Mercury為高性能計算啟用遠程過程調用(RPC)

摘要
遠程過程調用(RPC)是分布式服務廣泛使用的一種技術。 這種技術現在越來越多地用于高性能計算 (HPC) 的上下文中,它允許將例程的執行委托給遠程節點,這些節點可以留出并專用于特定任務。 然而,現有的 RPC 框架采用基于套接字的網絡接口(通常在 TCP/IP 之上),這不適合 HPC 系統,因為此 API 通常不能很好地映射到這些系統上使用的本機網絡傳輸,從而導致網絡性能較低。 此外,現有的 RPC 框架通常不支持處理大數據參數,例如在讀取或寫入調用中發現的參數。我們在本文中提出了一個異步 RPC 接口,專門設計用于 HPC 系統,允許參數和執行請求的異步傳輸和直接支持大數據參數。 該接口是通用的,允許傳送任何函數調用。 此外,網絡實現是抽象的,允許輕松移植到未來的系統并有效使用現有的本地傳輸機制
1、簡介
當在異構環境中工作時,工程師或科學家能夠分配應用程序工作流程的各個步驟通常非常有用; 尤其是在高性能計算中,通常會看到嵌入不同類型資源和庫的系統或節點,這些資源和庫可以專用于特定任務,例如計算、存儲或分析和可視化。 遠程過程調用 (RPC) [1] 是一種遵循客戶端/服務器模型并允許對遠程資源透明地執行本地調用的技術。 它包括將本地函數參數序列化到內存緩沖區并將該緩沖區發送到遠程目標,遠程目標反過來反序列化參數并執行相應的函數調用。 實現該技術的庫可以在各種領域中找到,例如使用 Google Protocol Buffers [2] 或 Facebook Thrift [3] 的 Web 服務,或者使用 GridRPC [4] 的網格計算等領域。 RPC 也可以使用更面向對象的方法和框架來實現,例如 CORBA [5] 或 Java RMI [6],其中抽象對象和方法可以分布在一系列節點或機器上。
但是,在 HPC 系統上使用這些標準和通用的 RPC 框架有兩個主要限制:1. 無法利用本地傳輸機制有效地傳輸數據,因為這些框架主要是在 TCP/IP 協議之上設計的; 2. 并且無法傳輸非常大量的數據,因為 RPC 接口施加的限制通常是兆字節(MB)的數量級。 此外,即使沒有強制限制,通常也不鼓勵通過 RPC 庫傳輸大量數據,主要是由于序列化和編碼帶來的開銷,導致數據在到達遠程節點之前被多次復制。
本論文組織如下: 我們首先在第二部分討論相關工作,然后在第三部分討論構建接口的網絡抽象層,以及為高效傳輸小型和大型數據而定義的架構。 第 IV 節概述了 API 并展示了其支持使用流水線技術的優勢。 然后我們描述了我們接口的網絡傳輸插件的開發以及性能評估結果。 第五節提出結論和未來的工作方向
2、相關工作
網絡文件系統 (NFS) [7] 是使用 RPC 處理大量數據傳輸的一個很好的例子,因此非常接近在 HPC 系統上使用 RPC。 它利用 XDR [8] 序列化任意數據結構并創建獨立于系統的描述,然后將生成的字節流發送到遠程資源,遠程資源可以反序列化并從中取回數據。 它還可以使用單獨的傳輸機制(在最新版本的 NFS 上)通過 RDMA 協議傳輸數據,在這種情況下,數據在 XDR 流之外進行處理。 我們在本文中介紹的接口遵循類似的原則,但另外直接處理批量數據。 它還不限于使用 XDR 進行數據編碼,這可能會影響性能,尤其是當發送方和接收方共享一個公共系統架構時。 通過提供網絡抽象層,我們定義的 RPC 接口使用戶能夠使用小消息或遠程內存訪問 (RMA) 類型的傳輸有效地發送小數據和大數據,這些傳輸完全支持最近 HPC 系統上存在的單邊語義。 此外,所有呈現的接口都是非阻塞的,因此允許異步操作模式,防止調用者等待一個操作執行后再發出另一個操作
