













嚯!大語言擴散模型來了,何必只預(yù)測下一個token | 人大高瓴&螞蟻
用擴散模型替代自回歸,大模型的逆詛咒有解了!
人大高瓴人工智能研究院、螞蟻共同提出LLaDA(a Large Language Diffusion with mAsking)。
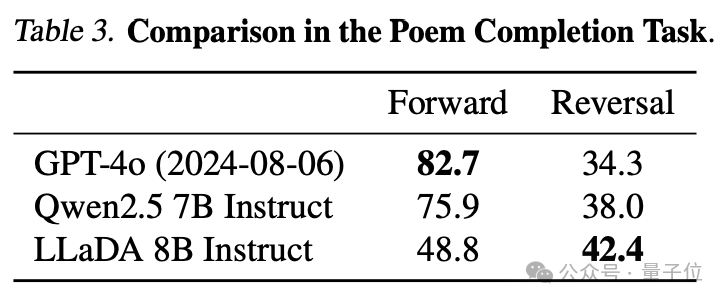
LLaDA-8B在上下文學(xué)習(xí)方面與LLaMA3-8B能力相當(dāng),而且在反轉(zhuǎn)詩歌任務(wù)中超越GPT-4o。
在大語言模型領(lǐng)域,反轉(zhuǎn)詩歌是一個特殊任務(wù),它用來評估模型在處理語言模型的雙向依賴關(guān)系和邏輯推理能力。
比如讓大模型寫出“一行白鷺上青天”的上一句。
通常情況,自回歸模型(如GPT)根據(jù)下文推斷上文的表現(xiàn)上總是不夠好。這是因為自回歸模型的原理就是利用序列中前面的元素來預(yù)測當(dāng)前元素,即預(yù)測下一個token。
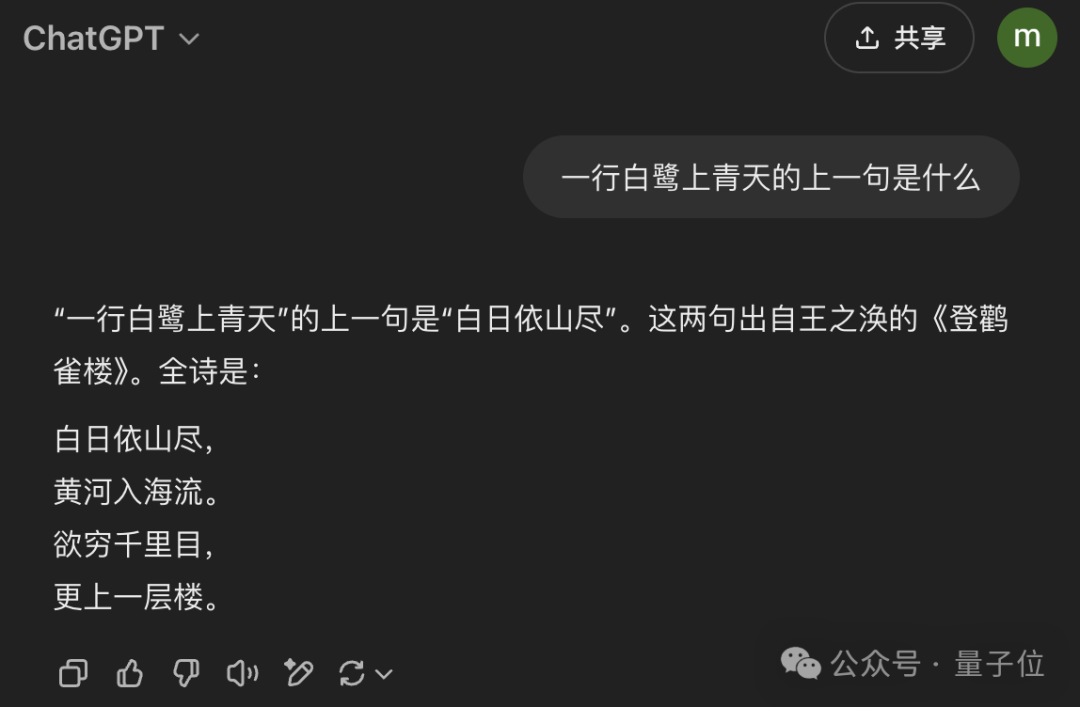
而LLaDA是基于擴散模型的雙向模型,天然能夠更好捕捉文本的雙向依賴關(guān)系。
作者在摘要中表示:LLaDA挑戰(zhàn)了LLMs關(guān)鍵能力與自回歸模型之間的固有聯(lián)系。
這些研究也引發(fā)了不少討論。
有人提出:
我們正在重構(gòu)掩碼語言模型建模?
RAG和嵌入式相似性搜索上,這種范式也可能表現(xiàn)更好?

