













開源模型進展盤點:最新Mixtral、Llama 3、Phi-3、OpenELM到底有多好?
深度學習領域知名研究者、Lightning AI 的首席人工智能教育者 Sebastian Raschka 對 AI 大模型有著深刻的洞察,也會經常把一些觀察的結果寫成博客。在一篇 5 月中發布的博客中,他盤點分析了 4 月份發布的四個主要新模型:Mixtral、Meta AI 的 Llama 3、微軟的 Phi-3 和蘋果的 OpenELM。他還通過一篇論文探討了 DPO 和 PPO 的優劣之處。之后,他分享了 4 月份值得關注的一些研究成果。

Mixtral、Llama 3 和 Phi-3:有什么新東西?
首先,從最重要的話題開始:4 月發布的主要新模型。這一節將簡要介紹 Mixtral、Llama 3 和 Phi-3。下一節將會更詳細地介紹蘋果的 OpenELM。
Mixtral 8x22B:模型越大越好!
Mixtral 8x22B 是 Mistral AI 推出的最新款混合專家(MoE)模型,其發布時采用了寬松的 Apache 2.0 開源許可證。
這個模型類似于 2024 年發布的 Mixtral 8x7B,其背后的關鍵思路是將 Transformer 架構中的每個前饋模塊替換成 8 個專家層。對于 MoE,這里就不多用篇幅解釋了,不過作者在今年的一月研究盤點中介紹 Mixtral 8x7B 時詳細介紹過 MoE。
Mixtral 一篇博客文章給出了一張很有趣的圖,其中在兩個軸上比較了 Mixtral 8x22B 與其它幾個 LLM:在常用的 MMLU 基準上的建模性能以及活躍參數量(與計算資源需求有關)。

Mixtral 8x22B 與其它一些 LLM 的對比(基于博客 https://mistral.ai/news/mixtral-8x22b )
Llama 3:數據越多越好!
Meta AI 在 2023 年 2 月發布的首個 Llama 模型是開放式 LLM 的一步重大突破,也是開源 LLM 發展歷程的重要節點。因此很自然地,去年發布的 Llama 2 也振奮了每個人的心。現在 Meta AI 已經開始發布的 Llama 3 模型也同樣振奮人心。
雖然最大的模型(400B 版本)依然還在訓練之中,但他們已經發布了大家熟悉的 8B 和 70B 版本。而且他們的表現很好!下面我們把 Llama 3 加入到上圖中。

Llama 3、Mixtral 和其它 LLM 的對比
整體上看,Llama 3 架構幾乎與 Llama 2 完全一樣。它們之間的主要區別是 Llama 3 的詞匯庫更大以及 Llama 3 的更小型模型使用了分組查詢注意力(grouped-query attention)。至于什么是分組查詢注意力,可參閱本文作者寫的另一篇文章:https://magazine.sebastianraschka.com/p/ahead-of-ai-11-new-foundation-models
下面是用 LitGPT 實現 Llama 2 和 Llama 3 的配置文件,這能清楚方便地展示它們的主要差異。

通過 LitGPT 比較 Llama 2 和 Llama 3 的配置,https://github.com/Lightning-AI/litgpt
訓練數據的規模
Llama 3 的性能之所以比 Llama 2 好很多,一大主要因素是其數據集大得多。Llama 3 的訓練使用了 15 萬億 token,而 Llama 2 只有 2 萬億。
這個發現很有趣,因為根據 Llama 3 博客所言:依照 Chinchilla 擴展律,對于 8B 參數的模型,訓練數據的最優數量要少得多,大約為 2000 億 token。此外,Llama 3 的作者觀察到,8B 和 70B 參數的模型在 15 萬億 token 規模上也展現出了對數線性級的提升。這說明,即使訓練 token 數量超過 15 萬億,模型也能獲得進一步提升。
指令微調和對齊
對于指令微調和對齊,研究者的選擇通常有兩個:通過近端策略優化(PPO)或無獎勵模型的直接偏好優化(DPO)實現使用人類反饋的強化學習(RLHF)。有趣的是,Llama 3 的開發者對這兩者并無偏好,他們兩個一起用了!(后面一節會更詳細地介紹 PPO 和 DPO)。
Llama 3 博客表示 Llama 3 的研究論文會在下一個月發布,到時我們還能看到更多細節。
Phi-3:數據質量越高越好!