I/O 轉發可擴展性層 (IOFSL) [9] 是另一個項目,本文介紹的部分工作基于該項目。 IOFSL 使用 RPC 專門轉發 I/Ocalls。 它定義了一個名為 ZOIDFS 的 API,它在本地序列化函數參數并將它們發送到遠程服務器,在那里它們可以依次映射到文件系統特定的 I/O 操作。 擴展 IOFSL 中已經存在的工作的主要動機之一是能夠不僅發送一組特定的調用(如通過 ZOIDFS API 定義的調用),而且能夠發送各種調用,這些調用可以動態和通用地定義。 同樣值得注意的是,IOFSL 建立在并行虛擬文件系統 (PVFS) [11] 中使用的 BMI [10] 網絡傳輸層之上。它允許支持動態連接和容錯,還定義了兩種類型的消息傳遞, 意外和預期(在第 III-B 節中描述),可以啟用異步操作模式。 然而,BMI 在其設計中受到限制,因為它沒有直接公開顯式實現從客戶端內存到服務器內存的 RDMA 操作所需的 RMA 語義,這可能是一個問題和性能限制(使用 RMA 方法的主要優點在第 III 節中描述 - B). 此外,雖然 BMI 不提供單邊操作,但它確實提供了一組相對較高級別的網絡操作。 這使得將 BMI 移植到新的網絡傳輸(例如 CrayGemini 互連 [12])成為一項重要的工作,并且比它應該更耗時,因為在我們的上下文中實現 RPC 只需要 BMI 提供的功能的一個子集
另一個項目,桑迪亞國家實驗室的 NEtworkScalable 服務接口 (Nessie) [13] 系統提供了一個簡單的 RPC 機制,最初是為 LightweightFile Systems [14] 項目開發的。 它提供了一個異步RPC的解決方案,主要是為了重疊計算和I/O而設計的。 Nessie 的 RPC 接口直接依賴于 Sun XDR 解決方案,該解決方案主要設計用于異構架構之間的通信,即使實際上所有高性能計算系統都是同構的。Nessie 提供了一種單獨的機制來處理批量數據傳輸,它可以使用 RDMA 從一個高效地傳輸數據 內存到另一個,并支持多種網絡傳輸。 Nessie 客戶端使用 RPC 接口將控制消息推送到服務器。 此外,Nessie 公開了一個不同的、單方面的 API(類似于 Portals [15]),用戶可以使用它在客戶端和服務器之間推送或拉取數據。Mercury 不同,因為它的接口本身也支持 RDMA,可以透明地處理 通過自動生成代表遠程大數據參數的抽象內存句柄為用戶提供批量數據,這些句柄更易于操作,不需要用戶做任何額外的工作。如果需要,Mercury 還提供對數據傳輸的細粒度控制(例如,實現流水線)。 此外,Mercury 提供了比 Nessie 更高級的接口,大大減少了實現 RPC 功能所需的用戶代碼量
另一種類似的方法可以在 Decoupledand Asynchronous Remote Transfers (DART) [16] 項目中看到。雖然 DART 未定義為顯式 RPC 框架,但它允許使用客戶端/服務器模型從計算節點上運行的應用程序傳輸大量數據 HPC 系統到本地存儲或遠程位置,以實現遠程應用程序監控、數據分析、代碼耦合和數據歸檔。 DART 試圖滿足的關鍵要求包括最小化應用程序的數據傳輸開銷、實現高吞吐量、低延遲數據傳輸以及防止數據丟失。 為了實現這些目標,DART 的設計使得專用節點(即與應用程序計算節點分離)使用 RDMA 從計算節點的內存中異步提取數據。 通過這種方式,從應用程序計算節點到專用節點的昂貴數據 I/O 和流操作被卸載,并允許應用程序在數據傳輸的同時進行。雖然使用 DART 是不透明的,因此需要用戶發送明確的請求,但有 在我們的網絡抽象層中集成此類框架并沒有固有限制,因此將其包裝在我們定義的 RPC 層中,從而允許用戶在其支持的平臺上使用 DART 傳輸數據。
3、架構
如前一節所述,Mercury 的接口依賴于三個主要組件:網絡抽象層NA、能夠以通用方式處理調用的 RPC 接口和批量數據接口(Bulk),它補充了 RPC 層,旨在輕松傳輸大量數據 通過抽象內存段的數據量。 我們在本節中介紹了整體架構及其每個組件。
A概述
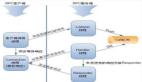
RPC 接口遵循客戶端/服務器架構。 如圖 1 中所述,發出遠程調用會導致不同的步驟,具體取決于與調用關聯的數據的大小。 我們區分兩種類型的傳輸:包含典型函數參數的傳輸,通常很小,稱為元數據(metadata),以及描述大量數據的函數參數的傳輸,稱為批量數據(bulk)。