值得一提的是,LLaDA僅用13萬H800GPU時訓(xùn)練了2.3萬億token語料,然后對450萬對token進行SFT。
正向掩碼+反向預(yù)測
論文核心提出了一個問題:自回歸是否是實現(xiàn)LLMs智能的唯一路徑?
畢竟自回歸范式的LLMs目前仍存在諸多弊端,比如逐個生成token的機制導(dǎo)致計算成果很高,從左到右建模限制了逆推理任務(wù)中的性能。
這都限制了了LLMs處理更長、更復(fù)雜任務(wù)的能力。
為此,他們提出了LLaDA。通過正向掩碼和反向預(yù)測機制,讓模型更好捕捉文本的雙向依賴關(guān)系。

研究采用標(biāo)準(zhǔn)的數(shù)據(jù)準(zhǔn)備、預(yù)訓(xùn)練、監(jiān)督微調(diào)(SFT)和評估流程,將LLaDA擴展到80億參數(shù)。
在2.3萬億token上從零開始預(yù)訓(xùn)練,使用13萬H800 GPU時,隨后在450萬對數(shù)據(jù)上進行監(jiān)督微調(diào)。
在語言理解、數(shù)學(xué)、代碼和中文等多樣化任務(wù)中,表現(xiàn)如下:
強大可擴展性:LLaDA 能夠有效擴展到1023 FLOPs計算資源上,在六個任務(wù)(例如MMLU和GSM8K)上,與在相同數(shù)據(jù)上訓(xùn)練的自建自回歸基線模型結(jié)果相當(dāng)。
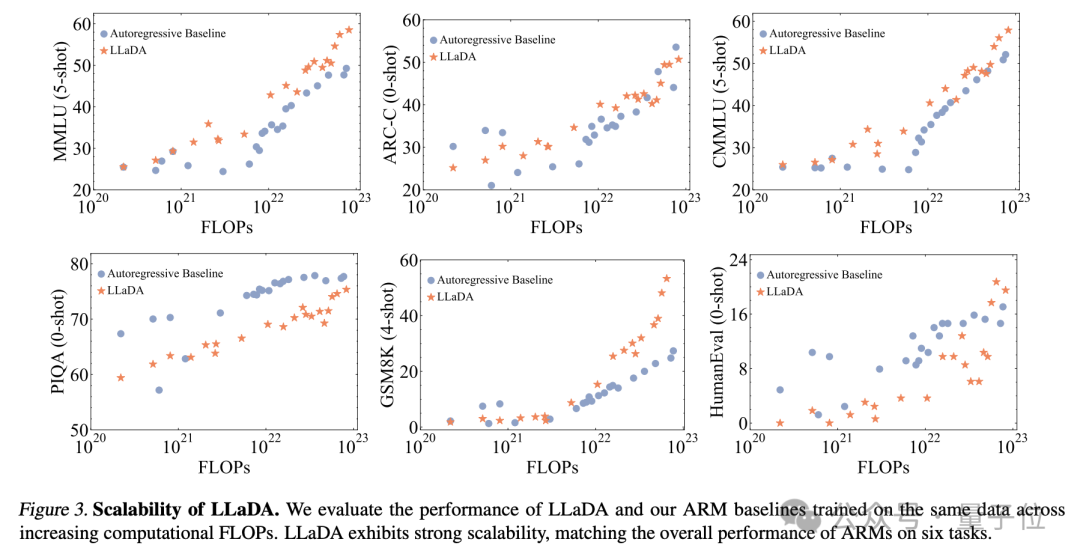
上下文學(xué)習(xí):值得注意的是,LLaDA-8B 在幾乎所有 15 個標(biāo)準(zhǔn)的零樣本/少樣本學(xué)習(xí)任務(wù)上都超越了 LLaMA2-7B,并且與 LLaMA3-8B表現(xiàn)相當(dāng)。
指令遵循:LLaDA在SFT后顯著增強了指令遵循能力,這在多輪對話等案例研究中得到了展示。
反轉(zhuǎn)推理:LLaDA有效地打破了反轉(zhuǎn)詛咒,在正向和反轉(zhuǎn)任務(wù)上表現(xiàn)一致。特別是在反轉(zhuǎn)詩歌完成任務(wù)中,LLaDA 的表現(xiàn)優(yōu)于 GPT-4o。

