













LeCun贊轉(zhuǎn)!類Sora模型能否理解物理規(guī)律?字節(jié)豆包大模型團(tuán)隊(duì)系統(tǒng)性研究揭秘
視頻生成模型雖然可以生成一些看似符合常識(shí)的視頻,但被證實(shí)目前還無(wú)法理解物理規(guī)律!
自從 Sora 橫空出世,業(yè)界便掀起了一場(chǎng)「視頻生成模型到底懂不懂物理規(guī)律」的爭(zhēng)論。圖靈獎(jiǎng)得主 Yann LeCun 明確表示,基于文本提示生成的逼真視頻并不代表模型真正理解了物理世界。之后更是直言,像 Sora 這樣通過(guò)生成像素來(lái)建模世界的方式注定要失敗。

Keras 之父 Fran?ois Chollet 則認(rèn)為,Sora 這樣的視頻生成模型確實(shí)嵌入了「物理模型」,但問(wèn)題是:這個(gè)物理模型是否準(zhǔn)確?它能否泛化到新的情況,即那些不僅僅是訓(xùn)練數(shù)據(jù)插值的情形?這些問(wèn)題至關(guān)重要,決定了生成圖像的應(yīng)用范圍 —— 是僅限于媒體生產(chǎn),還是可以用作現(xiàn)實(shí)世界的可靠模擬。最后他指出,不能簡(jiǎn)單地通過(guò)擬合大量數(shù)據(jù)來(lái)期望得到一個(gè)能夠泛化到現(xiàn)實(shí)世界所有可能情況的模型。

此后,關(guān)于視頻生成模型到底有沒(méi)有在學(xué)習(xí)、理解物理規(guī)律,業(yè)界始終沒(méi)有一個(gè)定論。直到近日,字節(jié)豆包大模型團(tuán)隊(duì)公布的一項(xiàng)系統(tǒng)性研究,為兩者之間的關(guān)系「劃上了不等號(hào)」。
該團(tuán)隊(duì)通過(guò)大規(guī)模實(shí)驗(yàn)發(fā)現(xiàn) —— 即便依照 Scaling Law 擴(kuò)大模型參數(shù)與訓(xùn)練數(shù)據(jù)量,模型依然無(wú)法抽象出一般物理規(guī)則,甚至連牛頓第一定律、拋物線運(yùn)動(dòng)都無(wú)法領(lǐng)會(huì)。
「視頻生成模型目前就像一個(gè)只會(huì)『抄作業(yè)』的學(xué)生,可以記憶案例,但還無(wú)法真正理解物理規(guī)律,做到『舉一反三』。因此,模型遇到未學(xué)習(xí)過(guò)的場(chǎng)景就會(huì)『犯迷糊』,生成結(jié)果與物理規(guī)則不符。」研究作者表示。
相關(guān)推文在 X 發(fā)布后,獲得 Yann LeCun 點(diǎn)贊轉(zhuǎn)發(fā),還評(píng)價(jià)道 —— 結(jié)果雖不意外,但有人嘗試研究確實(shí)是一件好事。
此外,CV 大牛謝賽寧和常年活躍的 Gary Marcus 等人也紛紛跟進(jìn)關(guān)注。

- 論文標(biāo)題:How Far is Video Generation from World Model: A Physical Law Perspective
- 論文鏈接:https://arxiv.org/abs/2411.02385
- 展示頁(yè)面:https://phyworld.github.io

Sora 的世界里,物理學(xué)存在么?
此前 Sora 發(fā)布時(shí),OpenAI 就在其宣傳頁(yè)面寫道:我們的成果揭示了 —— 提升視頻生成模型參數(shù)與數(shù)據(jù)量,為構(gòu)建物理世界通用模擬器,提供了一條可行之路。