通過接口發送的每個 RPC 調用都會導致函數參數的序列化 進入內存緩沖區(其大小通常限制為 1 KB,具體取決于互連),然后使用網絡抽象層接口將其發送到服務器。 關鍵要求之一是在傳輸的任何階段限制內存副本,尤其是在傳輸大量數據時。 因此,如果發送的數據很小,它會被序列化并使用小消息發送,否則將在同一條小消息中將要傳輸的內存區域的描述發送到服務器,然后服務器可以開始拉取數據(如果數據 是遠程調用的輸入)或推送數據(如果數據是遠程調用的輸出)。 限制對服務器的初始 RPC 請求的大小也有助于可伸縮性,因為它避免了在大量客戶端同時訪問同一服務器的情況下不必要的服務器資源消耗。 根據所需的控制程度,所有這些步驟都可以由 Mercury 透明地處理或直接暴露給用戶

圖1, 架構概述:每一方都使用一個RPC處理器來序列化和反序列化通過接口發送的參數。調用具有較小參數的函數導致使用網絡抽象層暴露的短消息機制,而包含大數據參數的函數額外使用RMA機制
B. 網絡抽象層
網絡抽象層的主要目的是顧名思義,抽象暴露給用戶的網絡協議,允許通過插件系統集成多種傳輸。 這種架構強加的一個直接后果是提供一個輕量級的接口,為此只需要合理的努力來實現一個新的插件。 接口本身必須定義三種主要類型的數據傳輸機制:意外消息傳遞unexpect、預期消息傳遞expected和遠程內存訪問rma;以及在客戶端和服務器之間動態建立連接所需的額外設置(盡管動態連接可能并不總是可行,具體取決于底層 使用的網絡實現)。意外和預期的消息傳遞僅限于短消息的傳輸,并使用雙向方法。出于性能原因,最大消息大小由互連決定,可以小至幾千字節。 意外消息傳遞的概念用于其他通信協議,例如 BMI [10]。 通過網絡抽象層發送意外消息不需要在完成之前發布匹配的接收。 通過使用這種機制,客戶端不會被阻塞,并且服務器可以在每次發出意外接收時獲取已發布的新消息。 預期消息和意外消息之間的另一個區別是意外消息可以從任何遠程源到達,而預期消息需要知道遠程源。遠程內存訪問 (RMA) 接口允許訪問遠程內存塊(連續和非連續)。 在大多數單向接口和 RDMA 協議中,內存必須先注冊到網絡接口控制器 (NIC) 才能使用。 在網絡抽象層中定義接口的目的是創建一級抽象并定義與大多數 RMA 協議兼容的 API。 將內存段注冊到 NIC 通常會導致創建該段的句柄,其中包含虛擬地址信息等。創建的本地句柄需要在遠程節點可以開始放置或獲取操作之前傳達給遠程節點。 網絡抽象負責確保這些內存句柄可以序列化并通過網絡傳輸。交換句柄后,可以啟動非阻塞放置或獲取。 在大多數互連上,put 和 get 將映射到互連提供的特定 API 提供的 put 和 get 操作。 網絡抽象接口旨在允許在雙向發送和接收網絡協議(例如僅支持雙向消息傳遞方法的 TCP/IP)之上模擬單向傳輸。有了這個網絡抽象層,Mercury 可以很容易地成為 移植以支持新的互連。 網絡抽象提供的相對有限的功能(例如,沒有無限大小的雙向消息)確保接近本機性能
C. RPC 接口和元數據
發送一個只涉及小數據的調用使用了 III-B 中定義的意外/預期消息傳遞。 然而,在更高的層次上,向服務器發送函數調用具體意味著客戶端必須知道如何在開始發送信息之前對輸入參數進行編碼,并且在收到服務器的響應后知道如何解碼輸出參數。 在服務器端,服務器還必須知道在收到 RPC 請求時要執行什么,以及如何對輸入和輸出參數進行解碼和編碼。 描述函數調用和編碼/解碼參數的框架是我們接口操作的關鍵

圖 2:RPC 調用的異步執行流程。 接收緩沖區是預先發布的,允許客戶端在遠程執行調用并發回響應的同時完成其他工作
其中一個要點是能夠支持一組可以以通用方式發送到服務器的函數調用,從而避免一組硬編碼例程的限制。通用框架如圖 2 所示。在初始化階段, 客戶端和服務器通過使用映射到每個操作的唯一 ID 的唯一函數名稱注冊編碼和解碼函數,由客戶端和服務器共享。 服務器還注冊了在通過函數調用接收到操作 ID 時需要執行的回調。 要發送不涉及批量數據傳輸的函數調用,客戶端將輸入參數與該操作 ID 一起編碼到緩沖區中,并使用非阻塞的非預期消息傳遞協議將其發送到服務器。 為了確保完全異步,用于從服務器接收響應的內存緩沖區也由客戶端預先發布。 出于效率和資源消耗的原因,這些消息的大小受到限制(通常為幾千字節)。但是,如果元數據超過意外消息的大小,客戶端將需要在單獨的消息中傳輸元數據,從而透明地使用批量數據 III-D 中描述的接口,用于向服務器公開額外的元數據
