訓(xùn)練45秒,渲染300+FPS!MVSGaussian:高效泛化的混合Gaussian
本文經(jīng)自動(dòng)駕駛之心公眾號(hào)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
寫在前面&筆者的個(gè)人理解
華科最新的MVSGaussian,一種從多視圖立體(MVS)中導(dǎo)出的新的廣義三維高斯表示方法,可以有效地重建看不見(jiàn)的場(chǎng)景。具體地說(shuō),1)我們利用MVS對(duì)幾何感知的高斯表示進(jìn)行編碼,并將其解碼為高斯參數(shù)。2) 為了進(jìn)一步提高性能,我們提出了一種混合高斯渲染,它集成了一種高效的體渲染設(shè)計(jì),用于新視角合成。3) 為了支持特定場(chǎng)景的快速微調(diào),我們引入了一種多視圖幾何一致聚合策略,以有效地聚合可推廣模型生成的點(diǎn)云,作為每個(gè)場(chǎng)景優(yōu)化的初始化。與以前基于NeRF的可推廣方法相比,MVSGaussian通常需要對(duì)每個(gè)圖像進(jìn)行幾分鐘的微調(diào)和幾秒鐘的渲染,它實(shí)現(xiàn)了實(shí)時(shí)渲染,每個(gè)場(chǎng)景的合成質(zhì)量更好。與普通的3D-GS相比,MVSGaussian以較少的訓(xùn)練計(jì)算成本實(shí)現(xiàn)了更好的視圖合成。在DTU、Real Forward Faceing、NeRF Synthetic以及Tanks and Temples數(shù)據(jù)集上進(jìn)行的大量實(shí)驗(yàn)驗(yàn)證了MVSGaussian以令人信服的可推廣性、實(shí)時(shí)渲染速度和快速的逐場(chǎng)景優(yōu)化攻擊了最先進(jìn)的性能。