LLaDA使用Transformer架構(gòu)作為掩碼預(yù)測器。與自回歸模型不同,LLaDA的transformer不使用因果掩碼(Causal Mask),因此它可以同時看到輸入序列中的所有token。
模型參數(shù)量與傳統(tǒng)大語言模型(如GPT)相當(dāng),但架構(gòu)細(xì)節(jié)(如多頭注意力的設(shè)置)略有不同,以適應(yīng)掩碼預(yù)測任務(wù)。
其正向掩碼過程如下:
LLaDA采用隨機掩碼機制,對一個輸入序列x0,模型會隨機選擇一定比例的標(biāo)記進行掩碼(masking),生成部分掩碼的序列xt。
每個token被掩碼的概率為t,其中t是從[0,1]中均勻采樣的。這與傳統(tǒng)的固定掩碼比例(如BERT中的15%)不同,LLaDA的隨機掩碼機制在大規(guī)模數(shù)據(jù)上表現(xiàn)出更好的性能。
模型的目標(biāo)是學(xué)習(xí)一個掩碼預(yù)測器,能夠根據(jù)部分掩碼的序列xt預(yù)測出被掩碼的token。訓(xùn)練時,模型只對被掩碼的token計算損失。
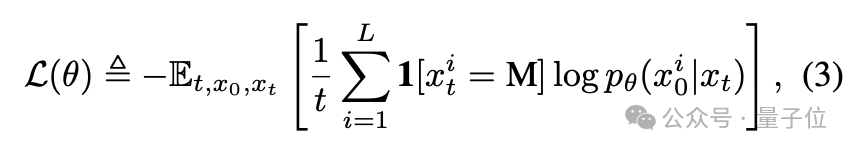
其中1[·]是指示函數(shù),表示只對被掩碼的token計算損失。
在SFT階段,LLaDA使用監(jiān)督數(shù)據(jù)(如對話對、指令-響應(yīng)對)進一步優(yōu)化模型,使其在特定任務(wù)上表現(xiàn)更好。
對于每個任務(wù),模型會根據(jù)任務(wù)數(shù)據(jù)的特點進行微調(diào)。例如在對話生成式任務(wù)中,模型會學(xué)習(xí)如何根據(jù)給定對話歷史生成合適響應(yīng)。
在SFT階段,模型會根據(jù)任務(wù)數(shù)據(jù)的特點選擇性地掩碼響應(yīng)部分token,這使得模型能夠更好地學(xué)習(xí)任務(wù)相關(guān)的模式。
推理部分,在生成任務(wù)中,LLaDA通過反向采樣過程生成文本。從一個完全掩碼的序列開始,逐步預(yù)測出被掩碼的token,直到生成完整的文本。
采樣過程中,LLaDA采用多種策略(如隨機重掩碼、低置信度重掩碼、半自回歸重掩碼)來平衡生成效率和質(zhì)量。
在條件概率評估任務(wù)中,LLaDA會根據(jù)給定的提示(prompt)和部分掩碼的響應(yīng)(response)來評估模型的條件概率。這使得LLaDA能夠在各種基準(zhǔn)任務(wù)上進行性能評估。
預(yù)訓(xùn)練LLM在不同基準(zhǔn)上的表現(xiàn)如下。
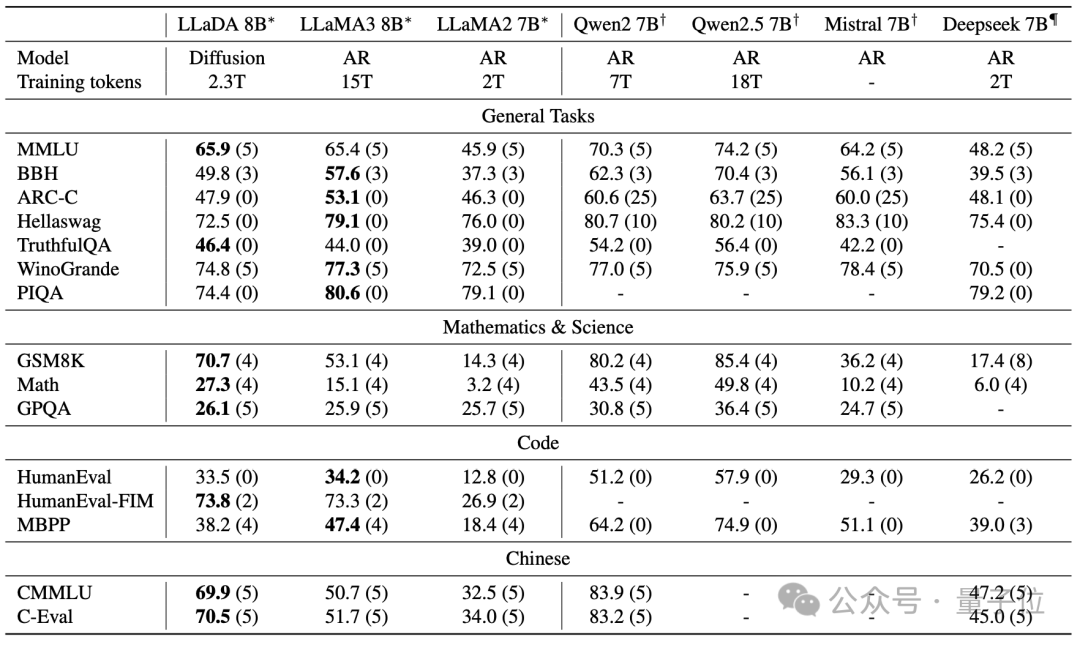
后訓(xùn)練后在不同benchmark上的表現(xiàn)如下。其中LLaDA只進行了SFT,其他模型有進行額外的強化學(xué)習(xí)對齊。

