













自監督深度估計算法,比肩有監督,泛化性能更佳
室內環境的自監督深度估計向來比室外環境更具挑戰性,OPPO提出了一種新穎的單目自監督深度估計模型:MonoIndoor,通過深度因子化模塊和殘差姿態估計模塊,提高了室內環境中自監督單目深度估計的性能。目前,該成果已被ICCV 2021接收。ICCV是計算機視覺方向的三大頂級會議之一,今年論文接收率為25.9%。
根據單張圖像估計深度信息是計算機視覺領域的經典問題,也是一項具有挑戰的難題。由于單目圖像的尺度不確定,傳統方法無法計算深度值。
隨著深度學習技術的發展,該范式已經成為了估計單目圖像的深度信息的一種解決方案。早期的深度估計方法大多是有監督的,即要求數據集包含單目圖像和對應的深度真值支撐網絡模型訓練。
要想讓圖像含深度真值非常困難,一般需要精密的深度測量設備和移動平臺“捕獲”。因此,高昂的成本導致數據集的數據量較小,也意味著有監督學習的深度估計方式不適用于大規模的工業場景。
近日,OPPO提出了一種新穎的單目自監督深度估計模型:MonoIndoor。該方法能夠在訓練深度網絡時僅使用圖像本身作為監督信息, 無需圖像顯式的目標深度值,在降低對訓練數據集要求的同時, 提升了深度估計的適應性和魯棒性。目前,該成果已被ICCV 2021接收,相關技術已申請專利。

論文地址:https://arxiv.org/pdf/2107.12429.pdf
具體而言,該論文研究了更具挑戰性、場景更復雜的室內場景自監督深度估計,在三個公開數據集:EuRoC、NYUv2、7-Scenes上進行測試時,其性能優于Monodepth2等方法,達到了自監督深度估計領域內的最佳性能。
如何實現室內場景深度估計?
雖然對于自監督深度估計已經有了不少研究,其性能已經可以與有監督方法相媲美,但是這些自監督方法的性能評估要么只在戶外進行,要么在室內表現不佳。
對于原因,OPPO研究院的研究員認為:同戶外場景相比,室內場景通常缺少顯著的局部或全局視覺特征。具體而言:
1. 室內場景景深變化劇烈,使得神經網絡很難推演出一致的深度線索。
2. 室內場景下,相機運動通常會包含大量的旋轉,從而給相機姿態網絡造成困難。