就在 Llama 3 盛大發布一周之后,微軟發布了其新的 Phi-3 LLM。根據其技術報告中的基準測試結果,最小的 Phi-3 模型也比 Llama 3 8B 模型更強,即便其大小要小一半。

Phi-3、Llama 3、Mixtral 與其它 LLM 的比較
值得注意的是,Phi-3(基于 Llama 架構)訓練使用的 token 數量比 Llama 3 少 5 倍,僅有 3.3 萬億,而 Llama 3 則是 15 萬億。Phi-3 甚至使用了和 Llama 2 一樣的 token 化器,詞匯庫大小為 32,064,這比 Llama 3 的詞匯庫小得多。
另外,Phi-3-mini 的參數量僅有 3.8B,不到 Llama 3 8B 參數量的一半。
那么,Phi-3 有何秘訣?根據其技術報告,其更重視數據質量,而不是數量:「經過嚴格過濾的網絡數據和合成數據」。
其論文并未給出太多數據整編方面的細節,但其很大程度上承襲了之前的 Phi 模型的做法。本文作者之前寫過一篇介紹 Phi 模型的文章,參閱:https://magazine.sebastianraschka.com/p/ahead-of-ai-12-llm-businesses
在本文寫作時,人們依然不能肯定 Phi-3 是否正如其開發者許諾的那樣好。舉個例子,很多人都表示,在非基準測試的任務上,Phi-3 的表現比 Llama 3 差得多。
結論
上面三個公開發布的 LLM 讓過去的 4 月成為了一個非常特殊的月份。而作者最喜歡的模型還是尚未談到的 OpenELM,這是下一節的內容。
在實踐中,我們應該如何選用這些模型呢?作者認為這三種模型都有各自的吸引點。Mixtral 的活躍參數量低于 Llama 3 70B,但依然能維持相當好的性能水平。Phi-3 3.8B 可能比較適合用于移動設備;其作者表示,Phi-3 3.8B 的一個量化版本可以運行在 iPhone 14 上。而 Llama 3 8B 可能最能吸引各種微調用戶,因為使用 LoRA 在單臺 GPU 上就能輕松對其進行微調。
OpenELM:一個使用開源訓練和推理框架的高效語言模型系列
OpenELM 是蘋果公司發布的最新 LLM 模型套件和論文,其目標是提供可在移動設備上部署的小型 LLM。
類似于 OLMo,這篇 LLM 論文的亮眼之處是其詳細分享了架構、訓練方法和訓練數據。

OpenELM 與其它使用同樣的數據集、代碼和權重的開源 LLM 的比較(這樣的模型不多,但都是開放的)。圖表來自 OpenELM 論文:https://arxiv.org/abs/2404.14619
先看一些最相關的信息:
- OpenELM 有 4 種相對較小且方便使用的大小:270M、450M、1.1B 和 3B。
- 每種大小都有一個指令版本可用,其使用了拒絕采樣和直接偏好優化進行訓練。
- OpenELM 的表現稍優于 OLMo,即便其訓練使用的 token 數量少 2 倍。
- 其主要的架構調整是逐層擴展策略。
架構細節
除了逐層擴展策略(細節后面談),OpenELM 的整體架構設置和超參數配置與 OLMo 和 Llama 等其它 LLM 較為相似,見下圖。