當服務器收到一個新的請求 ID 時,它會查找相應的回調、解碼輸入參數、執行函數調用、對輸出參數進行編碼并開始將響應發送回客戶端。 將響應發送回客戶端也是非阻塞的,因此,在接收新的函數調用時,服務器還可以測試響應請求列表以檢查它們是否完成,并在操作完成時釋放相應的資源。 一旦客戶端知道已經收到響應(使用等待/測試調用)并且函數調用已經遠程完成,它就可以解碼輸出參數和用于傳輸的免費資源。有了這個機制,它 變得易于擴展以處理大量數據
D. 大塊數據接口
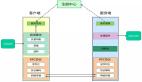
除了前面的接口,一些函數調用可能需要傳輸更大量的數據。 對于這些函數調用,使用了批量數據接口,它建立在網絡抽象層中定義的遠程內存訪問協議之上。 只有 RPC 服務器啟動單向傳輸,以便它可以在控制數據流的同時保護其內存免受并發訪問。

如圖 3 中所述,批量數據傳輸接口使用單向通信方法。 RPC 客戶端通過創建批量數據描述符(包含虛擬內存地址信息、正在公開的內存區域的大小以及可能取決于底層網絡實現的其他參數)向 RPC 服務器公開內存區域。 然后可以將批量數據描述符序列化并與 RPC 請求參數一起發送到 RPC 服務器(使用 III-C 節中定義的 RPC 接口)。 當服務器對輸入參數進行解碼時,它反序列化批量數據描述符并獲取必須傳輸的內存緩沖區的大小
在RPC請求消耗大數據參數的情況下,RPC服務器可能會分配需要接收的數據大小的緩沖區,通過創建批量數據塊描述符暴露其本地內存區域并發起異步讀取/ 獲取對該內存區域的操作。 RPC 服務器然后等待/測試操作的完成,并在數據完全接收后執行調用(如果執行調用支持它,則部分接收)。 然后將響應(即調用的結果)發送回 RPC 客戶端并釋放內存句柄
通過此過程傳輸數據對用戶來說是透明的,尤其是因為 RPC 接口還可以負責序列化/反序列化內存句柄以及其他參數。 當必須傳輸非連續的內存段時,這一點尤為重要。 在這兩種情況下,內存段都會自動注冊到 RPC 客戶端,并由創建的內存句柄抽象出來。 然后內存句柄與 RPC 函數的參數一起序列化,并使用非連續內存區域傳輸大數據,因此導致與上述相同的過程。 請注意,在這種情況下,句柄可能是可變大小的,因為它可能包含更多信息,并且還取決于可以支持直接注冊內存段的底層網絡實現
IV.評估
先前定義的體系結構使通用 RPC 調用能夠與句柄一起傳送,這些句柄可以在需要批量數據傳輸時描述連續和非連續的內存區域。 我們將在本節介紹如何利用此體系結構來構建可以輕松按需請求數據塊的流水線機制。 流水線批量數據傳輸流水線傳輸是一個典型的用例,當人們想要重疊通信和執行時。 在我們描述的架構中,請求處理大量數據會導致從 RPC 客戶端向 RPC 服務器發送 RPC 請求以及批量數據傳輸。
A. 流水線批量數據傳輸
在一個常見的用例中,服務器可能會在執行請求的調用之前等待接收到全部數據。 然而,通過流水線傳輸,實際上可以在數據傳輸時開始處理數據,避免為整個 RMA 傳輸支付延遲成本。 請注意,盡管我們在下面的示例中重點關注這一點,但如果 RPC 服務器沒有足夠的內存來處理需要發送的所有數據,使用此技術也可能特別有用,在這種情況下,它還需要在處理時傳輸數據
RPC 客戶端代碼的簡化版本如下所示
#define BULK_NX 16
#define BULK_NY 128
int main(int argc, char *argv[])
{
hg_id_t rpc_id;
write_in_t in_struct;
write_out_t out_struct;
hg_request_t rpc_request;
int buf[BULK_NX][BULK_NY];
hg_bulk_segment_t segments[BULK_NX];
hg_bulk_t bulk_handle = HG_BULK_NULL;
/* Initialize the interface */
[...]