給人希望的同時(shí),業(yè)內(nèi)質(zhì)疑聲紛至沓來(lái),很多人并不認(rèn)為基于 DiT 架構(gòu)的視頻生成模型能夠真正理解物理規(guī)律。其中尤以 LeCun 為代表,一直以來(lái),這位人工智能巨頭一直堅(jiān)稱,基于概率的大語(yǔ)言模型無(wú)法理解常識(shí),其中包括現(xiàn)實(shí)物理規(guī)律。
盡管大家眾說(shuō)紛紜,但市面上,系統(tǒng)性針對(duì)該問(wèn)題的研究一直寥寥。出于對(duì)這一課題的好奇,字節(jié)豆包大模型相關(guān)團(tuán)隊(duì)于 2024 年初啟動(dòng)了這一研究立項(xiàng),并歷經(jīng) 8 個(gè)月終于完成系統(tǒng)性實(shí)驗(yàn)。
原理與實(shí)驗(yàn)設(shè)計(jì)
在本次工作中,如何定量分析視頻生成模型對(duì)于物理規(guī)律的理解,是一大挑戰(zhàn)。
豆包大模型團(tuán)隊(duì)通過(guò)專門開發(fā)的物理引擎合成了勻速直接運(yùn)動(dòng)、小球碰撞、拋物線運(yùn)動(dòng)等經(jīng)典物理場(chǎng)景的運(yùn)動(dòng)視頻,用于訓(xùn)練基于主流 DiT 架構(gòu)的視頻生成模型。然后,通過(guò)檢驗(yàn)?zāi)P秃罄m(xù)生成的視頻在運(yùn)動(dòng)和碰撞方面是否符合力學(xué)定律,判斷模型是否真正理解了物理規(guī)律,并具有「世界模型」的潛力。
針對(duì)視頻生成模型在學(xué)習(xí)物理定律時(shí)的泛化能力,團(tuán)隊(duì)探討了下面三種場(chǎng)景的表現(xiàn):
- 分布內(nèi)泛化 (In-Distribution, ID):指訓(xùn)練數(shù)據(jù)和測(cè)試數(shù)據(jù)來(lái)自同一分布。
- 分布外泛化 (Out-of-Distribution, OOD) :分布外泛化指的是模型在面對(duì)從未見過(guò)的新場(chǎng)景時(shí),是否能夠?qū)⒁褜W(xué)過(guò)的物理定律應(yīng)用到未知的情境。
- 組合泛化 (Combinatorial Generalization):組合泛化介于 ID 和 OOD 之間,此種情況下,訓(xùn)練數(shù)據(jù)已包含了所有「概念」或物體,但這些概念、物體并未以所有可能的組合或更復(fù)雜的形式出現(xiàn)。
在基于視頻的觀察中,每一幀代表一個(gè)時(shí)間點(diǎn),物理定律的預(yù)測(cè)則對(duì)應(yīng)于根據(jù)過(guò)去和現(xiàn)在的幀生成未來(lái)的幀。因此,團(tuán)隊(duì)在每個(gè)實(shí)驗(yàn)中都訓(xùn)練一個(gè)基于幀條件的視頻生成模型,來(lái)模擬和預(yù)測(cè)物理現(xiàn)象的演變。
通過(guò)測(cè)量生成視頻每個(gè)幀(時(shí)間點(diǎn))中物體位置變化,可判斷其運(yùn)動(dòng)狀態(tài),進(jìn)而與真實(shí)模擬的視頻數(shù)據(jù)比對(duì),判斷生成內(nèi)容是否符合經(jīng)典物理學(xué)的方程表達(dá)。
實(shí)驗(yàn)設(shè)計(jì)方面,團(tuán)隊(duì)聚焦于由基本運(yùn)動(dòng)學(xué)方程支配的確定性任務(wù)。這些任務(wù)能清晰定義分布內(nèi) (ID) 和分布外 (OOD) 泛化,并且能夠進(jìn)行直觀的誤差量化評(píng)估。
團(tuán)隊(duì)選擇了以下三種物理場(chǎng)景進(jìn)行評(píng)估,每種運(yùn)動(dòng)由其初始幀決定:
- 勻速直線運(yùn)動(dòng):一個(gè)球水平移動(dòng),速度保持恒定,用于說(shuō)明慣性定律。
- 完美彈性碰撞:兩個(gè)具有不同大小和速度的球水平相向運(yùn)動(dòng)并發(fā)生碰撞,體現(xiàn)了能量與動(dòng)量守恒定律。
- 拋物線運(yùn)動(dòng):一個(gè)帶有初始水平速度的球因重力作用下落,符合牛頓第二定律。
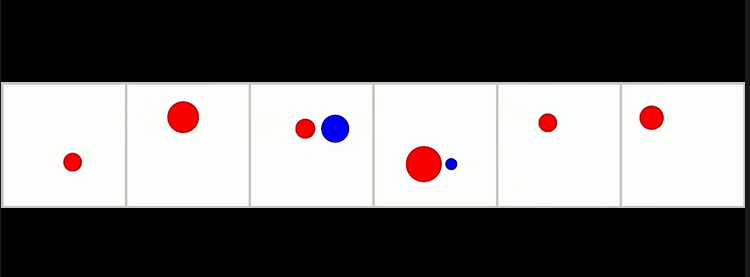
