













從 MMU 看內(nèi)存管理
本文轉(zhuǎn)載自微信公眾號(hào)「程序員cxuan」,作者cxuan。轉(zhuǎn)載本文請(qǐng)聯(lián)系程序員cxuan公眾號(hào)。
在計(jì)算機(jī)早期的時(shí)候,計(jì)算機(jī)是無法將大于內(nèi)存大小的應(yīng)用裝入內(nèi)存的,因?yàn)橛?jì)算機(jī)讀寫應(yīng)用數(shù)據(jù)是直接通過總線來對(duì)內(nèi)存進(jìn)行直接操作,對(duì)于寫操作來說,計(jì)算機(jī)會(huì)直接將地址寫入內(nèi)存;對(duì)于讀操作來說,計(jì)算機(jī)會(huì)直接讀取內(nèi)存的數(shù)據(jù)。
但是隨著軟件的不斷膨脹和移動(dòng)應(yīng)用的到來,一切慢慢變了。
我們想要手機(jī)既能夠運(yùn)行微信,同時(shí)又能夠運(yùn)行 QQ 音樂,還希望能夠聊微博、刷知乎以及看股票。如果我們的手機(jī)內(nèi)存只有 1G,那么顯然是無法滿足這些應(yīng)用的,因?yàn)槲⑿诺暮笈_(tái)程序都占用 1G 多內(nèi)存了。那么就會(huì)有人說,把內(nèi)存容量提高不就行了嗎?這句話看似沒錯(cuò),但是內(nèi)存的造價(jià)成本非常昂貴,而且內(nèi)存的容量是永遠(yuǎn)追不上應(yīng)用程序所占用的容量的,把所有應(yīng)用程序直接堆入內(nèi)存也只是飲鴆止渴,因?yàn)榧词故嵌嗪司€程持續(xù)不斷的進(jìn)行計(jì)算,也會(huì)存在性能瓶頸。
客戶都是難搞的,我們并不希望正在使用微信,而后臺(tái)卻運(yùn)行一些其他沒有必要的應(yīng)用,比如說旅游軟件、郵箱等。所以站在用戶的角度上來說,線程切換到這些應(yīng)用上是完全沒有必要的。
基于上述這些考量,工程師們認(rèn)為一直擴(kuò)大內(nèi)存容量并不能解決根本問題。