/* Register RPC call */
rpc_id = HG_REGISTER("write",
write_in_t, write_out_t);
/* Provide data layout information */
for (i = 0; i < BULK_NX ; i++) {
segments[i].address = buf[i];
segments[i].size = BULK_NY * sizeof(int);
}
/* Create bulk handle with segment info */
HG_Bulk_handle_create_segments(segments,
BULK_NX, HG_BULK_READ_ONLY, &bulk_handle);
/* Attach bulk handle to input parameters */
[...]
in_struct.bulk_handle = bulk_handle;
/* Send RPC request */
HG_Forward(server_addr, rpc_id,
&in_struct, &out_struct, &rpc_request);
/* Wait for RPC completion and response */
HG_Wait(rpc_request, HG_MAX_IDLE_TIME,
HG_STATUS_IGNORE);
/* Get output parameters */
[...]
ret = out_struct.ret;
/* Free bulk handle */
HG_Bulk_handle_free(bulk_handle);
/* Finalize the interface */
[...]
}客戶初始化時,它會注冊RPC調用它想要發送。 因為此調用涉及非連續的批量數據轉換器,所以記憶段描述了創建和注冊的內存區域。 由此產生的Bulk_handle Isthen與其他CallParameter一起傳遞給HG_Forward調用。 然后,可以在請求完成后等待響應并免費的thebulk句柄(將來也會發送通知可能允許較早的散裝句柄,因此可以取消內存的內存)。管道上的機制發生在服務器上。 ,要照顧批量轉移。 管道本身具有HEREA固定管道尺寸和管道緩沖區大小。 RPC服務器代碼簡化了
#define PIPELINE_BUFFER_SIZE 256
#define PIPELINE_SIZE 4
int rpc_write(hg_handle_t handle)
{
write_in_t in_struct;
write_out_t out_struct;
hg_bulk_t bulk_handle;
hg_bulk_block_t bulk_block_handle;
hg_bulk_request_t bulk_request[PIPELINE_SIZE];
void *buf;
size_t nbytes, nbytes_read = 0;
size_t start_offset = 0;
/* Get input parameters and bulk handle */
HG_Handler_get_input(handle, &in_struct);
[...]
bulk_handle = in_struct.bulk_handle;
/* Get size of data and allocate buffer */
nbytes = HG_Bulk_handle_get_size(bulk_handle);
buf = malloc(nbytes);
/* Create block handle to read data */
HG_Bulk_block_handle_create(buf, nbytes,
HG_BULK_READWRITE, &bulk_block_handle);
/* Initialize pipeline and start reads */
for (p = 0; p < PIPELINE_SIZE; p++) {
size_t offset = p * PIPELINE_BUFFER_SIZE;
/* Start read of data chunk */
HG_Bulk_read(client_addr, bulk_handle,
offset, bulk_block_handle, offset,
PIPELINE_BUFFER_SIZE, &bulk_request[p]);
}
while (nbytes_read != nbytes) {
for (p = 0; p < PIPELINE_SIZE; p++) {
size_t offset = start_offset +
p * PIPELINE_BUFFER_SIZE;
/* Wait for data chunk */
HG_Bulk_wait(bulk_request[p],
HG_MAX_IDLE_TIME, HG_STATUS_IGNORE);
nbytes_read += PIPELINE_BUFFER_SIZE;
/* Do work (write data chunk) */
write(buf + offset, PIPELINE_BUFFER_SIZE);
/* Start another read */
offset += PIPELINE_BUFFER_SIZE * 51 PIPELINE_SIZE;
if (offset < nbytes) {
HG_Bulk_read(client_addr,
bulk_handle, offset,
bulk_block_handle, offset,
PIPELINE_BUFFER_SIZE,
&bulk_request[p]);
} else {
/* Start read with remaining piece */
}
}
start_offset += PIPELINE_BUFFER_SIZE
* PIPELINE_SIZE;
}
/* Free block handle */
HG_Bulk_block_handle_free(bulk_block_handle);
free(buf);
/* Start sending response back */
[...]
out_struct.ret = ret;
HG_Handler_start_output(handle, &out_struct);
}
int main(int argc, char *argv[])
{
/* Initialize the interface */
[...]