針對(duì)組合泛化場(chǎng)景,團(tuán)隊(duì)使用 PHYRE 模擬器評(píng)估模型的組合泛化能力。PHYRE 是一個(gè)二維模擬環(huán)境,其中包括球、罐子、桿子和墻壁等多個(gè)對(duì)象,它們可以是固定或動(dòng)態(tài)的,且能進(jìn)行碰撞、拋物線軌跡、旋轉(zhuǎn)等復(fù)雜物理交互,但環(huán)境中的底層物理規(guī)律是確定性的。
視頻數(shù)據(jù)構(gòu)造方面,每一個(gè)視頻考慮了八種物體,包括兩個(gè)動(dòng)態(tài)灰色球、一組固定的黑色球、一個(gè)固定的黑色條形、一個(gè)動(dòng)態(tài)條形、一組動(dòng)態(tài)立式條形、一個(gè)動(dòng)態(tài)罐子和一個(gè)動(dòng)態(tài)立式棍子。
每個(gè)任務(wù)包含一個(gè)紅色球和從這八種類型中隨機(jī)選擇的四個(gè)物體,總共形成 種獨(dú)特的模板。數(shù)據(jù)示例如下:
種獨(dú)特的模板。數(shù)據(jù)示例如下:
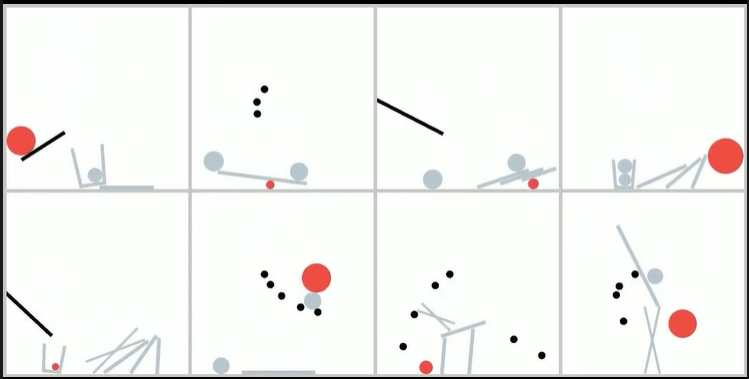
對(duì)于每個(gè)訓(xùn)練模板,團(tuán)隊(duì)保留了一小部分視頻用于創(chuàng)建模板內(nèi)測(cè)試集(in-template evaluation set),再保留 10 個(gè)未使用的模板,用于模板外測(cè)試集(out-of-template evaluation set),以評(píng)估模型對(duì)訓(xùn)練時(shí)未見過(guò)的新組合的泛化能力。
實(shí)驗(yàn)結(jié)果與分析
豆包大模型團(tuán)隊(duì)的實(shí)驗(yàn)發(fā)現(xiàn),即使遵循「Scaling Law」增大模型參數(shù)規(guī)模和數(shù)據(jù)量,模型依然無(wú)法抽象出一般物理規(guī)則,做到真正「理解」。
以最簡(jiǎn)單的勻速直線運(yùn)動(dòng)為例,當(dāng)模型學(xué)習(xí)了不同速度下小球保持勻速直線運(yùn)動(dòng)的訓(xùn)練數(shù)據(jù)后,給定初始幾幀,要求模型生成小球在訓(xùn)練集速度區(qū)間內(nèi)勻速直線運(yùn)動(dòng)的視頻,隨著模型參數(shù)和訓(xùn)練數(shù)據(jù)量的增加,生成的視頻逐漸更符合物理規(guī)律。
然而,當(dāng)要求模型生成未曾見過(guò)的速度區(qū)間(即超出訓(xùn)練數(shù)據(jù)范圍)的運(yùn)動(dòng)視頻時(shí),模型突然不再遵循物理規(guī)律,并且無(wú)論如何增加模型參數(shù)或訓(xùn)練數(shù)據(jù),生成的結(jié)果都沒(méi)有顯著改進(jìn)。這表明,視頻生成模型無(wú)法真正理解物理規(guī)律,也無(wú)法將這些規(guī)律泛化應(yīng)用到全新的場(chǎng)景中。
不過(guò),研究中也有一個(gè)好消息:如果訓(xùn)練視頻中所有概念和物體都是模型已熟悉的,此時(shí)加大訓(xùn)練視頻的復(fù)雜度,比如組合增加物體間的物理交互,通過(guò)加大訓(xùn)練數(shù)據(jù),模型對(duì)物理規(guī)律的遵循將越來(lái)越好。這一結(jié)果可為視頻生成模型繼續(xù)提升表現(xiàn)提供啟發(fā)。
具體而言,在分布內(nèi)泛化(ID)的測(cè)試中,團(tuán)隊(duì)觀察到,隨著模型規(guī)模增大(從 DiT-S 到 DiT-L)或訓(xùn)練數(shù)據(jù)量的增加(從 30K 到 3M),模型在所有三種物理任務(wù)中的速度誤差都降低。這表明,模型規(guī)模和數(shù)據(jù)量的增加對(duì)分布內(nèi)泛化至關(guān)重要。
然而,分布外泛化(OOD)與分布內(nèi)泛化(ID)結(jié)果形成鮮明對(duì)比:
- 更高的誤差:在所有設(shè)置中,OOD 速度誤差比 ID 高出一個(gè)數(shù)量級(jí) (~0.02 v.s. ~0.3)。
- 擴(kuò)展數(shù)據(jù)和模型規(guī)模的影響有限:與分布內(nèi)泛化不同,擴(kuò)展訓(xùn)練數(shù)據(jù)和模型規(guī)模對(duì)降低 OOD 誤差幾乎沒(méi)有影響。這表明,簡(jiǎn)單的數(shù)據(jù)量和模型規(guī)模的增加無(wú)法有效提升模型在 OOD 場(chǎng)景中的推理能力。

