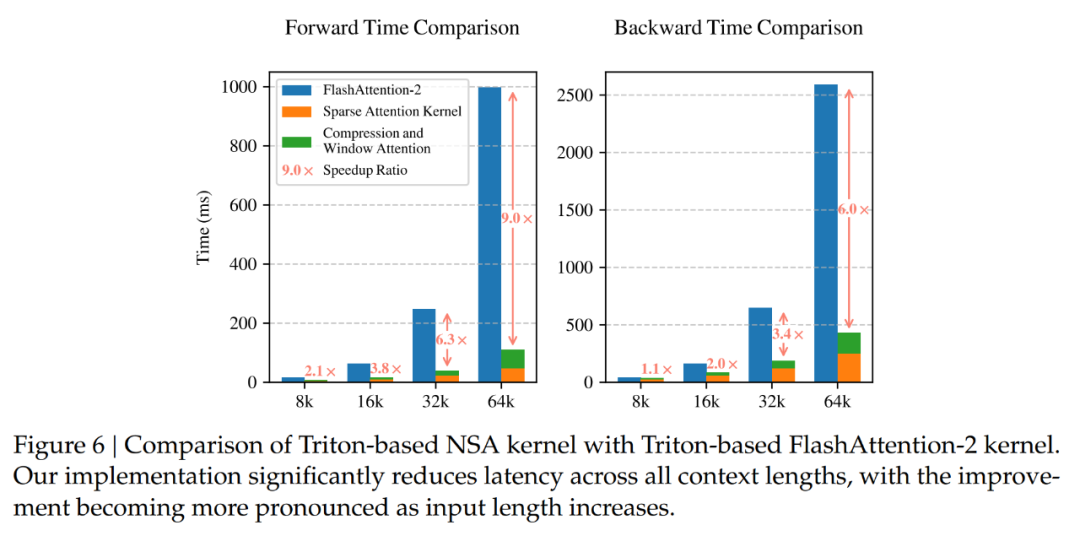
為了確保在相同后端下進(jìn)行公平的速度比較,作者將基于 Triton 的 NSA 注意力和 Full Attention 實(shí)現(xiàn)與基于 Triton 的 FlashAttention-2 進(jìn)行對(duì)比。如圖 6 所示,隨著上下文長(zhǎng)度的增加,NSA 實(shí)現(xiàn)了越來越大的加速,在 64k 上下文長(zhǎng)度下實(shí)現(xiàn)了 9.0 倍的前向加速和 6.0 倍的反向加速。
值得注意的是,序列越長(zhǎng),速度優(yōu)勢(shì)就越明顯。這種加速源于 DeepSeek 的硬件對(duì)齊算法設(shè)計(jì),其能最大限度地提高稀疏注意力架構(gòu)的效率:(1) 分塊式內(nèi)存訪問模式通過合并加載最大限度地利用了 Tensor Core;(2) 內(nèi)核中精細(xì)的循環(huán)調(diào)度消除了冗余的 KV 傳輸。
解碼速度
注意力機(jī)制的解碼速度主要由內(nèi)存訪問瓶頸決定,這與 KV 緩存加載量密切相關(guān)。
在每一步解碼過程中,NSA 最多只需要加載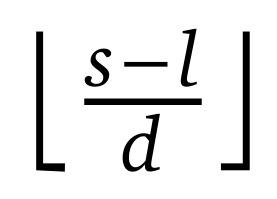 個(gè)壓縮 token、????′個(gè)選定的 token 以及??個(gè)鄰近 token,其中??是緩存的序列長(zhǎng)度。如表 4 所示,隨著解碼長(zhǎng)度的增加,該方法在延遲方面表現(xiàn)出顯著的減少,在 64k 上下文長(zhǎng)度下實(shí)現(xiàn)了高達(dá) 11.6 倍的加速。
個(gè)壓縮 token、????′個(gè)選定的 token 以及??個(gè)鄰近 token,其中??是緩存的序列長(zhǎng)度。如表 4 所示,隨著解碼長(zhǎng)度的增加,該方法在延遲方面表現(xiàn)出顯著的減少,在 64k 上下文長(zhǎng)度下實(shí)現(xiàn)了高達(dá) 11.6 倍的加速。
這種內(nèi)存訪問效率的優(yōu)勢(shì)在序列長(zhǎng)度增加時(shí)也會(huì)進(jìn)一步放大。

關(guān)于此研究的更多內(nèi)容,大家可以查看原論文。





