OpenELM、最小的 OLMo 模型和最小的 Llama 2 模型的架構和超參數比較。
訓練數據集
他們從多個公共數據集(RefinedWeb、RedPajama、The PILE、Dolma)采樣了一個相對較小的子集,其中包含 1.8T token。這個子集比 OLMo 訓練使用的數據集 Dolma 小 2 倍。但他們是依據什么標準執行這個采樣的呢?
其中一位作者表示:「至于數據集,我們在數據集采樣方面沒有考慮任何理由,就是希望使用 2T token 規模的公共數據集(遵循 LLama 2 的做法)。」

訓練 OpenELM 使用的 token 數量與數據集中的 token 原數量(請注意 token 的確切數量取決于所用的 token 化器)。圖表來自 OpenELM 論文。
逐層擴展
其使用的逐層擴展策略(基于論文《DeLighT: Deep and Light-weight Transformer》)非常有趣。從本質上講,這個策略就是從早期到后期的 transformer 模塊逐漸對層進行擴寬。特別需要說明,這個過程會保持頭的大小恒定,逐漸增加注意力模塊中頭的數量。前饋模塊的維度也會擴展,如下圖所示。
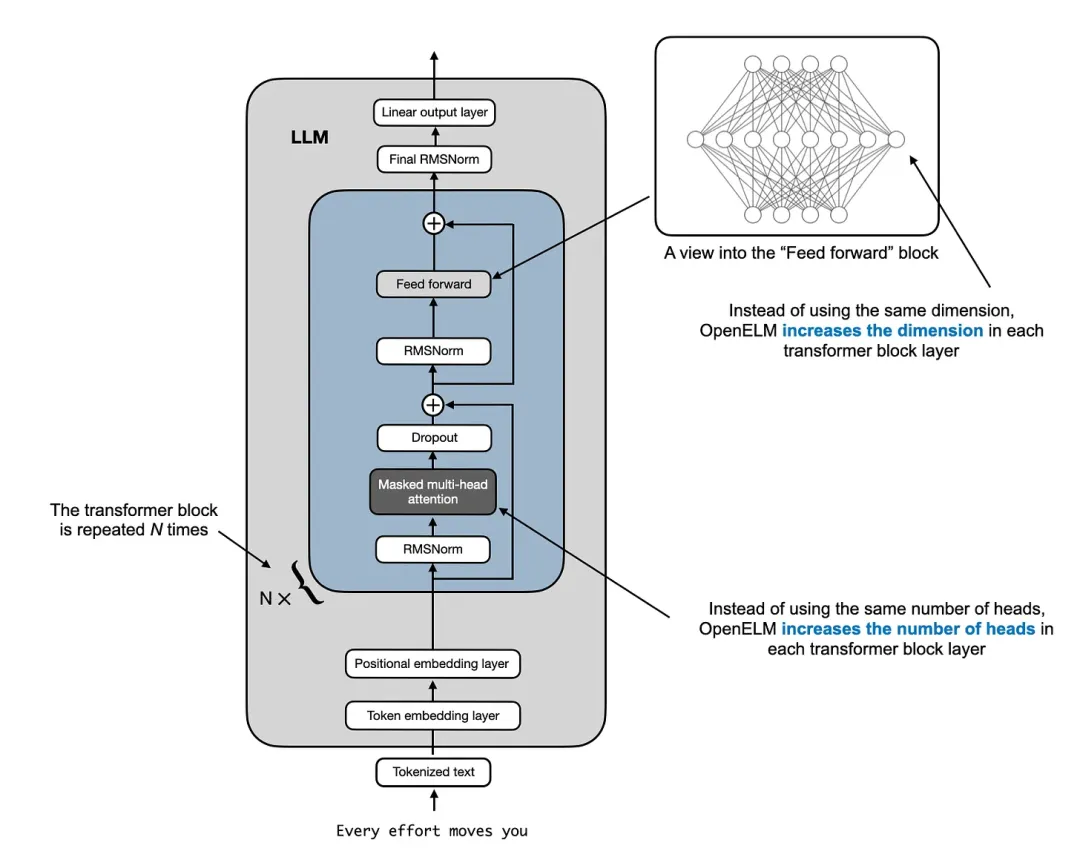
LLM 架構,來自作者的著作《Build a Large Language Model from Scratch》
作者表示:「我希望有一個在同樣的數據集上使用和不用逐層擴展策略訓練 LLM 的消融研究。」但這類實驗的成本很高,沒人做也就可以理解了。
但是,最早提出逐層擴展策略的論文《DeLighT: Deep and Light-weight Transformer》中有消融研究,這是基于原始的編碼器 - 解碼器架構在更小的數據集上完成的,如下所示。
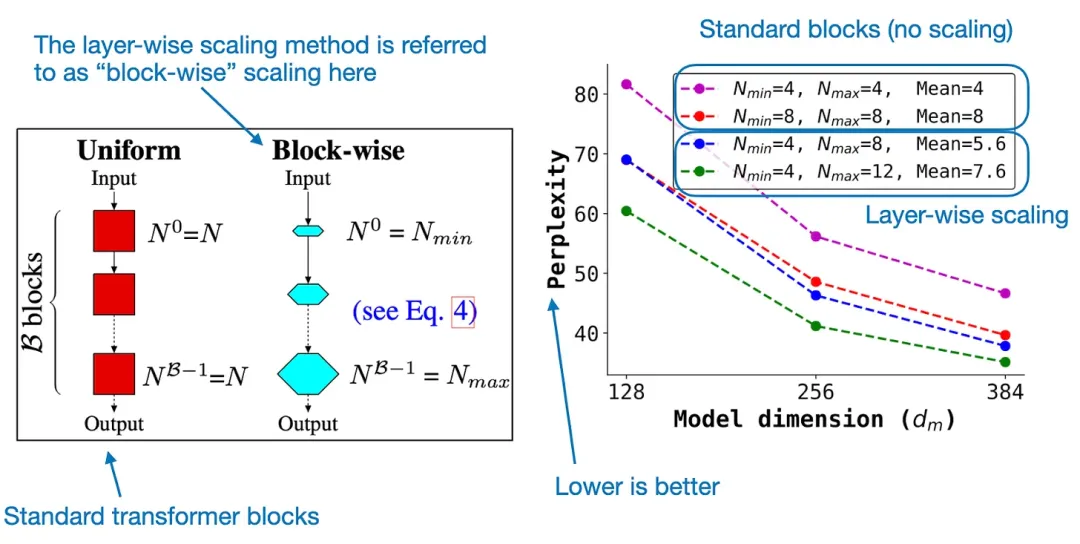
標準 transformer 模塊和采用了逐層(逐模塊)擴展策略的 transformer 模塊的比較,來自 DeLighT 論文:https://arxiv.org/abs/2008.00623
LoRA 與 DoRA
OpenELM 團隊還給出了一個意外之喜:比較了 LoRA 與 DoRA 在參數高效型微調方面的表現!結果表明,這兩種方法之間并不存在明顯的差異。
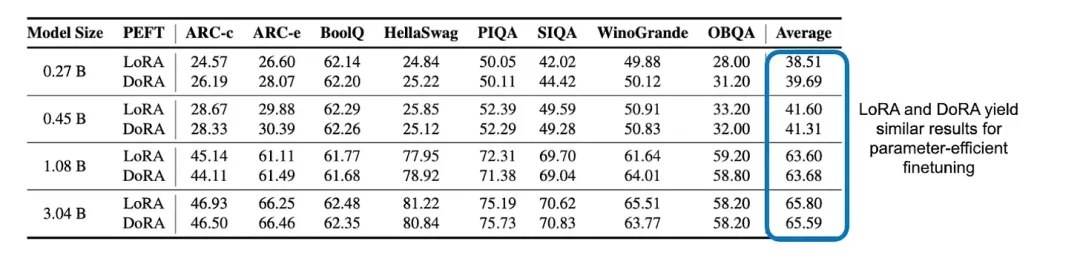
LoRA 和 DoRA 這兩種參數高效型微調方法之間的建模性能比較
結論
盡管 OpenELM 論文并未解答任何研究問題,但它寫得很棒,詳細透明地給出了 OpenELM 的實現細節。后面我們可能會看到更多 LLM 使用逐層擴展策略。另外,蘋果不止發布了這一篇論文,也在 GitHub 上公布了 OpenELM 代碼:https://github.com/apple/corenet/tree/main/mlx_examples/open_elm
總之,這是很棒的成果,非常感謝其研究團隊(以及蘋果)與我們分享!
在 LLM 對齊方面,DPO 是否優于 PPO?