至于組合泛化場(chǎng)景,從下表可看到,當(dāng)模板數(shù)量從 6 個(gè)增加到 60 個(gè)時(shí),所有度量指標(biāo)(FVD、SSIM、PSNR、LPIPS)在模版外測(cè)試集上均顯著的提升。尤其是異常率(生成視頻違背物理定律的比例),從 67% 大幅下降至 10%。這表明,當(dāng)訓(xùn)練集覆蓋了更多組合場(chǎng)景時(shí),模型能夠在未見過(guò)的組合中展現(xiàn)出更強(qiáng)的泛化能力。
然而,對(duì)于模板內(nèi)測(cè)試集,模型在 6 個(gè)模板的訓(xùn)練集上的 SSIM、PSNR 和 LPIPS 等指標(biāo)上表現(xiàn)最佳,因?yàn)槊總€(gè)訓(xùn)練示例被反復(fù)展示。

這些結(jié)果表明,模型容量和組合空間的覆蓋范圍對(duì)組合泛化至關(guān)重要。這意味著,視頻生成的 Scaling Law 應(yīng)當(dāng)側(cè)重于增加組合多樣性,而不僅僅是擴(kuò)大數(shù)據(jù)量。
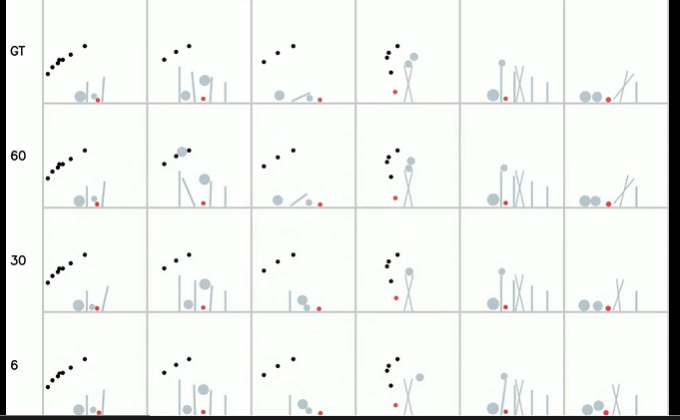
圖注:在模版外測(cè)試集上生成的樣本視頻。第一行:真實(shí)視頻。第二行:使用 60 個(gè)模板訓(xùn)練的模型生成的視頻。第三行:使用 30 個(gè)模板訓(xùn)練的模型生成的視頻。第四行:使用 6 個(gè)模板訓(xùn)練的模型生成的視頻。
機(jī)理探究:模型如何依賴記憶和案例模仿
前文提及,視頻生成模型對(duì)于分布外泛化表現(xiàn)不佳,但在組合場(chǎng)景下,數(shù)據(jù)和模型 Scaling 可帶來(lái)一定提升,這究竟來(lái)自于案例學(xué)習(xí),還是對(duì)底層規(guī)律的抽象理解?團(tuán)隊(duì)著手進(jìn)行了相關(guān)實(shí)驗(yàn)。
- 模型似乎更多依賴記憶和案例模仿
使用勻速運(yùn)動(dòng)視頻進(jìn)行訓(xùn)練,速度范圍為 v∈[2.5, 4.0],并使用前 3 幀作為輸入條件。我們使用兩個(gè)數(shù)據(jù)集訓(xùn)練,再對(duì)照結(jié)果,Set-1 只包含從左到右移動(dòng)的球,而 Set-2 則包含從左到右移動(dòng)的球和從右到左移動(dòng)的球。
如下圖所示,給定進(jìn)行低速正向(從左到右)運(yùn)動(dòng)的幀條件,Set-1 模型生成視頻只有正速度,且偏向高速范圍。相比之下,Set-2 模型偶爾會(huì)生成負(fù)速度的視頻,正如圖中綠色圓圈所示。