就像是軟件架構(gòu)一樣,盲目追求高性能并不一定可取,需要同時(shí)兼顧 CAP 的各個(gè)原則。
后來,提出了一種虛擬內(nèi)存(virtual memory)思想,虛擬內(nèi)存是操作系統(tǒng)的一種抽象,虛擬內(nèi)存的主要思想是:每個(gè)程序都有自己的地址空間,程序間的地址空間彼此不可見,我們的程序首先要先運(yùn)行在虛擬內(nèi)存中,虛擬內(nèi)存會(huì)分為多個(gè)塊,每個(gè)塊稱為一頁(yè)或者頁(yè)面(page),每一頁(yè)有連續(xù)的地址范圍,這些頁(yè)會(huì)被映射到物理內(nèi)存,當(dāng)程序引用到一部分在物理內(nèi)存的地址空間時(shí),會(huì)由硬件完成對(duì)應(yīng)的映射過程,當(dāng)程序引用到不在物理內(nèi)存的地址空間時(shí),由操作系統(tǒng)負(fù)責(zé)將缺失(不在內(nèi)存)的部分裝入物理內(nèi)存并重新執(zhí)行。
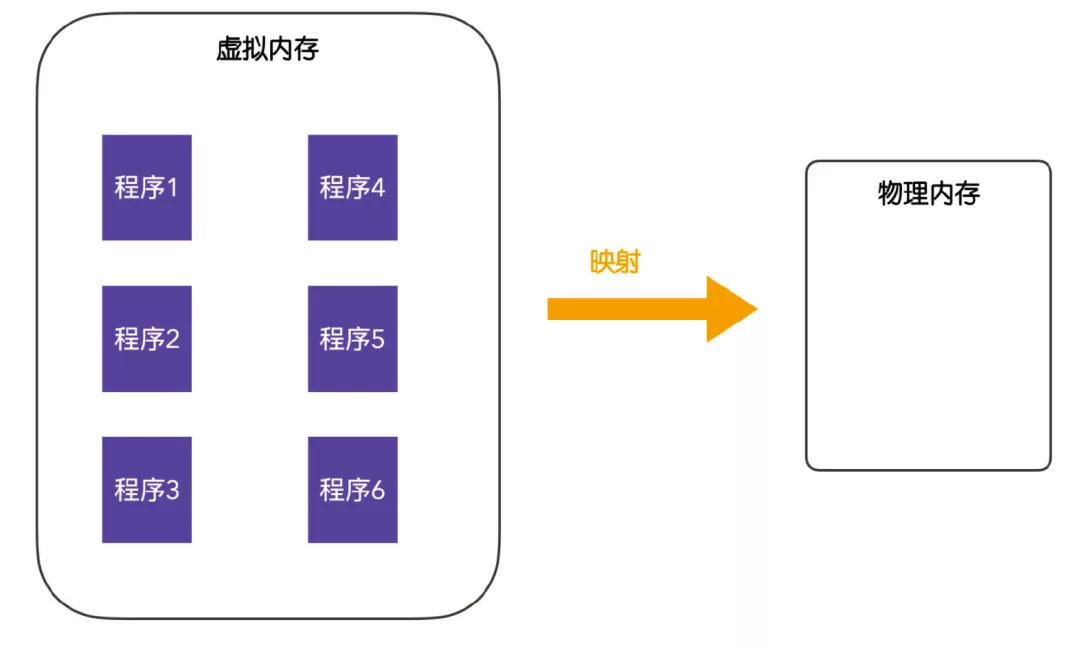
虛擬內(nèi)存系統(tǒng)是一種管理和分配程序虛擬內(nèi)存的程序,在使用虛擬內(nèi)存的情況下,虛擬地址不會(huì)直接映射到物理內(nèi)存中,而是會(huì)直接輸送到內(nèi)存管理單元(Memory Management Unit,MMU),由 MMU 將虛擬地址映射為物理內(nèi)存地址。執(zhí)行這個(gè)映射過程的技術(shù)就叫做分頁(yè)(paging)。
MMU 是一塊單獨(dú)的芯片,它可以獨(dú)立存在,不過現(xiàn)代 OS 都把它內(nèi)置在了 CPU 中。
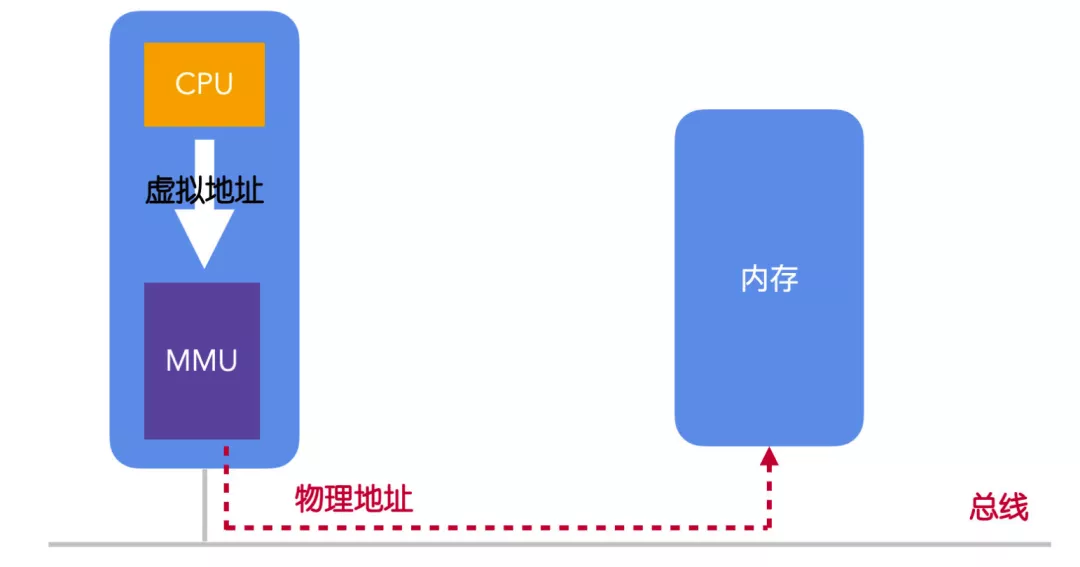
但是,映射到物理內(nèi)存的哪個(gè)位置?映射的規(guī)則又是什么?