/* Register RPC call */
HG_HANDLER_REGISTER("write", rpc_write,
write_in_t, write_out_t);
while (!finalized) {
/* Process RPC requests (non-blocking) */
HG_Handler_process(0, HG_STATUS_IGNORE);
}
/* Finalize the interface */
[...]
}每個RPC服務器初始化后,都必須繞過HG_HANDLER_PROCESS調用,該調用將等待新的RPCRequests并執行相應的注冊回調(在同一線程或新線程中取決于用戶需求)。 必經請求的請求,用于獲取要傳輸的數據的總尺寸的Bulk_handle參數可以分配適當大小的緩沖區并啟動批量的DataTransfers。 在此示例中,管道尺寸設置為4,并且Pipeline緩沖區大小設置為256,這意味著啟動了4個256個字節的RmareQuests。 然后,可以等待第一個256個字節到達并進行處理。 當它處理時,其他零件可能會到達。 一旦一件被處理了一件,就開始了iSAT階段4的新的RMA轉移,并且可以等待下一個件,然后對其進行處理。 請注意,雖然在客戶端上注冊的內存區域是不合格的,但hg_bulk_read呼叫theserver將其顯示為連續區域,簡化了服務器代碼。 此外,可以給出邏輯偏移(相對于數據的開頭)單獨移動數據片,而大量數據接口將映射從連續邏輯偏移到非連接的客戶端內存區域。我們繼續此過程,直到所有過程 數據已被讀取 /處理,響應(即功能調用的結果)可以發送回。 同樣,我們僅通過調用HG_HANDLER_START_OUTPUT調用來開始發送響應,并且僅通過調用HG_HANDLER_PROCESS來測試其完成,在這種情況下,與響應相關的資源將受到影響。 請注意,所有函數都支持異步執行,如果需要,可以在事件驅動的代碼中使用Mercury(HG)
B.網絡插件和測試環境
截至本文撰寫的日期已經開發了兩個插件,以說明網絡抽象層的功能。 此時,尚未優化插件的性能。 一個建立在BMI頂部[10]。 但是,AS我們已經在第二節中指出的是,BMI并未有效利用已定義的網絡行動層和單方面的批量數據傳輸結構。 另一個建立在MPI [17]的頂部,該[17]僅提供完整的RMA語義[18]最近的MPI3 [19]。 許多MPI實現,特別是已經安裝的機器的Thosedelas,尚無ProvideAll MPI3功能。 由于尚未將BMI移植到室內HPC系統,以說明功能和測量性能結果,因此我們僅考慮MPI插件本文。 該插件能夠在現有的HPCSystems上運行,僅限于MPI-2功能(例如Cray Systems),在兩面消息的頂部實現批量數據傳輸。在實踐中,這意味著對于每個批量數據傳輸, 需要將控制消息發送到theclient,以請求發送或接收數據。 然后,可以使用進度線程輸入進度功能來實現轉移的進度。對于測試,我們使用兩個不同的HPC系統。 onis是一個Infiniband QDR 4X群集,帶有mvapich [20] 1.8.1,另一個是帶有Cray MPT的Cray Xe6 [21] 5.6.0
C. 性能評估


作為第一個實驗的性能評估,我們測量了為空函數(即,即將返回的函數)所花費的小時RPC調用(沒有任何批量數據傳輸)。 在Cray XE6機器上,測量了20個RPC調用的雜種時間,每個呼叫花費了23 μ。 但是,正如前面指出的那樣,大多數HPC系統都是均勻的,因此不需要XDR提供的數據可移植性。 禁用Xdrencoding(改為執行簡單的存儲器副本)時,THETIME會降至20 μs。 這種不可忽略的改進(15%)證明了針對HPC環境設計RPC框架的好處。 第二個實驗包括測試以前在客戶端和一臺服務器之間解釋的批量數據傳輸的管道技術傳輸。 如表I所示,在cray xe6訪問轉移時,當請求刀片已經完成時,在進行其他管道階段時,可以特別有效地效率,從而使我們獲得很高的帶寬。 但是,該系統上的高注入帶寬使得很難為小數據包(例如,由于單側功能的模擬,該系統的批量數據控制消息)很難獲得良好的性能),特別是當數據流不連續的情況下
最后,我們評估了RPC Serverby的可伸縮性,在增加客戶端時數時評估了總數據吞吐量。 圖4和5分別顯示了AQDR Infiniband系統(使用MVAPICH)和CRAY XE6SYSTEM的結果。 在這兩種情況下,部分由于服務器sidebulk數據流控制機制,HG顯示出卓越的性能,并且吞吐量增加或剩余stableas,并發客戶的數量增加。 為了進行比較,顯示了每個系統上的點消息帶寬。在Infiniband系統中,Mercury達到了最大網絡帶寬的70%。 考慮到HG時間代表了數據傳輸的RPC調用,這是一個很好的結果,與發送OSU基準的Asingle消息的時間相比。 在Cray系統上,性能不佳(約占峰值的40%)。 我們期望這主要是由于該系統的較小信息性能,以及由單方面仿真引起的額外控制措施。 然而,低性能也可能是由系統限制引起的,考慮到 Nessie 的類似操作(讀取)[22] 的性能顯示相同的低帶寬,即使它通過繞過 MPI 并使用真正的 RDMA interconnect 的原生 uGNI API
V.結論和未來的工作
在本文中,我們介紹了Mercury框架。 Mercury專門設計用于在高性能計算環境中提供RPC服務。 Mercury構建了與當代HPC網絡環境的功能相匹配的小型,易于移植的網絡抽象層。 與大多數其他RPC框架不同,Mercury為處理遠程呼叫的大型數據參數提供了直接支持。 Mercury的網絡協議旨在擴展到數千個客戶。 我們通過實施遠程寫入功能(包括大型數據參數的管道)來證明框架的力量。 我們隨后在兩個不同的 HPC 系統上評估了我們的實施,展示了單客戶端性能和多客戶端可擴展性。