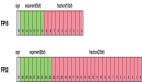
總之,我們提出了一種新的快速可推廣的高斯飛濺方法。我們?cè)趶V泛使用的DTU、Real Forward Faceing、NeRF Synthetic以及Tanks and Temples數(shù)據(jù)集上評(píng)估了我們的方法。大量實(shí)驗(yàn)表明,我們的可推廣方法優(yōu)于其他可推廣方法。經(jīng)過(guò)短時(shí)間的逐場(chǎng)景優(yōu)化,我們的方法獲得了與其他方法相當(dāng)甚至更好的性能,優(yōu)化時(shí)間更長(zhǎng),如圖1所示。在單個(gè)RTX 3090 GPU上,與普通的3D-GS相比,我們提出的方法實(shí)現(xiàn)了更好的新穎視圖合成,具有相似的渲染速度(300+FPS)和13.3倍的訓(xùn)練計(jì)算成本(45s)。我們的主要貢獻(xiàn)可概括如下:
- 我們提出了MVSGaussian,這是一種從多視圖立體和像素對(duì)齊的高斯表示導(dǎo)出的廣義高斯散點(diǎn)方法。
- 我們進(jìn)一步提出了一種有效的混合高斯渲染方法來(lái)促進(jìn)泛化學(xué)習(xí)。
- 我們引入了一致的聚合策略,為快速的每場(chǎng)景優(yōu)化提供高質(zhì)量的初始化。
項(xiàng)目主頁(yè):https://mvsgaussian.github.io/
相關(guān)工作回顧
多視圖立體(MVS)旨在從多個(gè)視圖重建密集的3D表示。傳統(tǒng)的MVS方法依賴于手工制作的功能和相似性度量,這限制了它們的性能。隨著深度學(xué)習(xí)在3D感知中的發(fā)展,MVSNet首先提出了一種端到端的流水線,其關(guān)鍵思想是構(gòu)建一個(gè)成本體積,將2D信息聚合到3D幾何感知表示中。后續(xù)工作遵循這種基于成本-體積的流水線,并從各個(gè)方面進(jìn)行改進(jìn),例如,通過(guò)重復(fù)的平面掃描或粗略到精細(xì)的架構(gòu)來(lái)減少內(nèi)存消耗,優(yōu)化成本聚合,增強(qiáng)特征表示,以及改進(jìn)解碼策略。由于代價(jià)體積對(duì)多視圖特征的一致性進(jìn)行編碼,并自然地執(zhí)行對(duì)應(yīng)匹配,因此在本文中,我們開(kāi)發(fā)了一種新的基于MVS的可推廣高斯空間表示。
可推廣的NeRF。通過(guò)使用MLP將場(chǎng)景隱式地表示為連續(xù)的顏色和密度場(chǎng),神經(jīng)輻射場(chǎng)(NeRF)通過(guò)體積渲染技術(shù)實(shí)現(xiàn)了令人印象深刻的渲染結(jié)果。后續(xù)工作將其擴(kuò)展到各種任務(wù),并取得了可喜的成果。然而,它們都需要耗時(shí)的逐場(chǎng)景優(yōu)化。為了解決這個(gè)問(wèn)題,已經(jīng)提出了一些通用的NeRF方法。一般的范例包括對(duì)每個(gè)3D點(diǎn)的特征進(jìn)行編碼,然后對(duì)這些特征進(jìn)行解碼以獲得體積密度和輻射度。根據(jù)編碼特征,可推廣的NeRF可分為外觀特征、聚合多視圖特征、基于成本量的特征和對(duì)應(yīng)匹配特征。盡管取得了顯著的效果,但性能仍然有限,優(yōu)化和渲染速度較慢。
三維高斯散射(3D-GS)使用各向異性高斯來(lái)顯式地表示場(chǎng)景,并通過(guò)差分光柵化實(shí)現(xiàn)實(shí)時(shí)渲染。受此啟發(fā),一些研究將其應(yīng)用于各種任務(wù),例如編輯、動(dòng)態(tài)場(chǎng)景等。然而,高斯飛濺的本質(zhì)仍然在于對(duì)場(chǎng)景的過(guò)度擬合。為了彌補(bǔ)這一點(diǎn),一些作品首次嘗試將高斯飛濺推廣到看不見(jiàn)的場(chǎng)景。廣義高斯散射的目標(biāo)是以前饋方式預(yù)測(cè)高斯參數(shù),而不是按場(chǎng)景優(yōu)化。PixelSplat通過(guò)利用核極變換器對(duì)特征進(jìn)行編碼并隨后將其解碼為高斯參數(shù)來(lái)解決尺度模糊問(wèn)題。然而,它將重點(diǎn)放在圖像對(duì)作為輸入,并且Transformer會(huì)產(chǎn)生顯著的計(jì)算成本。GPS Gaussian從立體匹配中獲得靈感,并對(duì)輸入圖像對(duì)進(jìn)行核極校正和視差估計(jì)。然而,它專注于人類小說(shuō)視角的合成,并需要地面實(shí)況深度圖。Spatter Image介紹了一種單視圖三維重建方法。然而,它側(cè)重于以對(duì)象為中心的重建,而不是推廣到看不見(jiàn)的場(chǎng)景。總體而言,這些方法受到低效率的限制,僅限于對(duì)象重建,并且僅限于圖像對(duì)或單個(gè)視圖。為此,在本文中,我們旨在研究一種有效的可推廣高斯散射,用于我們的一般場(chǎng)景中的新視圖合成。
MVSGaussian
概覽
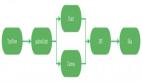
給定一組源視圖,NVS旨在從一個(gè)新穎的相機(jī)姿勢(shì)合成目標(biāo)視圖。我們提出的可推廣高斯飛濺框架的概述如圖2所示。我們首先利用特征金字塔網(wǎng)絡(luò)(FPN)從源視圖中提取多尺度特征。然后,這些特征被扭曲到目標(biāo)相機(jī)上,通過(guò)差分單應(yīng)性來(lái)構(gòu)建成本體積,然后通過(guò)3D細(xì)胞神經(jīng)網(wǎng)絡(luò)進(jìn)行正則化以生成深度圖。基于獲得的深度圖,我們通過(guò)聚合多視圖和空間信息來(lái)對(duì)每個(gè)像素對(duì)齊的3D點(diǎn)的特征進(jìn)行編碼。然而,高斯飛濺是一種基于區(qū)域的顯式表示,專為基于tile的渲染而設(shè)計(jì),涉及高斯和像素之間的復(fù)雜多對(duì)多映射,這對(duì)可推廣學(xué)習(xí)提出了挑戰(zhàn)。為了解決這一問(wèn)題,我們提出了一種高效的混合渲染,通過(guò)集成一個(gè)簡(jiǎn)單的深度感知體積渲染模塊,其中每條光線只采樣一個(gè)點(diǎn)。我們使用高斯飛濺和體積渲染來(lái)渲染兩個(gè)視圖,然后將這兩個(gè)渲染視圖平均化為最終視圖。該管道進(jìn)一步以級(jí)聯(lián)結(jié)構(gòu)構(gòu)建,以從粗到細(xì)的方式傳播深度圖和渲染視圖。