論文《Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study》解答了一個非常關鍵的問題。(https://arxiv.org/abs/2404.10719 )
在介紹結果之前,我們先概述一下這篇論文的內容:PPO(近端策略優化)和 DPO(直接偏好優化)都是通過 RLHF(使用人類反饋的強化學習)實現的用于對齊 LLM 的常用方法。
RLHF 是 LLM 開發過程的一大關鍵組件,其作用是將 LLM 與人類偏好對齊,這可提升 LLM 所生成響應的安全性和實用性等。

典型的 LLM 訓練周期
更詳細的解釋可參看作者上個月發布的文章:https://magazine.sebastianraschka.com/p/tips-for-llm-pretraining-and-evaluating-rms
RLHF-PPO 和 DPO 是什么?
最初的 LLM 對齊方法 RLHF-PPO 一直都是 OpenAI 的 InstructGPT 和 ChatGPT 中部署的 LLM 的主干技術。但是,最近幾個月,隨著 DPO 微調型 LLM 的涌現,情況發生了變化 —— 其對公共排行榜產生了重大影響。DPO 廣受歡迎的原因也許是其無獎勵的特性,這使得其更易使用:不同于 PPO,DPO 并不需要訓練一個單獨的獎勵模型,而是使用一個類似分類的目標來直接更新 LLM。

獎勵模型與 DPO 對比
現如今,公共排行榜上大多數 LLM 都是使用 DPO 訓練的,而不是 PPO。但不幸的是,在這里介紹的這篇論文之前,還沒人在同樣的數據集上使用同樣的模型比較 PPO 和 DPO 的優劣。
PPO 通常優于 DPO
論文《Is DPO Superior to PPO for LLM Alignment? A Comprehensive Study》中給出了大量實驗的結果,但其中的主要結論是:PPO 通常優于 DPO,且 DPO 更容易受到分布外數據的影響。
這里,分布外數據的意思是 LLM 之前訓練所用的指令數據(使用監督式微調)不同于 DPO 所用的偏好數據。舉個例子,一個 LLM 首先在常用的 Alpaca 數據集上訓練完成,之后再在另一個帶有偏好標簽的數據集上通過 DPO 進行微調。(為了提升在分布外數據上的 DPO 表現,一種方法是在 DPO 微調之前,添加一輪在偏好數據集上的監督式指令微調。)
下圖總結了主要發現。
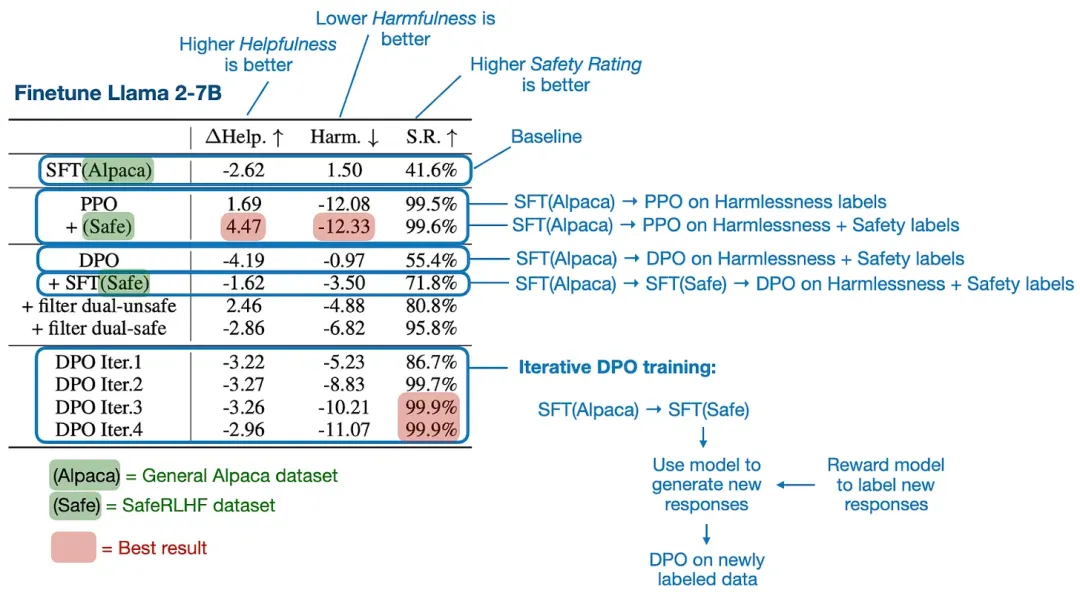
論文的主要發現
除了上面給出的主要結果,該論文還包含一些額外的實驗和消融研究,感興趣的讀者可參看原論文。
最佳實踐
此外,這篇論文還包含了一些使用 DPO 和 PPO 時的最佳實踐推薦。
舉個例子,如果你使用 DPO,一定要確保首先在偏好數據上執行監督式微調。而在現有偏好數據上,迭代式 DPO 更優于 DPO,這需要使用一個已有的獎勵模型來標注額外的數據。
如果你使用 PPO,則成功的關鍵因素包括較大的批量大小、advantage normalization 以及通過指數移動平均進行參數更新。

偏好數據示例,來自 Orca 數據集,https://huggingface.co/datasets/Intel/orca_dpo_pairs
總結
基于這篇論文的結果可知,如果使用得當,那么 PPO 似乎優于 DPO。但是,考慮到 DPO 的使用和實現都更簡單,DPO 可能仍將是大家的首選方法。
作者推薦了一種實踐做法:如果你有基本真值獎勵標簽(這樣就不必預訓練自己的獎勵模型)或可以下載到領域內獎勵模型,就使用 PPO。其它情況就使用 DPO,因為它更簡單。
另外,根據 LLama 3 博客文章,我們也可以不糾結選哪一個:我們可以兩個一起用!舉個例子,Llama 3 就遵循以下流程:預訓練→監督式微調→拒絕采樣→PPO→DPO
四月發布的其它有趣論文
最后,作者 Sebastian Raschka 分享了自己在四月份看到的有趣論文。他表示即使與 LLM 成果大量涌現的前幾個月相比,四月份的看點依然很多。
- 論文:KAN: Kolmogorov–Arnold Networks
- 鏈接:https://arxiv.org/abs/2404.19756
Kolmogorov-Arnold Networks(KAN)是使用在邊上的可學習的基于 spline 的函數替換了線性權重參數,并且缺乏固定的激活參數。KAN 似乎是多層感知器(MLP)的一種頗具吸引力的新替代品,其在準確度、神經擴展性能和可解釋性方面都有優勢。
- 論文:When to Retrieve:Teaching LLMs to Utilize Information Retrieval Effectively
- 鏈接:https://arxiv.org/abs/2404.19705
這篇論文為 LLM 提出了一種定制版的訓練方法,可教會它們在不知道答案時通過一個特殊 token <RET> 使用自己的參數記憶或外部信息檢索系統。
- 論文:A Primer on the Inner Workings of Transformer-based Language Models
- 鏈接:https://arxiv.org/abs/2405.00208
這篇入門解讀論文簡要概述了用于解釋基于 Transformer 的僅解碼器語言模型所使用的技術。
- 論文:RAG and RAU:A Survey on Retrieval-Augmented Language Model in Natural Language Processing
- 鏈接:https://arxiv.org/abs/2404.19543
這篇綜述全面總結了檢索增強型 LLM—— 詳細給出了它們的組件、結構、應用和評估方法。
- 論文:Better & Faster Large Language Models via Multi-token Prediction
- 鏈接:https://arxiv.org/abs/2404.19737
這篇論文認為,訓練 LLM 同時預測多個未來 token 而不只是接下來一個 token 可以提升采樣效率,同時還能提升 LLM 在生成任務上的性能表現。
