中科大/華為諾亞出手!芯片性能≠布局評分,EDA物理設計框架全面開源
芯片物理布局,有了直指性能指標的新測評標準!
中科大MIRA Lab和華為諾亞方舟實驗室聯合發布了新的評估框架和數據集,而且完全開源。
有了這套標準,布局指標與最終的端到端性能不一致、得分高而PPA性能卻偏低的問題,就有望得到解決了。

在芯片設計當中,電子設計自動化(EDA)是至關重要的一環,在業界被稱為“芯片之母”,而芯片物理布局(Placement)又是其中的關鍵步驟。
芯片物理布局問題是一個NP-hard問題,人們嘗試著通過AI來進行這項工作,但缺乏一個有效的評測標準。
傳統的評估尺度——代理指標雖然易于計算,但常常與芯片最終的端到端性能存在顯著差異。
為了彌補這一鴻溝,中科大MIRA Lab和華為諾亞方舟實驗室聯合發布了這個名為ChiPBench的評估框架,以及相關數據集。
隨著ChiPBench的上線,作者也發現了當前芯片布局算法存在很多不足,提醒相關研究人員是時候研發新算法了。
芯片設計流程面臨挑戰
根據“摩爾定律”,集成電路(IC)的規模發生了指數級增長,對芯片設計帶來了前所未有的挑戰。
為了應對這種日益增長的復雜性,EDA工具應運而生,為硬件工程師提供了極大的幫助。
EDA工具能夠自動完成芯片設計工作流程中的各個步驟,包括高層次綜合、邏輯綜合、物理設計、測試和驗證等環節。

其中,芯片布局是一個重要環節,該階段又可以分為兩個子階段——宏布局和標準單元布局。
宏布局是超大規模集成(VLSI)物理設計中的一個關鍵問題,主要涉及較大元件(如SRAM和時鐘發生器,通常稱為宏)的排列。
這一階段對芯片的整體布局以及線長、功耗和面積等重要設計參數具有顯著影響。
之后的標準單元布局階段,需要處理的是數量更多、體積更小的標準單元的排列問題,這些單元是數字設計的基本組成部分。
通常,該階段利用組合優化求解等方法來實現布局擺放的優化,最大程度地減少單元間的距離,為后續的布線工作奠定良好的基礎,并在一定程度上優化互聯時序性能。
芯片布局傳統上由人類專業設計師手工完成,這不僅耗費大量人力,而且需要大量的專家先驗知識。
因此,許多設計自動化方法,尤其是基于人工智能的算法,被開發出來以實現這一過程的自動化。
然而,由于芯片設計的工作流程較長,對這些算法的評估通常集中在易于計算的中間代理指標上(例如半周長線長HPWL,布局單元密度等),但這些指標經常與端到端性能(即最終設計的 PPA)存在一定程度的偏差。
一方面,由于芯片設計工作流程的冗長,獲得給定芯片布局方案的端到端性能需要大量的工程設計工作,同時作者發現直接使用現有的開源EDA工具和數據集通常無法獲得端到端性能。
由于以上原因,現有的基于人工智能的芯片布局算法使用簡單易得的中間代理指標來訓練和評估學習到的模型。
另一方面,由于PPA指標反映了前幾個階段未充分考慮的許多方面,代理指標與最終的PPA目標之間存在嚴重差距。
因此,這種差距極大地限制了現有基于人工智能的布局算法在實際工業場景中的應用。
端到端預估芯片性能
作者認為,造成這種差距的原因是早期數據集的過度簡化。
例如,廣泛使用Bookshelf格式就是“過于簡化”的一個代表,這種格式下的布局結果不適用于后續設計階段,無法實現有效的最終設計。
一些后續的數據集雖然提供了運行后續階段所需的LEF/DEF文件和必要文件,但包含的電路數量仍然有限,且缺乏某些開源工具(如OpenROAD)所需的信息。
例如,庫文件中缺少時鐘樹綜合所需的緩沖元件定義,LEF文件中的層定義不完整,這阻礙了布線階段的工作。
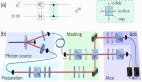
為了解決這些問題,作者構建了一個包含整個流程的全面物理實現信息的數據集。
該數據集涵蓋了一系列不同領域的設計,包括 CPU、GPU、網絡接口、圖像處理技術、物聯網設備、加密單元和微控制器等組件。
作者在這些設計上執行了六種最先進的基于人工智能的芯片物理布局算法,并將每種單點算法的結果通過標準輸入/輸出格式接入到物理實現工作流,以獲得最終的PPA結果。

初始數據集的生成以Verilog文件作為原始數據。OpenROAD執行邏輯綜合,將這些高級描述轉換為網表,詳細描述電路元件之間的電氣連接。
隨后,OpenROAD的集成平面規劃工具利用該網表在硅片上配置電路的物理布局。
OpenROAD將平面規劃階段產生的設計轉換為LEF/DEF文件,以便于后續布局算法的應用。
同時,作者通過OpenROAD完成整個EDA設計流程,在后續階段生成包括布局、時序樹綜合和布線在內的數據。
ChipBench數據集包含了物理設計流程各個階段所需的全部設計工具包。
在評估布局階段的算法時,前一階段的輸出文件將作為該評估算法的輸入。算法處理這些輸入文件,生成相應的輸出文件,然后將這些輸出文件集成到OpenROAD設計流程中。
最終,數據集將報告包括TNS、WNS、面積和功耗在內的性能指標,以提供全面的端到端性能評估。
這種方法提供了一套全面的評估指標,能夠衡量特定階段算法對最終芯片設計優化效果的影響,確保了評估指標的一致性,并避免了僅依賴于單一階段簡化指標的局限性。
這種評估方法有利于各種算法的優化和開發,確保了算法改進能夠轉化為芯片設計的實際性能提升。同時,通過一個強大的測試和改進框架,它促進了更高效、更有效的開源EDA工具的開發。

芯片布局需要開發新算法
利用上述工作流程,作者對多種基于人工智能的芯片布局算法進行了評估,包括SA、WireMask-EA、DREAMPlace、AutoDMP、MaskPlace、ChiPFormer以及OpenROAD中的默認算法。
作者對這些算法進行了端到端的評估,并報告了最終的性能指標。

另外,相關性分析結果表明,MacroHPWL與最終性能指標之間的相關性非常弱,這表明優化MacroHPWL對這些性能指標的影響非常有限。
Wirelength與WNS和TNS的相關性同樣較弱。這意味著,即便某些單點算法在優化Wirelength等中間指標上取得了成功,它們在最終的物理實現中可能只能提升PPA指標的某一方面,而無法全面優化。

因此,需要尋找更合適的中間指標,以便更好地與實際的PPA目標相關聯。
作者的評估結果揭示了目前主流布局算法所強調的中間指標與最終性能結果之間存在不一致性,這些發現凸顯了從新的角度開發布局算法的必要性。

△不同布局算法的最差時序圖
論文地址:https://arxiv.org/abs/2407.15026