













聊聊服務治理中的路由設計
本文轉載自微信公眾號「Kirito的技術分享」,作者kiritomoe。轉載本文請聯系Kirito的技術分享公眾號。
前言
路由(Route)的設計廣泛存在于眾多領域,以 RPC 框架 Dubbo 為例,就有標簽路由、腳本路由、權重路由、同機房路由等實現。
在框架設計層面,路由層往往位于負載均衡層之前,在進行選址時,路由完成的是 N 選 M(M <= N),而負載均衡完成的是 M 選一,共同影響選址邏輯,最后觸發調用。
在業務層面,路由往往是為了實現一定的業務語義,對流量進行調度,所以服務治理框架通常提供的都是基礎的路由擴展能力,使用者根據業務場景進行擴展。

路由過程
今天這篇文章將會圍繞路由層該如何設計展開。
路由的抽象建模
先參考 Dubbo 2.7 的實現,進行第一個版本的路由設計,該版本也最直觀,非常容易理解。
- public interface Router {
- List<Invoker> route(List<Invoker> invokers, Invocation invocation);
- }
- Invoker:服務提供方地址的抽象
- Invocation:調用的抽象
上述的 route 方法實現的便是 N 選 M 的邏輯。
接下來,以業務上比較常見的同機房路由為例繼續建模。顧名思義,在部署時,提供者采用多機房部署,起到容災的效果,同機房路由最簡單的版本即過濾篩選出跟調用方同一機房的地址。
偽代碼實現如下:
- List<Invoker> route(List<Invoker> invokers, Invocation invocation) {
- String site = invocation.getSite();
- List<Invoker> result = new ArrayList<>();
- for (Invoker invoker: invokers) {
- if (invoker.getSite().equals(site)) {
- result.add(invoker);
- }
- }
- return result;
- }
Dubbo 在較新的 2.7 版本中,也是采用了這樣的實現方式。這種實現的弊端也是非常明顯的:**每一次調用,都需要對全量的地址進行一次循環遍歷!注意,這是調用級別!**在超大規模的集群下,開銷之大,可想而知。
路由的改進方案
基于之前路由的抽象建模,可以直觀地理解路由選址的過程,其實也就是 2 步:
- 根據流量特性與路由規則特性選出對應的路由標。
- 根據路由標過濾對應的服務端地址列表
縱觀整個調用過程:
第一步:一定是動態的,Invocation 可能來自于不同的機房,自然會攜帶不同的機房標。
第二步:根據路由標過濾對應的服務地址列表,完全是可以優化的,因為服務端的地址列表基本是固定的(在不發生上下線時),可以提前計算好每個機房的地址列表,這樣就完成了算法復雜度從 O(N) 到 O(1) 的優化。
基于這個優化思路繼續完善,路由選址的過程不應該發生在調用級別,而應該發生在下面兩個場景:
- 地址列表變化時。需要重新計算路由地址列表。
- 路由規則發生變化時。例如路由規則不再是靜態的,可以接受動態配置的推送,此時路由地址列表也需要重新計算。
但無論是哪個場景,相比調用級別的計算量,都是九牛一毛的存在。
優化過后的路由方案,偽代碼如下:
- Map<String, List<Invoker>> invokerMap = new ArrayList<>();
- String originRule;
- List<Invoker> originInvokers;
- void generateRoute(List<Invoker> invokers, String rule) {
- // 不同路由有不同的路由地址列表計算方式
- invokerMap = calculate(invokers, rule);
- }
- // 地址推送
- void addressNotify(List<Invoker> invokers) {
- originInvokers = invokers;
- generateRoute(originInvokers, originRule);
- }
- // 規則變化
- void ruleChange(String rule) {
- originRule = rule;
- generateRoute(originInvokers, originRule);
- }
- List<Invoker> route(Invocation invocation) {
- String site = invocation.getSite();
- return invokerMap.get(site);
- }
這份偽代碼僅供參考,如果需要實現,仍然需要考慮非常多的細節,例如:
- 下一級路由如何觸發構建
- 如何確保路由的可觀測性
優化過后的方案,路由過程如下:
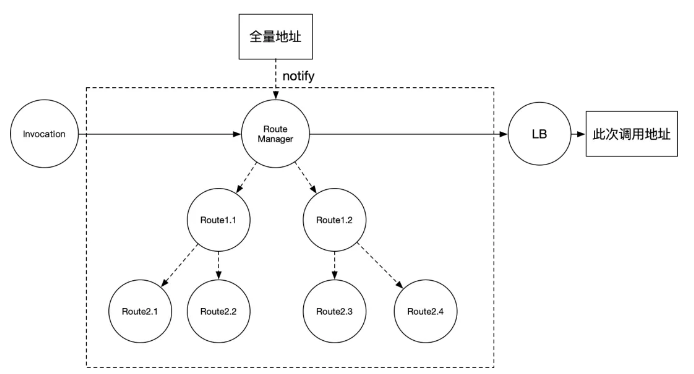
路由樹選址
對比之前,主要是兩個變化:
- 路由的代碼組織結構從 pipeline 的鏈式結構,變成樹型結構
- 建樹的過程發生在地址 notify 和規則推送時,在 invocation 級別無需計算
靜態路由和動態路由
上述的新方案,并不是特別新奇的概念,正是我們熟知的”打表“。這里也要進行說明,并不是所有的路由場景都可以提前打表,如果某一個路由的實現中,服務地址列表的切分依賴了調用時的信息,自然需要將 N 選 M 的過程延遲到調用時。但根據我個人的經驗,大多數的路由實現,基本都是標的匹配過程,無非是路由標的類型,計算標的邏輯不一樣而已。
對于這類可以提前打表的路由實現,我們不妨稱之為靜態路由;而必須在調用級別計算的路由實現,可以稱之為動態路由。
上述的優化方案,適用于靜態路由場景,并且在真實業務場景中,幾乎 90% 的路由實現都是靜態路由。
總結
本文以 Dubbo2.7 為例,在其基礎上提出了一種靜態路由策略的優化方案,可以大大減少路由過程中的計算量。這里也給大家賣個關子,Dubbo 3.0 有沒有對這塊進行優化呢,采取的是不是本文的靜態路由方案呢,背后會不會有其他的思考呢?嘿嘿,本文先不給結論,有知道的小伙伴可以留言告訴大家哦。




