- 論文:LoRA Land:310 Fine-tuned LLMs that Rival GPT-4, A Technical Report
- 鏈接:https://arxiv.org/abs/2405.00732
LoRA 是使用最為廣泛的參數高效型微調技術,而這項研究發現 4 bit LoRA 微調的模型既顯著優于其基礎模型,也優于 GPT-4。
- 論文:Make Your LLM Fully Utilize the Context, An, Ma, Lin et al.(25 Apr),
- 鏈接:https://arxiv.org/abs/2404.16811
這項研究提出了 FILM-7B。這個模型使用了一種信息密集型方法訓練得到,可以解決「中間丟失(lost-in-the-middle)」難題,即 LLM 無法檢索上下文窗口中間位置的信息的問題。
- 論文:Layer Skip:Enabling Early Exit Inference and Self-Speculative Decoding
- 鏈接:https://arxiv.org/abs/2404.16710
LayerSkip 可以加快 LLM 的推理速度,為此其在訓練階段使用了層丟棄和早退,并在推理階段使用了自推測解碼。
- 論文:Retrieval Head Mechanistically Explains Long-Context Factuality
- 鏈接:https://arxiv.org/abs/2404.15574
這篇論文探索了具有長上下文能力的基于 Transformer 的模型在其注意力機制中如何使用特定的「檢索頭」來有效地檢索信息。從中揭示出這些頭是普適的、稀疏的、內在的、動態激活的,并且對于需要參考先驗信息或推理的任務至關重要。
- 論文:Graph Machine Learning in the Era of Large Language Models (LLMs)
- 鏈接:https://arxiv.org/abs/2404.14928
這篇綜述論文總結了圖神經網絡和 LLM 正被逐漸整合起來提升圖和推理能力。
- 論文:NExT:Teaching Large Language Models to Reason about Code Execution
- 鏈接:https://arxiv.org/abs/2404.14662
NExT 是一種通過教 LLM 學習分析程序執行來提升 LLM 理解和修復代碼的能力的方法。
- 論文:Multi-Head Mixture-of-Experts
- 鏈接:https://arxiv.org/abs/2404.15045
這篇論文提出的多頭混合專家(MH-MoE)模型可解決稀疏混合專家的專家激活率低和難以應對多語義概念的問題,其做法是引入多頭機制,將 token 拆分成被多個專家并行處理的子 token。參看機器之心的報道《微軟讓 MoE 長出多個頭,大幅提升專家激活率》。
- 論文:A Survey on Self-Evolution of Large Language Models
- 鏈接:https://arxiv.org/abs/2404.14662
這篇論文全面總結了 LLM 的自進化方法,并為 LLM 自進化提出了一個概念框架,另外還給出了提升此類模型的難題和未來方向。
- 論文:OpenELM:An Efficient Language Model Family with Open-source Training and Inference Framework
- 鏈接:https://arxiv.org/abs/2404.14619
蘋果提出的 OpenELM 是一個承襲自 OLMo 的 LLM 套件,包括完整的訓練和評估框架、日志、檢查點、配置和其它可用于復現研究的工件。
- 論文:Phi-3 Technical Report:A Highly Capable Language Model Locally on Your Phone
- 鏈接:https://arxiv.org/abs/2404.14219
Phi-3-mini 是基于 3.3 萬億 token 訓練的 3.8B 參數 LLM,其基準測試性能可以比肩 Mixtral 8x7B 和 GPT-3.5 等更大型模型。
- 論文:How Good Are Low-bit Quantized LLaMA3 Models?An Empirical Study
- 鏈接:https://arxiv.org/abs/2404.14047
這項實證研究發現,Meta 的 LLaMA 3 模型在超低位寬下會出現嚴重的性能下降。
- 論文:The Instruction Hierarchy:Training LLMs to Prioritize Privileged Instructions
- 鏈接:https://arxiv.org/abs/2404.13208
這項研究提出了一種用于 LLM 的指令層級結構,使其可優先處理受信任的 prompt,在無損其標準能力的前提下提升其應對攻擊的穩健性。
- 論文:OpenBezoar:Small, Cost-Effective and Open Models Trained on Mixes of Instruction Data
- 鏈接:https://arxiv.org/abs/2404.12195
這項研究使用來自 Falcon-40B 的合成數據以及 RLHF 和 DPO 等技術對 OpenLLaMA 3Bv2 模型進行了微調,使其憑借系統性過濾和微調數據以更小的模型規模實現了頂尖的 LLM 任務性能。
- 論文:Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
- 鏈接:https://arxiv.org/abs/2404.12253
盡管 LLM 在多種任務上表現出色,但它們難以執行復雜的推理和規劃。這里提出的 AlphaLLM 整合了蒙特卡洛樹搜索,可創建一個自我提升循環,從而無需額外的數據標注也能提升 LLM 執行推理任務的性能。