基于以上觀察,研究員提出兩個新的模塊嘗試解決上述兩個困難。其中,深度因子化模塊(Depth Factorization)旨在克服景深劇烈變化給深度估計造成的困難;殘差姿態估計模塊(Residual Pose Estimation)能夠提高室內場景下相機旋轉的估計,進而提升深度質量。
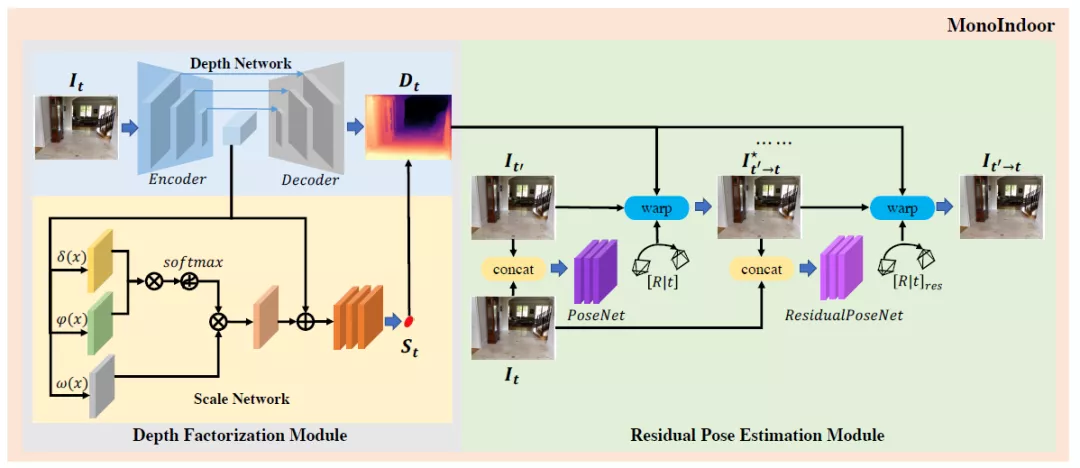
圖注:MonoIndoor模型架構一覽
模型工作原理如上圖所示,深度因子化模塊采用編解碼器的深度網絡來估計相對深度圖,使用非局部標度網絡(non-local scale network)估計全局標度因子(global scale factor);殘差姿態估計模塊用姿態網絡估計一對幀的初始攝像機姿勢,然后根據初始姿勢,用殘差姿態網絡迭代估計殘差相機姿勢。
模型架構之深度因子化模塊
深度因子化模塊的骨干模型是Monodepth2,它的自動掩碼機制可以忽略那些在單目訓練中相對攝像機靜止的像素;同時采用多尺度光度一致性損失,以輸入分辨率執行所有圖像采樣,減少了深度失真。
在Monodepth2的基礎上,研究員提出了自注意指導的標度回歸網絡(self-attention-guided scale regression network)對當前視點的全局尺度因子進行估計。
標度網絡作為深度因子化模塊的另一個分支,其以彩色圖像為輸入,全局標度因子為輸出。由于全局標度因子和圖像局部區域密切相關,研究員在網絡中加入了自注意塊,以期指導網絡更多地“關注”某信息豐富的區域,從而推導出深度因子。公式如下,給定圖像特征輸入,輸出為Query、鍵(key)、值(values)。
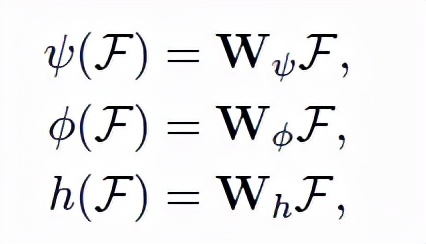
此外,為了穩定估計全局標度因子,研究員還在網絡中添加了概率標度回歸頭(Probabilistic Scale Regression Head)。公式如下,全局標度是每一標度的加權概率求和:
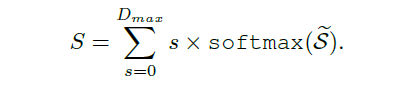
模型架構之殘差姿態估計模塊