在反轉(zhuǎn)詩歌任務(wù)中,LLaDA超越了GPT-4o。
在多輪對話任務(wù)中LLaDA的表現(xiàn)如下,較深顏色表示采樣后期階段預(yù)測的token,較淺顏色表示在采樣早期預(yù)測的token。

網(wǎng)友:期待能被真正用起來
研究團隊同時放出了一些LLaDA的實際表現(xiàn)。
可以解決普通的數(shù)學(xué)推理問題。

編程問題也OK。
有國外網(wǎng)友表示:這肯定會推動中國AI研究更加關(guān)注小模型。不過也不代表他們放棄scaling。

同時也有人評價說,這或許可以開啟一些混合模型的可能。

以及有人提及Meta也有過類似的工作,將transformer和diffusion相結(jié)合。

當(dāng)然也有人關(guān)心,此前也提出了不少超越Transformer的架構(gòu),但是它們都還沒有被學(xué)術(shù)界/工業(yè)界真正采納。
讓我們期待后續(xù)吧。

本項研究由人大高瓴人工智能學(xué)院與螞蟻集團共同帶來。通訊作者為李崇軒,他目前為人大高瓴人工智能學(xué)院準(zhǔn)聘副教授,目前focuses的方向為深度生成模型,了解現(xiàn)有模型的能力和局限,設(shè)計有效且可擴展的下一代模型。
論文地址:https://arxiv.org/abs/2502.09992
項目主頁:https://ml-gsai.github.io/LLaDA-demo/



