實(shí)際上,物理內(nèi)存的劃分其實(shí)和虛擬內(nèi)存是一樣的,在物理內(nèi)存中,也會(huì)被劃分為一個(gè)個(gè)的頁(yè)框(page frame),頁(yè)框是內(nèi)存所劃分的存儲(chǔ)單元,與虛擬內(nèi)存中的頁(yè)所不同的是,頁(yè)框是主存中的物理屬性,而頁(yè)面只是一種虛擬的抽象表示。頁(yè)面和頁(yè)框的存儲(chǔ)大小通常是一樣的,一般是 4KB。
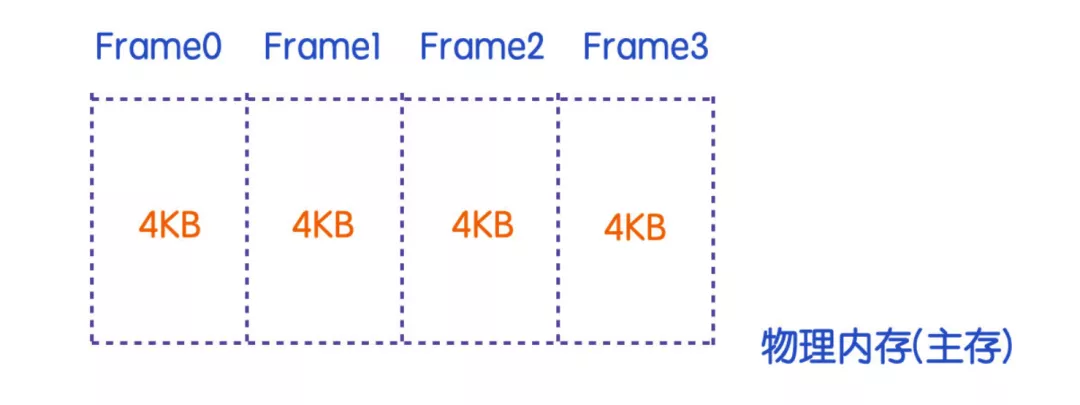
通過 MMU 的幫助,可以有效地將虛擬地址映射到物理內(nèi)存地址,這也就是說,頁(yè)面可以和頁(yè)框進(jìn)行合理的映射。但是這并沒有解決虛擬地址空間比物理內(nèi)存空間大的這個(gè)問題。當(dāng) CPU 進(jìn)行數(shù)據(jù)寫入時(shí),MMU 會(huì)判斷數(shù)據(jù)寫入的頁(yè)面是否已經(jīng)映射到頁(yè)框中,如果沒有映射的話,CPU 會(huì)陷入(trap)到操作系統(tǒng),這個(gè)陷入的過程稱為缺頁(yè)中斷或者叫做缺頁(yè)錯(cuò)誤(page fault)。
之后,操作系統(tǒng)會(huì)找到一個(gè)空閑的頁(yè)框并將它的內(nèi)容寫入到頁(yè)框中(這個(gè)頁(yè)框其實(shí)是在磁盤中,因?yàn)椴僮飨到y(tǒng)不會(huì)一次性把所有的頁(yè)框都加載到內(nèi)存中,而是按需加入),然后修改頁(yè)框和頁(yè)面的映射關(guān)系,再重新啟動(dòng) trap 陷入的指令。
上面說到,MMU 會(huì)判斷數(shù)據(jù)寫入的頁(yè)面是否已經(jīng)映射到了頁(yè)框中,這個(gè)是如何判斷的呢?
實(shí)際上,MMU 中有一個(gè)叫做頁(yè)表(page table)的結(jié)構(gòu),這個(gè)頁(yè)表就記錄了頁(yè)面和頁(yè)框的映射關(guān)系,上面所聊到修改頁(yè)框和頁(yè)面的映射關(guān)系,實(shí)際上就是修改頁(yè)表中的一個(gè)在/不在位的數(shù)據(jù)項(xiàng),關(guān)于頁(yè)表的結(jié)構(gòu),我們后面回說。
下面來看一下頁(yè)面和頁(yè)框的映射關(guān)系圖。
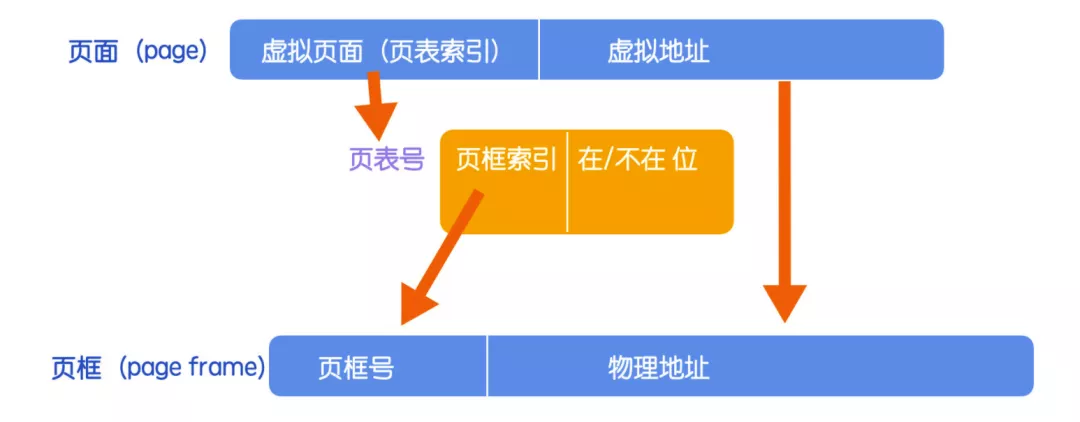
根據(jù)頁(yè)面中的頁(yè)表索引可以找到對(duì)應(yīng)的頁(yè)表號(hào),根據(jù)頁(yè)表中的頁(yè)框索引可以找到頁(yè)框號(hào),這種映射關(guān)系就很類似計(jì)算機(jī)網(wǎng)絡(luò)中的路由表(記錄各個(gè)數(shù)據(jù)轉(zhuǎn)發(fā)路徑)。從數(shù)學(xué)的角度來講,可以把頁(yè)表看做是一個(gè)函數(shù),它的參數(shù)是頁(yè)表索引(通常也叫做虛擬頁(yè)號(hào)),結(jié)果是頁(yè)框號(hào),通過這個(gè)函數(shù)可以將虛擬地址中的虛擬頁(yè)面轉(zhuǎn)換成頁(yè)框號(hào),然后形成物理地址。