與已有方法在數據預處理過程中專注于“去除”或“減少”旋轉成分(rotational components)不同,OPPO研究員提出的殘差姿態估計模塊,可以用迭代的方式學習目標和源圖像之間的相對相機姿態。
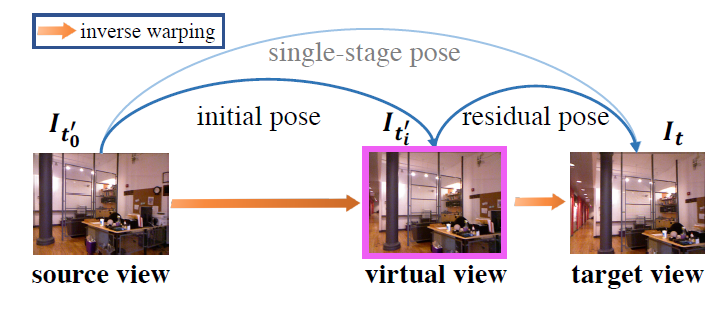
圖注:一次姿態估計分解為兩次姿態估計的示例
第一步:姿態網絡將目標圖像和源圖像作為輸入,并估計初始相機姿態。
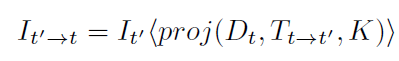
第二步:用上述公式從源圖像進行雙線性采樣,重建一個虛擬視圖。
第三步:利用殘差姿態網絡,將目標圖像和合成視圖作為輸入,并輸出殘差相機姿態(residual camera pose)。其中,殘差相機姿態指的是合成視圖和目標圖像之間的相機姿態。
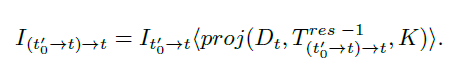
第四步,從合成圖像進行雙線性采樣,公式如上↑。
最后,獲得新合成視圖之后,繼續估計下一個的殘差姿態。此時,雙線性采樣公式的一般化為↓:
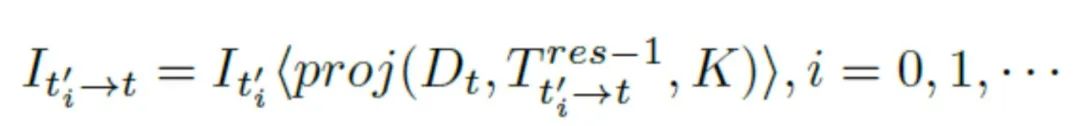
多次估計之后,殘差姿態可以動態的寫為↓:
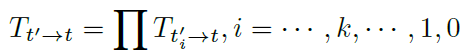
綜上,通過迭代法估計殘差姿態,能夠獲得更準確的相機姿態,更好的進行深度估計。具體實驗效果如下一部分所述。
性能評估
為了說明模型MonoIndoor的效果,研究員在EuRoC MAV、NYUv2、RGBD 7-Scenes三個權威數據集上進行了評估。采用業界通用的單目深度估計量化指標:絕對相對差(AbsRel)、均方根誤差(RMSE);以及三個常用的閾值thr=1.25,1.25^2,1.25^3下的準確度。
具體到實驗配置,研究員使用PyTorch實現模型,每個實驗用Adam優化器訓練40個epochs,在前20個epochs學習率設置為10^-4,另外20個設置為10^-5;平滑項和consistency term分別設置為0.001和0.05。
實驗結果之EuRoC MAV

