螞蟻金服異常檢測和歸因診斷分析實踐

一、歸因診斷

在實際工作中,我們常常受到業務方對關鍵績效指標(KPI)的靈魂拷問:某個 KPI 指標為什么會上升或下降?歸因診斷的任務就是解釋這些指標變化的原因。

歸因診斷把問題的定位過程看作是一個因子對比的過程:指標在基準時間區間的值為 y,在當前時間區間的值為 y^',兩個時間點相差 ?y。基于這個變化量 ?y 進行因子的拆解,生成一個因子指標樹。在每個葉子節點處,都計算其對整體 ?y 的貢獻度,從而確定哪個因子對整體貢獻最大。
通過以上過程,就能夠解釋 KPI 波動的原因。在實際應用中,可以支持:
- 多時間粒度的對比,包括單天和多天的對比。
- 單指標的對比、多因子的歸因以及復雜的四則運算。
- 維度的組合與下鉆。
- 千萬級數據量級上秒級的智能返回。

接下來舉例說明上述歸因過程。在實際業務中,假設支付成功率從 80% 下降到 60%,如果按照城市的維度,通過將變化量分配給各個城市從而進行歸因診斷,即先計算上海 -15%,北京 -34%,廣州 -16%。然后,將這些城市的變化量除以整體變化量(-20%),得到上海為支付成功率下降貢獻了 75%,北京貢獻了 170%,廣州貢獻了 80% 的結論。這樣的計算方法是存在問題的,因為城市的貢獻求和并不等于 100%。正確的邏輯應該是在計算每個城市的貢獻時,考慮每個城市的分子分母的情況。因此,上海實際在支付成功率上沒有變化,是一個分子分母等比率縮放的情況;而北京和廣州則是都下降了10%,為整體變化量(-20%)各自貢獻了 50%。
通過這樣逐層拆解,可以清晰地看到每個因子對整體的貢獻,解釋具體的變化是由分子還是分母引起的,是由比率變化還是占比變化引起的。這種逐層拆解的邏輯為我們提供了一個全局可比的歸因結論,有助于向業務做出清晰的解釋。

在實際應用中,我們總結出四類方法,用于處理不同的業務場景:
- 控制變量法,適用于簡單的四則運算場景。
- 鏈式法則,可用于處理復雜的四則運算。
- Shapley 值法,適用于連乘場景,我們將其視為合作博弈問題來解決。
- 比率類型法(前文講述的內容)。
這些方法在業務的實際應用中表現出色,取得了顯著的效果。

在剛剛的歸因過程中,雖然將問題歸因到城市維度,但并沒有明確解釋支付成功率下降的具體原因。因此,需要進一步對因子進行歸因,主要分為三個部分:
- 首先是歸因的維度,包括城市等。
- 其次是內部因子,如促銷活動、營銷手段以及運維場景中的一些動作。
- 最后是外部因子,包括通用因素,如疫情、天氣、突發事件等,還包括特殊業務場景、出行場景等。
整個歸因過程會生成一個多元因子庫,基于這個庫,我們重新審視支付成功率下降的問題,得出結論。例如,我們發現北京和廣州的下降是因為受到疫情影響,大學生提前放假導致支付成功率下降。業務方得到這一結論后,可以做出相應的判斷和策略調整,采取營銷手段或其他措施,以解決支付成功率下降的問題,重新提升業務。
二、異常檢測
1. 單指標異常檢測

接下來介紹一下異常檢測,首先從單指標異常檢測入手。在實際業務中,業務方關心的是監控指標何時開始異常告警,以及異常告警何時結束。如果我們能夠了解指標的正常波動區間,就能夠解決這個問題,將告警信息實時、準確地反饋給業務方。