在Mercury提供的高性能,便攜式,通用的RPC功能的可用性中,IOFSL可以通過替換內部,硬codediofsl代碼來替換和現代化 通過水Mercury Call。 由于網絡抽象的層面頂部已經構建了HG的頂部,因此已經使用BMI Fornetwork連接性支持IOFSL Continueto的現有部署,同時利用了Mercury的NetworkProtocol的改進性可伸縮性和性能。 RPC呼叫。 取消對節點或網絡可能失敗的彈性非環境很重要。 未來的工作將包括對取消的支持。雖然 Mercury 已經支持高效執行 RPC 調用所需的所有功能,但可以進一步減少每次調用所需的用戶代碼量。 Mercury 的未來版本將提供一組預處理器宏,通過自動生成盡可能多的樣板代碼來減少用戶的工作量, 網絡抽象層當前具有用于BMI,MPI-2和MPI-3的插件。 但是,作為在客戶端/服務器上下文中使用的MPI RMA功能[23],我們打算增加對Infiniband網絡的支持,以及Cray XT andibm BG/P和Q網絡
致謝,本文介紹的工作得到了 Exascale FastForward 項目的支持,LLNS 分包合同號。 B599860,由美國能源部科學辦公室高級科學計算機研究辦公室根據合同 DE-AC02-06CH11357 提供。
參考
論文鏈接: https://www.mcs.anl.gov/papers/P4082-0613_1.pdf。
[1] A. D. Birrell and B. J. Nelson, “Implementing Remote Procedure Calls,” ACM Trans. Comput. Syst., vol. 2, no. 1, pp. 39–59, Feb. 1984。
[2] Google Inc, “Protocol Buffers,” 2012. [Online]. Available: https://developers.google.com/protocol-buffers。
[3] M. Slee, A. Agarwal, and M. Kwiatkowski, “Thrift: Scalable CrossLanguage Services Implementation,” 2007。
[4] K. Seymour, H. Nakada, S. Matsuoka, J. Dongarra, C. Lee, and H. Casanova, “Overview of GridRPC: A Remote Procedure Call API for Grid Computing,” in Grid Computing—GRID 2002, ser. Lecture Notes in Computer Science, M. Parashar, Ed. Springer Berlin Heidelberg, 2002, vol. 2536, pp. 274–278。
[5] Object Management Group, “Common Object Request Broker Architecture (CORBA),” 2012. [Online]. Available: http://www.omg.org/ spec/CORBA。
[6] A. Wollrath, R. Riggs, and J. Waldo, “A Distributed Object Model for the JavaTMSystem,” in Proceedings of the 2nd conference on USENIX Conference on Object-Oriented Technologies (COOTS) - Volume 2, ser. COOTS’96. Berkeley, CA, USA: USENIX Association, 1996, pp.17–17。
[7] R. Sandberg, D. Golgberg, S. Kleiman, D. Walsh, and B. Lyon, “Innovations in internet working,” C. Partridge, Ed. Norwood, MA, USA: Artech House, Inc., 1988, ch. Design and Implementation of the Sun Network Filesystem, pp. 379–390。
[8] Sun Microsystems Inc, “RFC 1014—XDR: External Data Representation Standard,” 1987. [Online]. Available: http://tools.ietf.org/html/rfc1014。
[9] N. Ali, P. Carns, K. Iskra, D. Kimpe, S. Lang, R. Latham, R. Ross, L. Ward, and P. Sadayappan, “Scalable I/O forwarding framework for high-performance computing systems,” in IEEE International Conference on Cluster Computing and Workshops 2009, ser. CLUSTER ’09, 2009, pp. 1–10。
[10] P. Carns, I. Ligon, W., R. Ross, and P. Wyckoff, “BMI: a networkabstraction layer for parallel I/O,” in 19th IEEE International Parallel and Distributed Processing Symposium, 2005。