- 論文:When LLMs are Unfit Use FastFit:Fast and Effective Text Classification with Many Classes
- 鏈接:https://arxiv.org/abs/2404.12365
FastFit 是一個新的 Python 軟件包,可為語言任務快速準確地處理具有很多相似類別的少樣本分類,其做法是整合批量對比學習和 token 層面的相似度分數,可帶來 3-20 倍的訓練速度提升,并且性能也優于 SetFit 和 HF Transformers 等方法。
- 論文:A Survey on Retrieval-Augmented Text Generation for Large Language Models
- 鏈接:https://arxiv.org/abs/2404.10981
這篇綜述論文討論了檢索增強式生成(RAG)是如何將檢索技術與深度學習結合到了一起,這可讓 LLM 動態集成最新信息。這篇文章還對 RAG 過程進行了分類,回顧了近期進展并提出了未來研究方向。
- 論文:How Faithful Are RAG Models?Quantifying the Tug-of-War Between RAG and LLMs' Internal Prior
- 鏈接:https://arxiv.org/abs/2404.10198
提供正確的檢索信息通常能糾正 GPT-4 等大型語言模型的錯誤,但不正確的信息往往會重復,除非被強大的內部知識反擊。
- 論文:Scaling (Down) CLIP:A Comprehensive Analysis of Data, Architecture, and Training Strategies
- 鏈接:https://arxiv.org/abs/2404.08197
這篇論文探索了降低對比式語言 - 圖像預訓練(CLIP)的規模以適配計算預算有限的情況。研究表明,高質量的小規模數據集往往優于大規模低質量數據集,并且對于這些數據集,較小的 ViT 模型是最優的。
- 論文:Is DPO Superior to PPO for LLM Alignment?A Comprehensive Study
- 鏈接:https://arxiv.org/abs/2404.10719
這項研究探索了直接偏好優化(DPO)和近端策略優化(PPO)在根據人類反饋的強化學習(RLHF)中的效果。結果發現,如果使用得當,PPO 可以在所有案例中超越所有其它替代方法。
- 論文:Learn Your Reference Model for Real Good Alignment
- 鏈接:https://arxiv.org/abs/2404.09656
這篇論文展現了新的對齊方法:信任區域直接偏好優化(TR-DPO)。其會在訓練階段更新推理策略;其優于現有技術,能提升在多個參數上的模型質量 —— 在特定數據集上能帶來高達 19% 的性能提升。
- 論文:Chinchilla Scaling:A Replication Attempt
- 鏈接:https://arxiv.org/abs/2404.10102
該論文的作者試圖復現 Hoffmann et al. 提出的一種用于估計計算最優型擴展律的方法,其中發現了與使用其它方法得到的原始估計不一致且難以置信的結果。
- 論文:State Space Model for New-Generation Network Alternative to Transformers:A Survey
- 鏈接:https://arxiv.org/abs/2404.09516
這篇論文給出了對狀態空間模型(SSM)的全面概述和實驗分析。SSM 是 Transformer 架構的一種高效型替代技術。這篇論文詳細說明了 SSM 的原理,其在多個領域的應用,并通過統計數據比較展現了其優勢和潛在的未來研究方向。
- 論文:LLM In-Context Recall is Prompt Dependent
- 鏈接:https://arxiv.org/abs/2404.08865
這項研究評估了多種 LLM 在上下文中進行回憶的能力。其做法是在文本塊中嵌入一個仿真陳述(factoid),然后評估模型在不同條件下檢索這個信息的性能,結果表明該性能會受到 prompt 內容和訓練數據中的潛在偏見的雙重影響。
- 論文:Dataset Reset Policy Optimization for RLHF
- 鏈接:https://arxiv.org/abs/2404.08495
這項研究提出了數據集重置策略優化(DR-PO)。這是一種新的基于人類偏好的反饋的強化學習(RLHF)算法,其能將離線的偏好數據集直接整合進在線的策略訓練,從而提升訓練效果。
- 論文:Pre-training Small Base LMs with Fewer Tokens
- 鏈接:https://arxiv.org/abs/2404.08634
這項研究提出了繼承微調(Inheritune),可用于開發較小型的基礎語言模型。其做法是從大型模型繼承一小部分 transformer 模塊,然后在該大型模型的一小部分數據上進行訓練。結果表明這些小型模型的性能可比肩大型模型,盡管它們使用的訓練數據和資源都少得多。
- 論文:Rho-1:Not All Tokens Are What You Need
- 鏈接:https://arxiv.org/abs/2404.07965
Rho-1 是一種新的語言模型,其訓練過程并未采用傳統的下一 token 預測方法,而是在展現出更高超額損失的 token 上進行選擇性的訓練。
- 論文:Best Practices and Lessons Learned on Synthetic Data for Language Models
- 鏈接:https://arxiv.org/abs/2404.07503
這篇論文總結了 LLM 語境中的合成數據研究。
- 論文:JetMoE:Reaching Llama2 Performance with 0.1M Dollars, Shen, Guo, Cai, and Qin (11 Apr),