這里強(qiáng)調(diào)一點(diǎn):如果在/不在位是 0 的話,說明該頁(yè)面和頁(yè)框沒有存在映射關(guān)系,此時(shí)就會(huì)直接引起操作系統(tǒng)陷入,由操作系統(tǒng)找到對(duì)應(yīng)的頁(yè)框執(zhí)行寫入,寫入完成后修改頁(yè)面和頁(yè)框的映射關(guān)系,然后回到引起陷入的位置繼續(xù)執(zhí)行。
上面提到了頁(yè)表是記錄頁(yè)面和頁(yè)框映射關(guān)系的一個(gè)結(jié)構(gòu),下面我們就來聊一下頁(yè)表項(xiàng)的結(jié)構(gòu)。不同機(jī)器的頁(yè)表結(jié)構(gòu)是不一樣的,但是大多數(shù)頁(yè)表項(xiàng)都具有下面這個(gè)結(jié)構(gòu)。

對(duì)于頁(yè)表項(xiàng)這個(gè)結(jié)構(gòu)來說,最重要的就是頁(yè)框號(hào),頁(yè)框號(hào)相當(dāng)于是頁(yè)表的身份證,這就跟我們的身份證一樣,所以非常重要。
- 在/不在位我們上面聊過了,這個(gè)位就是判斷頁(yè)面和頁(yè)框有沒有進(jìn)行映射的一項(xiàng)。
- 保護(hù)位指出在這個(gè)頁(yè)面上允許什么樣的類型訪問,是讀還是寫,一般讀是 1,寫是 0 ,這是一位的形式,不過還有另外一種形式,是三位,分別對(duì)應(yīng)讀、寫、執(zhí)行。
- 修改位 用于判斷這個(gè)頁(yè)面是否被修改過,在對(duì)頁(yè)面進(jìn)行寫入時(shí)會(huì)自動(dòng)設(shè)置修改位,如果一個(gè)頁(yè)面已經(jīng)被修改過,那么必須將它寫回磁盤,我們可以認(rèn)為這個(gè)頁(yè)面是一個(gè)臟頁(yè)。
- 無論讀寫,都會(huì)設(shè)置訪問位,訪問位的意義用來讓操作系統(tǒng)淘汰頁(yè)面所用,沒有訪問過的頁(yè)面要比多次訪問的頁(yè)面更容易被淘汰,訪問位在頁(yè)面置換算法中非常有用。
- 緩存位用于判斷是否禁用高速緩存,有的時(shí)候 CPU 需要讀取最新的用戶輸入,而不是從高速緩存中讀取已有的數(shù)據(jù)。
聊完頁(yè)表之后,我們來回顧一下頁(yè)面到頁(yè)框的映射過程(上面有寫,這里不再闡述了)

思考過后,你會(huì)發(fā)現(xiàn),頁(yè)面到頁(yè)框的映射過程比較繁瑣,又是檢索頁(yè)面、又是操作系統(tǒng)切換、又是內(nèi)存和磁盤的交互,想必這部分的性能容易出現(xiàn)問題,所以提升這部分的性能就成為了優(yōu)先級(jí)比較高的一個(gè)課題。
我們知道,這個(gè)映射過程主要是在 MMU 中完成的,所以能不能加快虛擬地址到物理地址的映射速度呢?,而且很多操作系統(tǒng)的虛擬地址空間往往很大,所以需要的頁(yè)表也會(huì)越來越大,那么如何處理日益劇增的頁(yè)表呢?