面對(duì)兩者之間的區(qū)別,團(tuán)隊(duì)猜測(cè),這可能是由于模型認(rèn)為,與低速度球更接近的是訓(xùn)練數(shù)據(jù)中反方向運(yùn)動(dòng)的小球,導(dǎo)致模型受到訓(xùn)練數(shù)據(jù)中「誤導(dǎo)性」示例影響。換而言之,模型似乎更多依賴于記憶和案例模仿,而非抽象出普遍的物理規(guī)則,實(shí)現(xiàn)分布外泛化(OOD)。
- 模型更多靠顏色尋找模仿對(duì)象
在前文,我們已探索獲知 —— 模型更多依賴記憶和相似案例進(jìn)行模仿并生成視頻,更進(jìn)一步,則須分析哪些屬性對(duì)其模仿影響較大。
在比對(duì)顏色、形狀、大小和速度四個(gè)屬性后,團(tuán)隊(duì)發(fā)現(xiàn),基于擴(kuò)散技術(shù)的的視頻生成模型天生更偏向其他屬性而非形狀,這也可能解釋了為什么當(dāng)前的開放集視頻生成模型通常在形狀保持上存在困難。
如下圖,第一行是真實(shí)視頻,第二行是視頻模型生成的內(nèi)容,顏色很好的保持了一致,但其形狀難以保持。

兩兩對(duì)比后,團(tuán)隊(duì)發(fā)現(xiàn)視頻生成模型更習(xí)慣于通過(guò)「顏色」尋找相似參考生成物體運(yùn)動(dòng)狀態(tài),其次是大小,再次是速度,最后才是形狀。顏色 / 大小 / 速度對(duì)形狀的影響情況如下圖:

- 復(fù)雜組合泛化情況
最后,對(duì)于復(fù)雜的組合泛化為何能夠發(fā)生,團(tuán)隊(duì)提出視頻模型具有三種基本的組合模式,分別為:屬性組合、空間組合(多個(gè)物體不同運(yùn)動(dòng)狀態(tài))、時(shí)間組合(不同的時(shí)間點(diǎn)多個(gè)物體的不同狀態(tài))。
實(shí)驗(yàn)結(jié)果發(fā)現(xiàn),對(duì)于速度與大小或顏色與大小等屬性對(duì),模型展現(xiàn)出一定程度的組合泛化能力。同時(shí),如下圖所示,模型能夠通過(guò)對(duì)訓(xùn)練數(shù)據(jù)的局部片段進(jìn)行時(shí)間 / 空間維度的再組合。
然而值得注意的是,并不是所有的情況下都能通過(guò)組合泛化生成遵循物理規(guī)律的視頻。模型對(duì)案例匹配的依賴限制了其效果。在不了解底層規(guī)則的情況下,模型檢索并組合片段,可能會(huì)生成不符合現(xiàn)實(shí)的結(jié)果。