計算一個指標的正常波動區間可以借鑒 STL 時區分解的思路:
首先采用 STL 中通用的 lowess 函數進行趨勢提取,同時提取周期信息,即識別時序中包含的周期以及周期的長度(例如,7 天、30 天、周、月、季度、年、小時等),這里我們借鑒論文中的 FFT 加 ACF 處理邏輯,可以識別出周期。
識別了周期后,下一步是提取周期波形。通過很好地提取周期波形并疊加周期,就能夠有效地進行檢測。
在提取周期波形時,由于周期波形受到營銷活動的影響,振幅可能發生變化,因此還需要引入一些檢測方法進行分段處理,最終獲得相對完整的周期波形進行后續處理。

上圖展示了一個真實案例:根據業務配置的異常敏感度動態調整基線的上下限,識別并監控異常告警的整個生命周期。我們能夠清晰地追蹤何時進入異常狀態,以及何時恢復正常。整個過程都能夠被有效監控。

在這個智能告警的案例中,當系統觸發告警時,可以追溯到異常發生的時刻,隨著告警持續推移,最終系統恢復正常,即自動關閉相應的告警單。這樣一來,運維團隊就不必花費過多精力處理那些自動關閉的告警,而能夠集中精力處理更為緊急的運維任務。
在實際應用中,我們的系統在異常檢測方面有著優異的表現:
- 支持多敏感度的調控,用戶可以根據需要調整異常檢測的敏感度,以求告警更少或更精準。
- 支持在線實時的反饋調優機制,用戶可以通過打標告訴我們單子是否已經恢復,是否是誤報或者是精準的,從而實時調整正常指標的波動區間。
- 支持無監督的增量指標接入,能夠快速接入并實時進行檢測。
- 系統支持全生命周期的監控,并能夠毫秒級地處理,滿足業務性能要求。
2. 多指標異常檢測

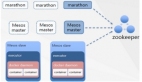
接下來介紹多指標異常檢測的應用。在業務中,面對多個服務器每天產生大量的指標數據,業務方通常關心如何對每臺服務器進行綜合評分,以判斷其是否異常。如圖中,縱軸表示不同的服務器,每層代表一個服務器,橫軸表示時間。隨著時間的推移,每臺服務器都會產生多個指標的數據值。

我們把這個問題定義一下:
- X^j:第 j 個服務器的時間序列數據矩陣。
- X ?_k^j:第 j 個服務器的第 k 個指標時序數據。
- X ?_ki^j:第 j 個服務器的第 k 個指標 i 時刻取值。
上述由時間序列構成的數據矩陣 X^j 能夠全面描述一臺服務器在每個時刻的狀態。那么問題就轉化成了:如果我們能夠表征出一個整體評分,即為每臺服務器 X^j 打一個分數,那么就能綜合反映出該服務器是否出現異常。
接下來將介紹三種方法:
- VBEM 算法
- AnoSVGD 算法
- Autoformer 算法

VBEM 是基于變分推斷(Variational Inference)的期望最大化(Expectation-Maximization)算法。通過隱狀態 q 分布來逼近真實后驗 p 的分布,結合 ELBO 證據下接的似然函數保證模型參數的收斂,整個過程是一個狀態轉移過程。如圖中,x_i 表示學習到的隱狀態,m_0 和 P_0 是模型的初始參數(均值和斜方差)。最終要學到的參數是 A、C、Q、R、μ_1^x、Σ_1^x,分別對應狀態轉移中的權重、均值和協方差的分布,其中 Σ_1^x 是協方差矩陣,包含方差信息和指標之間的相關性,可以很好地表征多指標的信息。

AnoSVGD 方法是我們在 CIKM 2023 年會議上發表的一篇論文。其核心思想是通過映射變換,用已知數據的概率密度函數(Probability Density Function,PDF),多次迭代估計未知數據的概率密度函數(PDF)。通過觀察右側的圖可以看到,在多次迭代之后,模型能夠有效地表征未知數據的分布。每次迭代時,基于前一次的結果,加上一個小的步長和下降方向 θ,通過梯度下降找到最快的下降方向,從而進行迭代。這樣,我們能夠快速地找到未知數據的分布,并在達到目標后停止迭代。