首先我們要聊一下的就是如何加快虛擬地址到物理地址的映射速度,加快映射速度有兩種方式,一種是使用硬件進(jìn)行加速,一種是使用軟件進(jìn)行加速。
經(jīng)過多年的研究表明,大多數(shù)程序會(huì)對(duì)少量的頁(yè)面進(jìn)行多次訪問,而不會(huì)對(duì)大量的頁(yè)面進(jìn)行多次訪問或者訪問次數(shù)大差不差,因此,只有極少數(shù)的頁(yè)表會(huì)被頻繁訪問,而大多數(shù)頁(yè)面卻照顧不到。由于這種局部性原理,使用硬件的方式是設(shè)置一個(gè)轉(zhuǎn)換檢測(cè)緩沖區(qū)(TLB),它能夠直接將虛擬地址映射成為物理地址,而不必再訪問頁(yè)表。
TLB 又叫做快表或者相聯(lián)存儲(chǔ)器。
TLB 可以放在 CPU 和 CPU 緩存(CPU cache)之間,用于緩存虛擬地址,TLB 可以放在 CPU 和 內(nèi)存之間,用于緩存物理地址,但是一般緩存虛擬地址比較常見,由此可見,TLB 相當(dāng)于是又多加了一個(gè)緩存層。
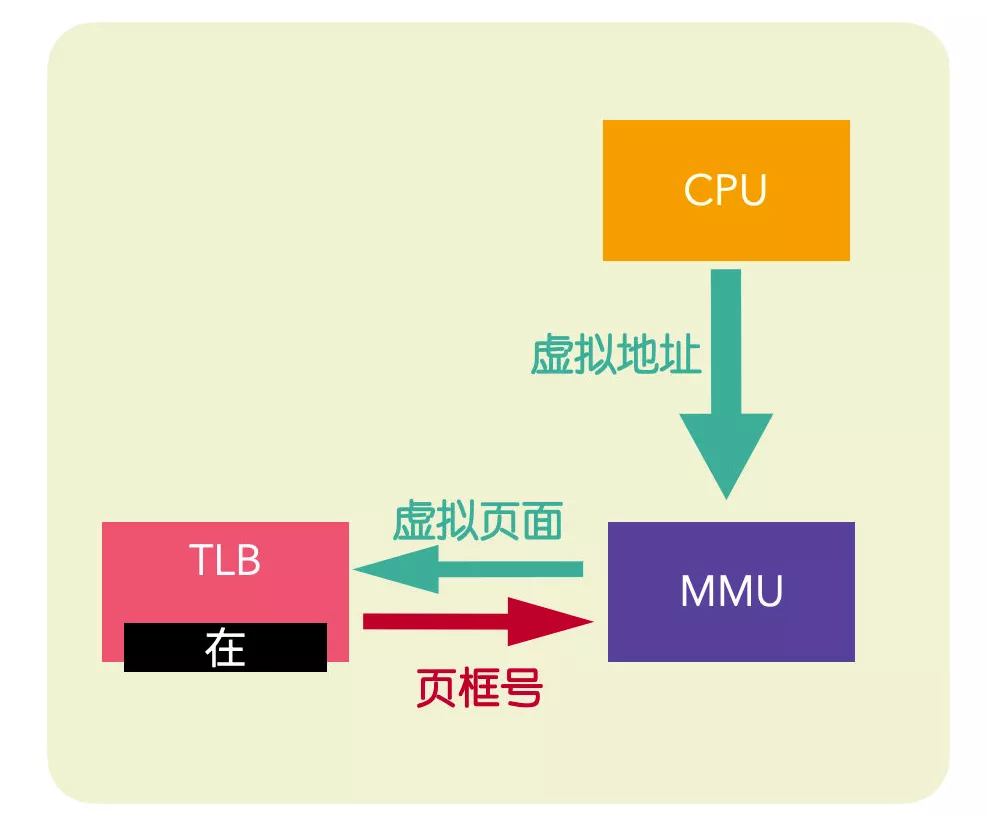
虛擬頁(yè)面在 TLB 中
當(dāng)一個(gè)數(shù)據(jù)的虛擬地址交由 MMU 進(jìn)行轉(zhuǎn)換時(shí),MMU 首先會(huì)將這個(gè)虛擬地址和 TLB 中緩存的虛擬地址進(jìn)行匹配,判斷虛擬地址所在的頁(yè)面是否被緩存,如果已經(jīng)緩存,就會(huì)訪問 TLB(這里有個(gè)前提就是判斷訪問位)將虛擬頁(yè)面對(duì)應(yīng)的頁(yè)框號(hào)取出,而不必再訪問頁(yè)表。
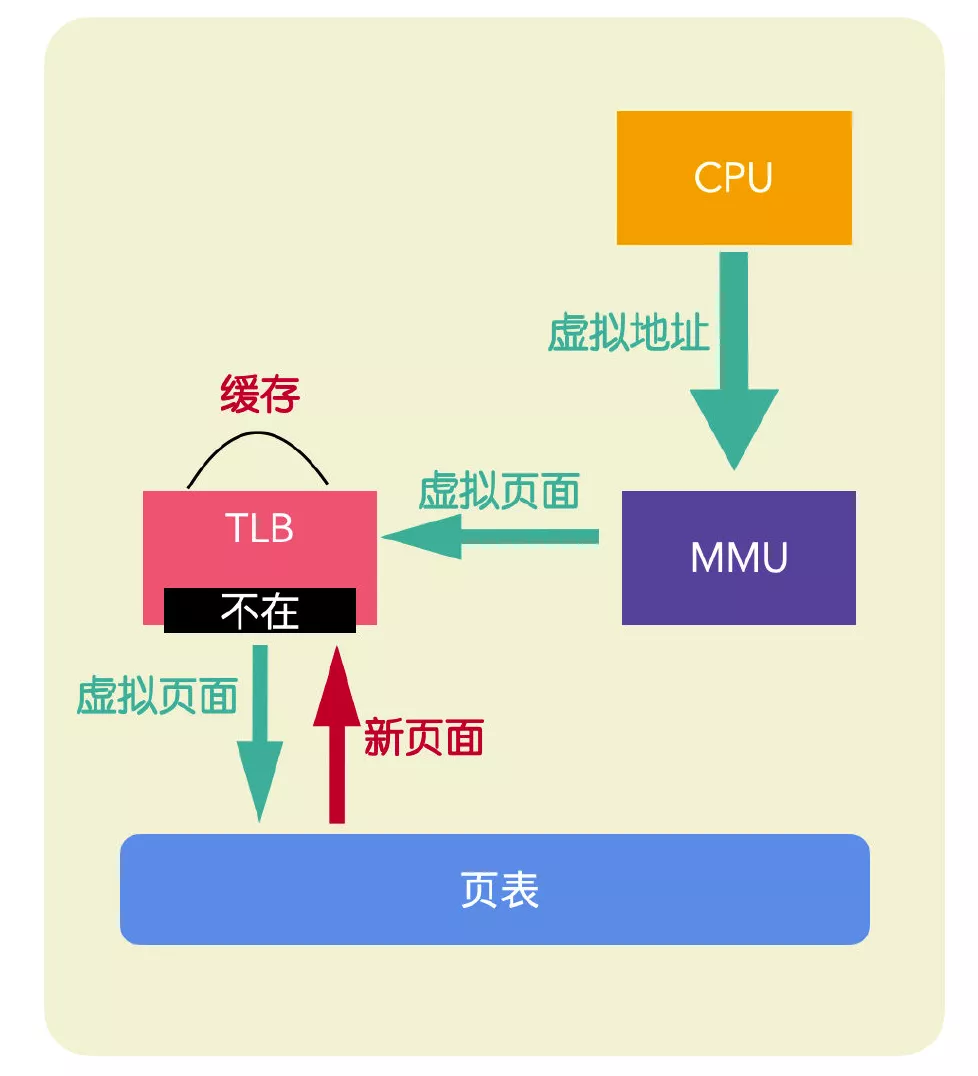
虛擬頁(yè)面不在 TLB 中