MVS-based Gaussian Splatting Representation
MVS的深度估計(jì)。深度圖是我們管道的關(guān)鍵組成部分,因?yàn)樗B接了2D圖像和3D場(chǎng)景表示。遵循基于學(xué)習(xí)的MVS方法,我們首先在目標(biāo)視圖處建立多個(gè)前向平行平面。然后,我們使用差分單應(yīng)性將源視圖的特征扭曲到這些掃描平面上,如下所示:

利用源視圖中扭曲的特征,通過(guò)計(jì)算它們的方差來(lái)構(gòu)建成本量,該方差對(duì)多視圖特征的一致性進(jìn)行編碼。然后,將成本體積饋送到3D CNN中進(jìn)行正則化,以獲得概率體積。利用這個(gè)深度概率分布,我們對(duì)每個(gè)深度假設(shè)進(jìn)行加權(quán),以獲得最終的深度。
像素對(duì)齊的高斯表示。利用估計(jì)的深度,每個(gè)像素可以不投影到3D點(diǎn),該3D點(diǎn)是3D高斯的位置。下一步是對(duì)這些3D點(diǎn)的特征進(jìn)行編碼,以建立像素對(duì)齊的高斯表示。具體來(lái)說(shuō),我們首先使用等式(3)將特征從源視圖扭曲到目標(biāo)相機(jī)。然后利用池化網(wǎng)絡(luò)將這些多視圖特征聚合為特征。考慮到splatting的特性,每個(gè)高斯值都有助于圖像特定區(qū)域中像素的顏色值。然而,聚合特征fv僅對(duì)單個(gè)像素的多視圖信息進(jìn)行編碼,缺乏空間感知。因此,我們使用2D UNet進(jìn)行空間增強(qiáng),產(chǎn)生fg。利用編碼的特征,我們可以對(duì)它們進(jìn)行解碼,以獲得用于渲染的高斯參數(shù)。具體而言,每個(gè)高斯都由屬性{m,s,r,α,c}表征。對(duì)于位置m,可以根據(jù)估計(jì)的深度對(duì)像素進(jìn)行不投影來(lái)獲得:

對(duì)于縮放s、旋轉(zhuǎn)r和不透明度a,它們可以從編碼特征中解碼,如下所示:

對(duì)于最后一個(gè)屬性,顏色c,3D高斯Splatting使用球面諧波(SH)系數(shù)來(lái)定義它。然而,從特征學(xué)習(xí)SH系數(shù)的泛化是不魯棒的。相反,我們直接將特征中的顏色回歸為:

高效的混合高斯渲染。利用上述高斯參數(shù),可以使用splatting技術(shù)渲染新的視圖。然而,所獲得的視圖缺乏精細(xì)的細(xì)節(jié),并且這種方法表現(xiàn)出有限的泛化性能。我們的見(jiàn)解是,splatting方法在顏色貢獻(xiàn)方面引入了3D高斯和像素之間復(fù)雜的多對(duì)多關(guān)系,這對(duì)泛化提出了挑戰(zhàn)。因此,我們建議使用3D高斯和像素之間的簡(jiǎn)單一一對(duì)應(yīng)來(lái)預(yù)測(cè)顏色以進(jìn)行細(xì)化。在這種情況下,鍍層退化為具有單個(gè)深度感知采樣點(diǎn)的體積渲染。具體來(lái)說(shuō),我們通過(guò)解碼fv來(lái)獲得輻射度和體積密度,然后進(jìn)行體積渲染以獲得渲染視圖。通過(guò)對(duì)通過(guò)splatting和體積渲染渲染的視圖進(jìn)行平均,形成最終渲染視圖。
Consistent Aggregation for Per-Scene Optimization
廣義模型可以為看不見(jiàn)的場(chǎng)景重建合理的3D高斯表示。我們可以使用所描述的優(yōu)化策略,針對(duì)特定場(chǎng)景進(jìn)一步優(yōu)化這種高斯表示。由于上述可推廣模型在幾個(gè)給定的新穎視點(diǎn)重建高斯表示,因此主要的挑戰(zhàn)是如何有效地將這些高斯表示聚合為單個(gè)高斯表示以進(jìn)行有效渲染。由于MVS方法的固有局限性,可推廣模型預(yù)測(cè)的深度可能不完全準(zhǔn)確,導(dǎo)致在生成的高斯點(diǎn)云中存在噪聲。直接連接這些高斯點(diǎn)云會(huì)導(dǎo)致大量的噪聲。此外,大量的點(diǎn)會(huì)降低后續(xù)的優(yōu)化和渲染速度。一個(gè)直觀的解決方案是對(duì)連接的點(diǎn)云進(jìn)行下采樣。然而,在減少噪聲的同時(shí),它也會(huì)減少有效點(diǎn)的數(shù)量。我們的見(jiàn)解是,一個(gè)好的聚合策略應(yīng)該最大限度地減少噪聲點(diǎn),并盡可能地保留有效點(diǎn),同時(shí)確保點(diǎn)的總數(shù)不會(huì)過(guò)大。為此,我們引入了一種基于多視圖幾何一致性的聚合策略。跨不同視點(diǎn)的同一3D點(diǎn)的預(yù)測(cè)深度應(yīng)顯示出一致性。否則,預(yù)測(cè)的深度被認(rèn)為是不可靠的。這種幾何一致性可以通過(guò)計(jì)算不同視圖之間的投影誤差來(lái)測(cè)量。具體而言,如圖3所示,給定要檢查的參考深度圖D0和來(lái)自附近視點(diǎn)的深度圖D1,我們首先將D0中的像素p投影到附近視圖,以獲得投影點(diǎn)q,如下所示:

反過(guò)來(lái),我們將獲得的具有估計(jì)深度D1(q)的像素q反向投影到參考視圖上,以獲得投影點(diǎn)p',如下所示:

然后,通過(guò)以下公式計(jì)算重投影誤差:

參考圖像將與剩余圖像中的每一個(gè)成對(duì)地進(jìn)行比較,以計(jì)算投影誤差。我們采用動(dòng)態(tài)一致性檢查算法來(lái)選擇有效的深度值。主要思想是,當(dāng)估計(jì)的深度在少數(shù)視圖中具有非常低的投影誤差或在大多數(shù)視圖中具有相對(duì)低的誤差時(shí),估計(jì)的深度是可靠的。其公式如下:

實(shí)驗(yàn)
我們?cè)贒TU訓(xùn)練集上訓(xùn)練可推廣模型,并在表1中報(bào)告DTU測(cè)試集上的定量結(jié)果,在表2中報(bào)告另外三個(gè)數(shù)據(jù)集上的量化結(jié)果。由于基于MVS的像素對(duì)齊高斯表示和高效的混合高斯渲染,我們的方法以快速的推理速度實(shí)現(xiàn)了最佳性能。由于引入了epipolar Transformer,PixelSplat的速度較慢,內(nèi)存消耗較大。此外,它專注于以圖像對(duì)為輸入的自然場(chǎng)景,當(dāng)應(yīng)用于以對(duì)象為中心的數(shù)據(jù)集時(shí),其性能顯著降低。對(duì)于基于NeRF的方法,ENeRF通過(guò)每條射線僅采樣2個(gè)點(diǎn)而享有良好的速度,然而,其性能有限,并且消耗更高的內(nèi)存開(kāi)銷。其余的方法通過(guò)采樣光線來(lái)渲染圖像,因?yàn)樗鼈兊膬?nèi)存消耗很高,因?yàn)樗鼈儫o(wú)法同時(shí)處理整個(gè)圖像。定性結(jié)果如圖4所示。我們的方法可以生成具有更多場(chǎng)景細(xì)節(jié)和較少瑕疵的高質(zhì)量視圖。



每個(gè)場(chǎng)景優(yōu)化后的定量結(jié)果報(bào)告在表3中。對(duì)于每場(chǎng)景優(yōu)化,一種策略是優(yōu)化整個(gè)管道,類似于基于NeRF的方法。另一種方法是僅優(yōu)化由可推廣模型提供的初始高斯點(diǎn)云。在優(yōu)化整個(gè)管道時(shí),與以前的可推廣NeRF方法相比,我們的方法可以獲得更好的性能和更快的推理速度,結(jié)果與NeRF相當(dāng),證明了我們方法的魯棒表示能力。相比之下,僅優(yōu)化高斯可以顯著提高優(yōu)化和渲染速度,因?yàn)樗撕臅r(shí)的前饋神經(jīng)網(wǎng)絡(luò)。此外,所述的自適應(yīng)密度控制模塊還可以提高性能。由于可推廣模型提供了出色的初始化和有效的聚合策略,我們?cè)诙痰膬?yōu)化期內(nèi)實(shí)現(xiàn)了最佳性能,約為3D-GS的十分之一。特別是在真實(shí)面向前的數(shù)據(jù)集上,我們的方法僅需45秒的優(yōu)化就實(shí)現(xiàn)了卓越的性能,而3D-GS和NeRF分別為10分鐘和10小時(shí)。此外,我們的方法的推理速度與3D-GS的推理速度相當(dāng),顯著優(yōu)于基于NeRF的方法。如圖5所示,我們的方法能夠生成具有更精細(xì)細(xì)節(jié)的高保真度視圖。





結(jié)論
我們提出了MVSGaussian,一種有效的廣義高斯Splatting方法。具體來(lái)說(shuō),我們利用MVS來(lái)估計(jì)深度,建立像素對(duì)齊的高斯表示。為了增強(qiáng)泛化能力,我們提出了一種混合渲染方法,該方法集成了深度感知體積渲染。此外,由于高質(zhì)量的初始化,我們的模型可以針對(duì)特定場(chǎng)景快速微調(diào)。與每個(gè)圖像通常需要幾分鐘的微調(diào)和幾秒鐘的渲染的可推廣NeRF相比,MVSGaussian實(shí)現(xiàn)了具有卓越合成質(zhì)量的實(shí)時(shí)渲染。此外,與3D-GS相比,MVSGaussian在減少訓(xùn)練時(shí)間的情況下實(shí)現(xiàn)了更好的視圖合成。局限性由于我們的方法依賴于MVS進(jìn)行深度估計(jì),因此它繼承了MVS的局限性,例如紋理較弱或鏡面反射區(qū)域的深度精度降低,導(dǎo)致視圖質(zhì)量下降。