[11] P. H. Carns, W. B. Ligon, III, R. B. Ross, and R. Thakur, “PVFS: A Parallel File System for Linux Clusters,” in In Proceedings of the 4th Annual Linux Showcase and Conference. USENIX Association, 2000, pp. 317–327。
[12] R. Alverson, D. Roweth, and L. Kaplan, “The Gemini System Interconnect,” in IEEE 18th Annual Symposium on High-Performance Interconnects, ser. HOTI, 2010, pp. 83–87。
[13] J. Lofstead, R. Oldfield, T. Kordenbrock, and C. Reiss, “Extending Scalability of Collective IO Through Nessie and Staging,” in Proceedings of the Sixth Workshop on Parallel Data Storage, ser. PDSW ’11. New York, NY, USA: ACM, 2011, pp. 7–12。
[14] R. Oldfield, P. Widener, A. Maccabe, L. Ward, and T. Kordenbrock,“Efficient Data-Movement for Lightweight I/O,” in Cluster Computing,2006 IEEE International Conference on, 2006, pp. 1–9。
[15] R. Brightwell, T. Hudson, K. Pedretti, R. Riesen, and K. Underwood, “Implementation and Performance of Portals 3.3 on the Cray XT3,” in Cluster Computing, 2005. IEEE International, 2005, pp. 1–10。
[16] C. Docan, M. Parashar, and S. Klasky, “Enabling High-speed Asynchronous Data Extraction and Transfer Using DART,” Concurr. Comput. : Pract. Exper., vol. 22, no. 9, pp. 1181–1204, Jun. 2010。
[17] W. Gropp, E. Lusk, and R. Thakur, Using MPI-2: Advanced Features of the Message-Passing Interface. Cambridge, MA: MIT Press, 1999。
[18] W. Gropp and R. Thakur, “Revealing the Performance of MPI RMA Implementations,” in Recent Advances in Parallel Virtual Machine and Message Passing Interface, ser. Lecture Notes in Computer Science, F. Cappello, T. Herault, and J. Dongarra, Eds. Springer Berlin / Heidelberg, 2007, vol. 4757, pp. 272–280。
[19] “Message Passing Interface Forum,” September 2012, MPI-3: Extensions to the message-passing interface. [Online]. Available: http://www.mpi-forum.org/docs/docs.html。
[20] The Ohio State University, “MVAPICH: MPI over InfiniBand, 10GigE/iWARP and RoCE.” [Online]. Available: http://mvapich.cse. ohio-state.edu/index.shtml。
[21] H. Pritchard, I. Gorodetsky, and D. Buntinas, “A uGNI-Based MPICH2 Nemesis Network Module for the Cray XE,” in Recent Advances in the Message Passing Interface, ser. Lecture Notes in Computer Science, Y. Cotronis, A. Danalis, D. Nikolopoulos, and J. Dongarra, Eds. Springer Berlin / Heidelberg, 2011, vol. 6960, pp. 110–119。
[22] R. A. Oldfield, T. Kordenbrock, and J. Lofstead, “Developing integrated data services for cray systems with a gemini interconnect,” Sandia National Laboratories, Tech. Rep., 2012。
[23] J. A. Zounmevo, D. Kimpe, R. Ross, and A. Afsahi, “On the use of MPI in High-Performance Computing Services,” p. 6, 2013。
本文轉載自微信公眾號「云原生云」,可以通過以下二維碼關注。轉載本文請聯系云原生云公眾號。