- 鏈接:https://arxiv.org/abs/2404.07413
JetMoE-8B 是一個 8B 參數的稀疏門控式混合專家模型,其訓練使用了 1.25 萬億 token,成本不到 10 萬美元,但其憑每輸入 token 2B 參數和「僅僅」30000 GPU 小時數就在性能表現上超過了 Llama2-7B 等成本更高的模型。
- 論文:LLoCO:Learning Long Contexts Offline
- 鏈接:https://arxiv.org/abs/2404.07979
LLoCO 這種方法是將上下文壓縮、檢索和參數高效型微調與 LoRA 結合到一起,從而可以有效地擴展 LLaMA2-7B 模型的上下文窗口,使其可以處理多達 128k token。
- 論文:Leave No Context Behind:Efficient Infinite Context Transformers with Infini-attention
- 鏈接:https://arxiv.org/abs/2404.07143
這項研究提出了一種擴展基于 transformer 的 LLM 的方法,使其可以高效處理無限長的輸入。其思路是在單個 transformer 模塊中組合使用多種注意力策略來處理具有廣泛上下文需求的任務。
- 論文:Adapting LLaMA Decoder to Vision Transformer
- 鏈接:https://arxiv.org/abs/2404.06773
這篇論文研究了基于 Llama 等僅解碼器 transformer LLM 來執行計算機視覺任務,其做法是使用后序列類別 token 和一種軟性掩碼策略等技術來修改標準視覺 Transformer(ViT)。
- 論文:LLM2Vec:Large Language Models Are Secretly Powerful Text Encoders
- 鏈接:https://arxiv.org/abs/2404.05961
這項研究提出了一種簡單的無監督方法,可將解碼器式的 LLM(如 GPT 和 Llama)轉換成強大的文本編碼器,其做法有三:1. 禁用因果注意掩碼、2. 掩碼式下一 token 預測、3. 無監督對比學習。
- 論文:Elephants Never Forget:Memorization and Learning of Tabular Data in Large Language Models
- 鏈接:https://arxiv.org/abs/2404.06209
這篇論文聚焦于 LLM 中的數據污染和記憶形成等關鍵問題,結果發現 LLM 往往會記住常見的表格式數據,并且在訓練期間見過的數據集上表現更好,而這會導致過擬合。
- 論文:MiniCPM:Unveiling the Potential of Small Language Models with Scalable Training Strategies
- 鏈接:https://arxiv.org/abs/2404.06395
這項研究提出了一個新的資源高效型「小」語言模型系列,參數量范圍在 1.2B 到 2.4B 之間;其中使用的技術包括預熱 - 穩定 - 衰減學習率調度器,這對連續預訓練和領域適應很有用。
- 論文:CodecLM:Aligning Language Models with Tailored Synthetic Data
- 鏈接:https://arxiv.org/abs/2404.05875
CodecLM 這個框架是使用編碼 - 解碼原理和 LLM 作為編解碼器自適應地生成用于對齊 LLM 的高質量合成數據,其中包含多種指令分布,能提升 LLM 遵循復雜多樣化指令的能力。
- 論文:Eagle and Finch:RWKV with Matrix-Valued States and Dynamic Recurrence
- 鏈接:https://arxiv.org/abs/2404.05892
Eagle 和 Finch 是基于 RWKV 架構的新序列模型,其中引入了多頭矩陣狀態和動態遞歸等功能。
- 論文:AutoCodeRover:Autonomous Program Improvement
- 鏈接:https://arxiv.org/abs/2404.05427
AutoCodeRover 是一種自動化方法,其使用了 LLM 和高級代碼搜索通過修改軟件程序來解決 GitHub 問題。
- 論文:Sigma:Siamese Mamba Network for Multi-Modal Semantic Segmentation
- 鏈接:https://arxiv.org/abs/2404.04256
Sigma 是一種使用 Siamese Mamba(結構狀態空間模型)網絡進行多模態語義分割的方法,它將熱度和深度等不同模態與 RGB 相結合,可成為 CNN 和視覺 Transformer 的替代方法。
- 論文:Verifiable by Design: Aligning Language Models to Quote from Pre-Training Data
- 鏈接:https://arxiv.org/abs/2404.03862
Quote-Tuning 可提升 LLM 的可信度和準確度(相比于標準模型可提升 55% 到 130%),其做法是讓 LLM 學會更多地逐詞引用可靠來源。
- 論文:ReFT:Representation Finetuning for Language Models
- 鏈接:https://arxiv.org/abs/2404.03592
這篇論文提出了表征微調(ReFT)方法,該方法類似于參數高效型微調(PEFT),能通過僅修改模型的隱藏表征(而不是整套參數)來高效地適應大型模型。
- 論文:CantTalkAboutThis:Aligning Language Models to Stay on Topic in Dialogues
- 鏈接:https://arxiv.org/abs/2404.03820