Autoformer 算法的核心在于采用了時序分解的思想,類似于 Transformer 中的self-attention 機制:
- Autoformer 通過 Auto-Correlation 獲取數據中的周期信息。
- 有了周期信息,Autoformer 通過分解的方式將周期波形和趨勢提取出來。
- 在 decoder 階段,通過多次迭代輸出預測值。這里計算 auto collaboration 時采用了與之前周期識別相一致的思想,即使用 FFT 和 ACF。

以上三種方法在完成訓練之后,檢測階段分別需要處理的操作是:
- VBEM 算法,通過訓練隱狀態來生成下一個時刻的預測值,該預測值與真實值之間的差值滿足自由度為 k-1 的卡方分布。結合業務配置的異常敏感度,我們可以識別出哪些點屬于異常點,即是否落在異常區域內。這里的 k-1 的自由度相當于是服務器上不同監控指標的數量。
- AnoSVGD 算法,估計概率密度函數(PDF)后,結合業務敏感度來判斷哪些值位于低概率密度區域,從而進行異常點識別。
- Autoformer 算法,與 VBEM 方法類似,也關注預測值和真實值之間的差異,滿足自由度為 k-1 的卡方分布。在這個基礎上結合業務敏感度來識別異常點。

上述內容為我們在 CIKM 會議上發表的AnoSVGD 方法與其他方法例如 Autoformer、KDE 等方法在公開數據集上的對比結果,我們的 AnoSVGD 取得了非常出色的效果。

在多指標異常檢測之后,仍然需要了解每個指標對當前異常的貢獻度,這就要結合之前提到的歸因診斷能力。例如,在一臺機器上發生了多個指標的異常,發現平均響應時間(RT)和失敗率是主要貢獻異常的核心指標。通過歸因診斷,就可以得出結論:在請求量正常的情況下,平均響應時間和失敗率上升,明顯屬于超時類異常。這種異常一般與部署發布版本更新相關,因此建議 SRE(運維同學)執行發布回滾操作。
在實際應用中,我們已經實現了一些常規操作的自動執行,例如回滾操作。一旦檢測到異常并關聯到歸因結論后,可以通過自動化手段自動回滾機器,恢復到正常狀態。

整體的異常檢測和歸因診斷的過程總結如下:
- 模型訓練、使用不同的算法模型進行訓練。
- 最終進行模型預測,進行異常點檢測。
- 獲得檢測結果后,計算其貢獻度并進行歸因診斷,找出導致異常的具體原因。
再次強調,當前我們的系統:
- 支持多敏感度調控
- 支持在線實時調優,用戶可以實時反饋,在線實時進行調優
- 支持無監督增量指標的快速接入
- 支持多粒度的時間數據,目前主要以分鐘級和小時級為主
- 支持實時歸因診斷
- 支持秒級性能要求

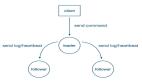
除了之前提到的內容,異常檢測和歸因診斷不僅可以應用于單個業務或機器的異常,還可以應用于整個集群。我們可以通過歷史告警信息,挖掘告警之間的因果關系圖,并結合服務調用圖,當某臺服務器發生告警時,就可以通過異常檢測、歸因診斷和因果發現來分析整個服務器集群鏈路,快速定位整個服務集群中的問題鏈路,確定核心原因和根因。
三、問題與挑戰

最后,總結一下我們所面對的問題和挑戰:
- 在歸因診斷方面,存在辛普森悖論問題,即如何確保在對比時間區間內我們所對比的人群是同質的。如果人群不同質,那么我們得出的結論可能就失去了可信度。
- 在異常檢測方面,在單指標異常檢測中,可能會遇到頻幅泄露問題,導致趨勢周期的錯誤識別和不準確性。此外,無論是單指標還是多指標,都面臨非平穩時序的問題。當時序的趨勢和周期不斷變化時,我們需要思考如何解決這一問題。