如果 MMU 沒有檢測(cè)到虛擬地址所在的頁(yè)面,就說明沒有查詢到匹配項(xiàng),就會(huì)走頁(yè)表訪問,通過頁(yè)表查詢到物理地址后,會(huì)從 TLB 中淘汰一個(gè)頁(yè)面,用新找到的頁(yè)面進(jìn)行替換。
雖然內(nèi)置一個(gè)硬件 TLB 能夠加快虛擬地址到物理地址的映射速度,不過現(xiàn)代 os 大多數(shù)都是使用軟件 TLB 來實(shí)現(xiàn)這個(gè)加速過程的,使用軟件 TLB 就意味著不再使用硬件,轉(zhuǎn)而擁抱操作系統(tǒng)。
這也就是說,當(dāng)發(fā)生 TLB 失效時(shí),不再是通過 MMU 到頁(yè)表中查詢,而是生成一個(gè) TLB 失效并交給操作系統(tǒng)來解決。失效會(huì)有兩種發(fā)生的可能性:當(dāng)要訪問的頁(yè)面在內(nèi)存中時(shí),這種失效叫做軟失效,軟失效比較好處理,找到該頁(yè)面然后直接更新 TLB 中對(duì)應(yīng)的項(xiàng)即可。當(dāng)要訪問的頁(yè)面不再內(nèi)存中時(shí),這種失效叫做硬失效,硬失效涉及磁盤訪問,頁(yè)面調(diào)入,硬失效的處理時(shí)間往往是軟失效的幾百萬倍。
上述都是理想情況下的失效,但實(shí)際情況下會(huì)存在既不是軟失效也不是硬失效的情況。當(dāng)程序訪問一個(gè)非法地址時(shí),根本不需要向 TLB 更新映射,此時(shí) os 會(huì)直接報(bào)告段錯(cuò)誤來終止程序,這種缺頁(yè)屬于程序錯(cuò)誤;而軟失效通常稱為次要缺頁(yè)錯(cuò)誤,硬失效稱為嚴(yán)重缺頁(yè)錯(cuò)誤。
解決完第一個(gè)問題之后,我們?cè)賮砜吹诙€(gè)問題,即如何處理日益劇增的頁(yè)表呢?