這篇論文提出了 CantTalkAboutThis 數據集,其設計目的是幫助 LLM 在面向任務的對話中不偏離話題(其中包括多種領域的合成對話,并具有分散話題的內容,可以訓練模型不偏離話題)。
- 論文:Training LLMs over Neurally Compressed Text
- 鏈接:https://arxiv.org/abs/2404.03626
這篇論文提出了一種在經過神經壓縮的文本(使用一個小型語言模型壓縮后的文本)上訓練 LLM 的方法,其中使用了一種名為 Equal-Info Windows 的技術 —— 作用是將文本分割成同等位長的塊。
- 論文:Direct Nash Optimization:Teaching Language Models to Self-Improve with General Preferences
- 鏈接:https://arxiv.org/abs/2404.02151
這篇論文提出了一種用于 LLM 后訓練的方法:直接納什優化(DNO)。該方法是使用來自預言機的偏好反饋來迭代式地提升模型性能,可成為其它 RLHF 方法的替代技術。
- 論文:Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
- 鏈接:https://arxiv.org/abs/2404.02747
這篇論文探究了交叉注意力在文本條件式擴散模型的推理階段的工作方式 —— 研究發現其會在一定位置穩定下來,另外還發現:如果在這個收斂點之后繞過文本輸入,可在無損輸出質量的情況下簡化這個過程。
- 論文:BAdam:A Memory Efficient Full Parameter Training Method for Large Language Models
- 鏈接:https://arxiv.org/abs/2404.02827
BAdam 是一個內存高效型優化器,可以提升微調 LLM 的效率,而且其使用便捷,僅有一個額外的超參數。
- 論文:On the Scalability of Diffusion-based Text-to-Image Generation
- 鏈接:https://arxiv.org/abs/2404.02883
這篇論文通過實證研究了基于擴散的文生圖模型的擴展性質。其中分析了擴展去噪主干模型和訓練集的效果,揭示出:交叉注意力和 transformer 模塊的效率會極大影響性能。另外,論文還給出了以更低成本提升文本 - 圖像對齊和學習效率的策略。
- 論文:Jailbreaking Leading Safety-Aligned LLMs with Simple Adaptive Attacks
- 鏈接:https://arxiv.org/abs/2404.02151
這項研究揭示出:即使圍繞安全而構建的最新 LLM 也會被自適應技術輕松越獄。使用對抗性提示工程、利用 API 漏洞和 token 搜索空間限制等方法,對各種模型都能達到接近 100% 的越獄成功率。
- 論文:Emergent Abilities in Reduced-Scale Generative Language Models
- 鏈接:https://arxiv.org/abs/2404.02204
這項研究發現,如果能將預訓練數據集的規模縮小和簡化,非常「小」的 LLM(參數量從 1M 到 165M)也能展現出涌現性質。
- 論文:Long-context LLMs Struggle with Long In-context Learning
- 鏈接:https://arxiv.org/abs/2404.02060
LIConBench 是一個關注長上下文學習和極端標簽分類的新基準。實驗結果表明,盡管 LLM 擅長處理多達 20K token,但當序列更長時,它們的性能就下降了,只有 GPT-4 例外,這說明在處理上下文信息豐富的文本方面,各個模型之間存在差距。
- 論文:Mixture-of-Depths:Dynamically Allocating Compute in Transformer-Based Language Models
- 鏈接:https://arxiv.org/abs/2404.02258
這篇論文提出的混合深度方法可讓基于 transformer 的語言模型為輸入序列的不同部分動態地分配計算資源(FLOPs),從而可通過在每層選取特定的 token 進行處理而實現對性能和效率的優化。參看機器之心報道《DeepMind 升級 Transformer,前向通過 FLOPs 最多可降一半》。
- 論文:Diffusion-RWKV:Scaling RWKV-Like Architectures for Diffusion Models
- 鏈接:https://arxiv.org/abs/2404.04478
這篇論文提出的 Diffusion-RWKV 是用于 NLP 的 RWKV 架構的一種變體,其中納入了用于圖像生成的擴散模型。
- 論文:The Fine Line:Navigating Large Language Model Pretraining with Down-streaming Capability Analysis
- 鏈接:https://arxiv.org/abs/2404.01204
這項研究發現使用早期階段就能預測最終的 LLM,這有助于在預訓練期間分析 LLM 并改進預訓練設置。
- 論文:Bigger is not Always Better:Scaling Properties of Latent Diffusion Models
- 鏈接:https://arxiv.org/abs/2404.01367
這項研究探討了隱擴散模型的大小對不同步驟和任務的采樣效率有何影響。結果揭示出:在給定推理預算時,較小的模型往往能得到更高質量的結果。參看機器之心報道《大模型一定就比小模型好?谷歌的這項研究說不一定》。
- 論文:Do Language Models Plan Ahead for Future Tokens?
- 鏈接:https://arxiv.org/abs/2404.00859






