- 視頻表征的局限性
最后,團(tuán)隊(duì)探索了在視頻表征空間進(jìn)行生成是否足以作為世界模型,結(jié)果發(fā)現(xiàn),視覺模糊性會(huì)導(dǎo)致在細(xì)粒度物理建模方面出現(xiàn)顯著的誤差。
例如下圖,當(dāng)物體尺寸差異僅在像素級(jí)別時(shí),單純通過(guò)視覺判斷一個(gè)球是否能通過(guò)間隙變得十分困難,這可能導(dǎo)致看似合理但實(shí)際上錯(cuò)誤的結(jié)果。
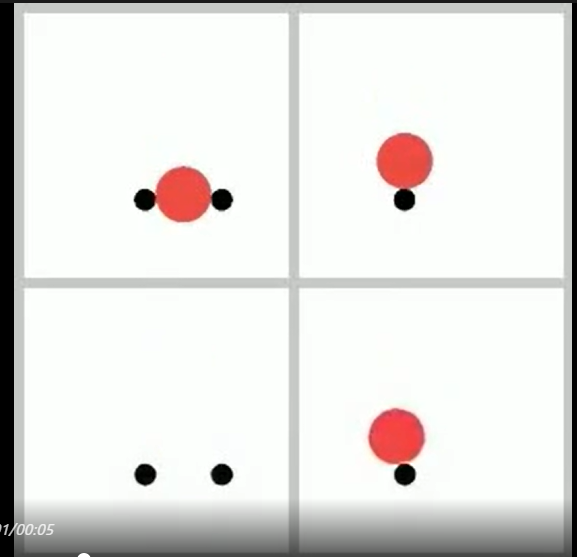
5圖注:第一行是真實(shí)視頻,第二行為模型生成的視頻。
這些發(fā)現(xiàn)表明,單純依賴視頻表示不足以進(jìn)行精確的物理建模。
團(tuán)隊(duì)介紹
該論文核心作者有兩位,其中之一為豆包大模型團(tuán)隊(duì) 95 后研究員 Bingyi Kang,此前他負(fù)責(zé)的研究項(xiàng)目 Depth Anything 同樣取得了業(yè)界的廣泛關(guān)注,并被收入蘋果 CoreML 庫(kù)中。
據(jù) Bingyi 分享,世界模型概念早已被提出,自 AlphaGo 誕生時(shí),「世界模型」 一詞已在業(yè)內(nèi)傳開,Sora 爆火后,他決定先從視頻生成模型能否真正理解物理規(guī)律入手,一步步揭開世界模型機(jī)理。
這當(dāng)中有三四周時(shí)間,項(xiàng)目毫無(wú)進(jìn)展,直到一次實(shí)驗(yàn),大家注意到一個(gè)很隱蔽的反常規(guī)現(xiàn)象,借此設(shè)計(jì)對(duì)比試驗(yàn)后,他們確認(rèn)了「模型其實(shí)不是在總結(jié)規(guī)律,而是在匹配跟他最接近的樣本」。
「做 research 往往不是說(shuō),你突然有個(gè)很好的 idea,然后你一試它就 work 了,很多時(shí)候你都是在排錯(cuò)。但經(jīng)過(guò)一段時(shí)間的試錯(cuò),你很可能突然發(fā)現(xiàn)某一個(gè)方向有解了。」Bingyi 表示。
盡管研究耗時(shí) 8 個(gè)月,每天對(duì)著視頻中的虛擬小球做定量實(shí)驗(yàn),但大家更多感受到的不是枯燥,而是「好玩」和「燒腦」,回憶這段,他感慨:「團(tuán)隊(duì)對(duì)基礎(chǔ)研究給了充分的探索空間。」
另一位 00 后同學(xué)也是核心參與者之一,據(jù)他分享,本次研究是他經(jīng)歷過(guò)的最具挑戰(zhàn)性、最耗時(shí)的項(xiàng)目,涉及對(duì)物理引擎、評(píng)測(cè)系統(tǒng)、實(shí)驗(yàn)方法的構(gòu)建,非常繁瑣,當(dāng)中還有好幾次項(xiàng)目「卡頓」住。不過(guò),團(tuán)隊(duì)負(fù)責(zé)人和 Mentor 都給予了耐心和鼓勵(lì),「沒(méi)人催趕緊把項(xiàng)目做完」。



