一般有兩種處理方式,使用多級(jí)頁(yè)表和倒排頁(yè)表。
第一種方案是使用多級(jí)頁(yè)表,下面是一個(gè)例子
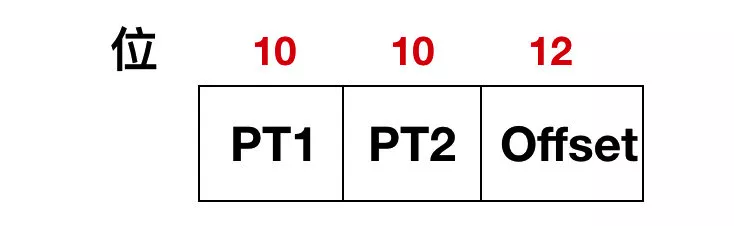
32 位的虛擬地址被劃分為 10 位的 PT1 域,10 位的 PT2 域,還有 12 位的 Offset 域。因?yàn)槠屏渴?12 位,所以頁(yè)面大小是 4 KB,共有 2^20 次方個(gè)頁(yè)面。
引入多級(jí)頁(yè)表的原因是避免把全部頁(yè)表一直保存在內(nèi)存中。不需要的頁(yè)表就不應(yīng)該保留。
多級(jí)頁(yè)表是一種分頁(yè)方案,它由兩個(gè)或多個(gè)層次的分頁(yè)表組成,也稱為分層分頁(yè)。級(jí)別1(level 1)頁(yè)面表的條目是指向級(jí)別 2(level 2) 頁(yè)面表的指針,級(jí)別2頁(yè)面表的條目是指向級(jí)別 3(level 3) 頁(yè)面表的指針,依此類推。最后一級(jí)頁(yè)表存儲(chǔ)的是實(shí)際的信息。
下面是一個(gè)二級(jí)頁(yè)表的工作過程
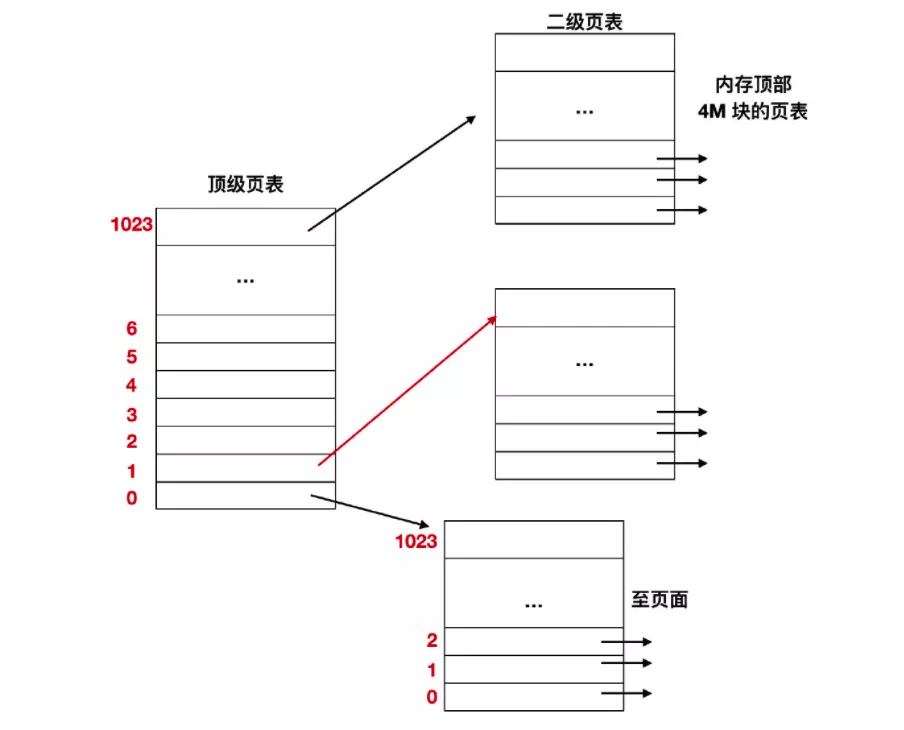
在最左邊是頂級(jí)頁(yè)表,它有 1024 個(gè)表項(xiàng),對(duì)應(yīng)于 10 位的 PT1 域。當(dāng)一個(gè)虛擬地址被送到 MMU 時(shí),MMU 首先提取 PT1 域并把該值作為訪問頂級(jí)頁(yè)表的索引。因?yàn)檎麄€(gè) 4 GB (即 32 位)虛擬地址已經(jīng)按 4 KB 大小分塊,所以頂級(jí)頁(yè)表中的 1024 個(gè)表項(xiàng)的每一個(gè)都表示 4M 的塊地址范圍。
由索引頂級(jí)頁(yè)表得到的表項(xiàng)中含有二級(jí)頁(yè)表的地址或頁(yè)框號(hào)。頂級(jí)頁(yè)表的表項(xiàng) 0 指向程序正文的頁(yè)表,表項(xiàng) 1 指向含有數(shù)據(jù)的頁(yè)表,表項(xiàng) 1023 指向堆棧的頁(yè)表,其他的項(xiàng)(用陰影表示)表示沒有使用。現(xiàn)在把 PT2 域作為訪問選定的二級(jí)頁(yè)表的索引,以便找到虛擬頁(yè)面的對(duì)應(yīng)頁(yè)框號(hào)。
針對(duì)分頁(yè)層級(jí)結(jié)構(gòu)中不斷增加的替代方法是使用倒排頁(yè)表(inverted page tables)。采用這種解決方案的有 PowerPC、UltraSPARC 和 Itanium。在這種設(shè)計(jì)中,實(shí)際內(nèi)存中的每個(gè)頁(yè)框?qū)?yīng)一個(gè)表項(xiàng),而不是每個(gè)虛擬頁(yè)面對(duì)應(yīng)一個(gè)表項(xiàng)。
雖然倒排頁(yè)表節(jié)省了大量的空間,但是它也有自己的缺陷:那就是從虛擬地址到物理地址的轉(zhuǎn)換會(huì)變得很困難。當(dāng)進(jìn)程 n 訪問虛擬頁(yè)面 p 時(shí),硬件不能再通過把 p 當(dāng)作指向頁(yè)表的一個(gè)索引來查找物理頁(yè)。而是必須搜索整個(gè)倒排表來查找某個(gè)表項(xiàng)。另外,搜索必須對(duì)每一個(gè)內(nèi)存訪問操作都執(zhí)行一次,而不是在發(fā)生缺頁(yè)中斷時(shí)執(zhí)行。
解決這一問題的方式是使用 TLB。當(dāng)發(fā)生 TLB 失效時(shí),需要用軟件搜索整個(gè)倒排頁(yè)表。一個(gè)可行的方式是建立一個(gè)散列表,用虛擬地址來散列。當(dāng)前所有內(nèi)存中的具有相同散列值的虛擬頁(yè)面被鏈接在一起。如下圖所示
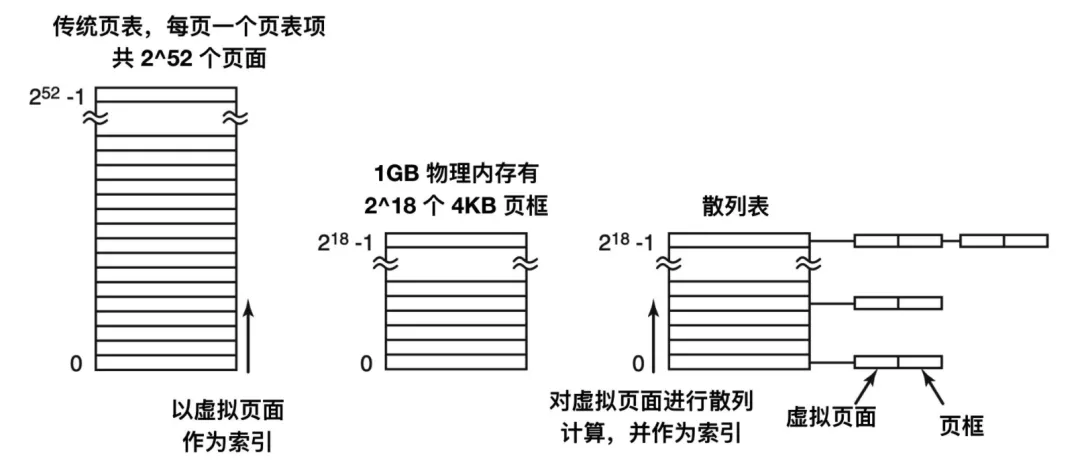
如果散列表中的槽數(shù)與機(jī)器中物理頁(yè)面數(shù)一樣多,那么散列表的沖突鏈的長(zhǎng)度將會(huì)是 1 個(gè)表項(xiàng)的長(zhǎng)度,這將會(huì)大大提高映射速度。一旦頁(yè)框被找到,新的(虛擬頁(yè)號(hào),物理頁(yè)框號(hào))就會(huì)被裝載到 TLB 中。
總結(jié)
這篇文章我從 MMU 這個(gè)知識(shí)點(diǎn)進(jìn)行切入,來為你展開了操作系統(tǒng)中的虛擬地址的概念,操作系統(tǒng)是如何處理日益增加的地址空間的,以及內(nèi)存管理面臨的挑戰(zhàn),如何優(yōu)化等。





