將Monodepth2作為基線模型進行對比,結果如上表所示,深度因子化模塊能夠AbsRel從15.7%降低到14.9%;殘差姿態估計模塊將AbsRel降低到14.1%,整個模型在所有評估指標中都實現了最佳性能。

通過上圖,我們可以定性的發現,MonoIndoor 做出的深度估計比Monoepth2要好得多。例如,在第一行中,MonoIndoor可以估計圖片右下角的“洞區域”的精確深度,而Monoepth2顯然無法估計。
實驗結果之NYUv2
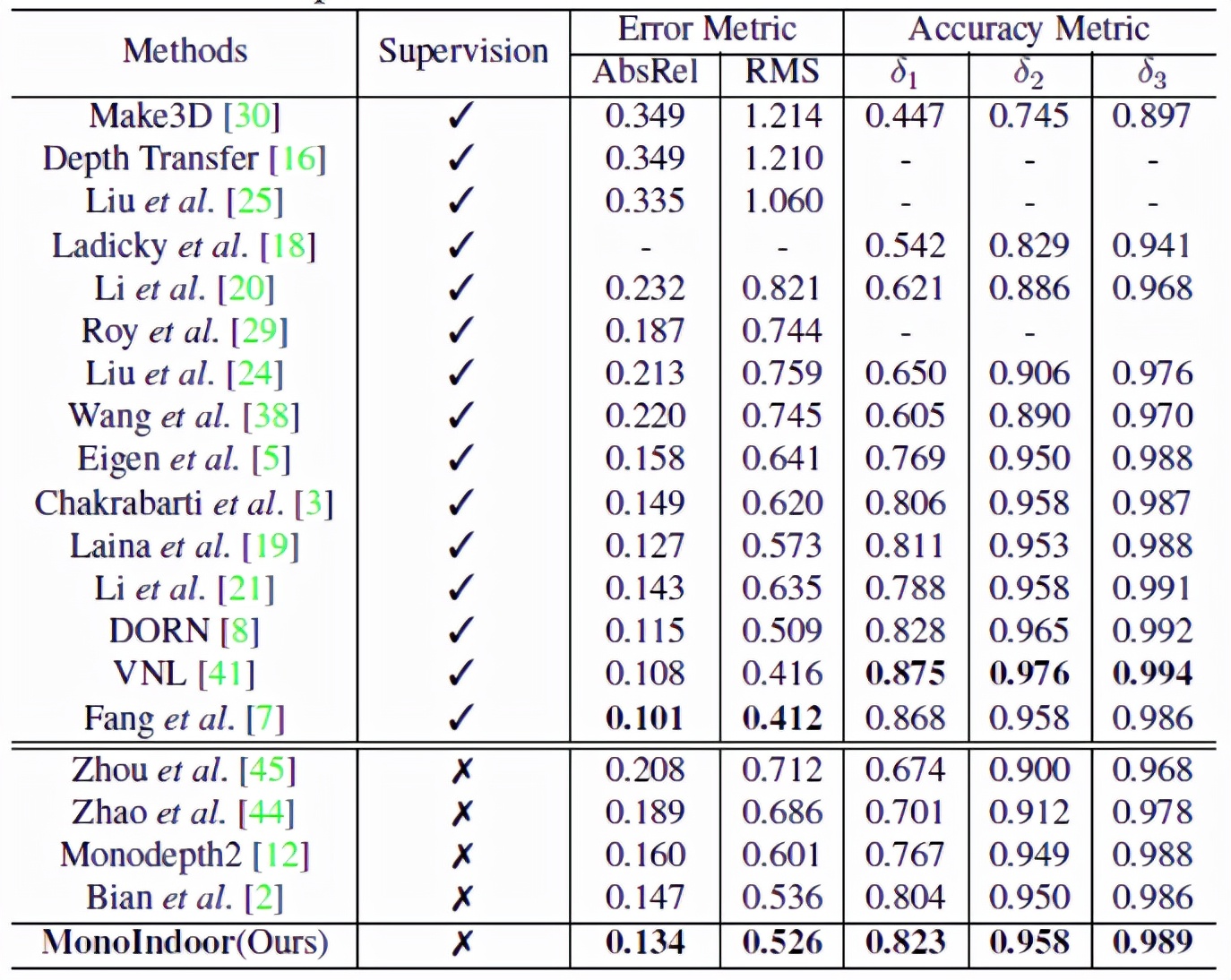
MonoIndoor 與最新的SOTA監督和自監督方法性能對比結果如上表所示,在自監督方面,能夠在各項指標上達到最佳,在與有監督方法對比方面,也能夠“打敗”一組,從而縮小了自監督和有監督方法之間的差距。

上圖可視化了NYUv2上的深度估計效果。與Monoepth2的結果相比,MonoIndoor的深度估計更加接近真實情況。例如,第一行的第三列,MonoIndoor對椅子區域的深度估計更加精準。
實驗結果之RGB-D 7-Scenes
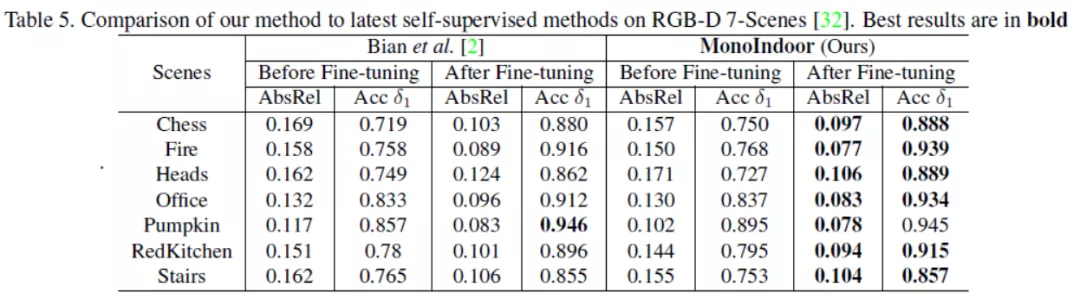
上表給出了MonoIndoor微調前與微調后在RGB-D 7-Scenes數據集上的測試結果,通過在各個場景給出的各個指標,顯示了MonoIndoor更好的泛化能力和魯棒性。例如,在場景“Fire”上,MonoIndoor減少了1.2%的AbsRel;在場景“Heads”上,MonoIndoor減少了1.8%的AbsRel。
結語
近年來,人工智能產品在各個行業迅猛發展,機器人學、三維重建、目標追蹤等領域對深度估計技術的準確性和效率要求越來越高。然而目前主流的深度估計方法常由于外界環境或是成本原因,很難在工程上得以應用并達到相關需求。
另一方面,目前關于圖像深度估計研究很多,可用的公共數據集卻相對較少,且公共數據集中的場景相對不夠豐富,大大限制了深度估計算法的泛化能力。
OPPO通過自研無監督算法,設計了適合室內場景的模型,能夠在不依賴數據標注的情況下,顯著提升神經網絡在室內場景下的深度估計效果。這一方面體現了OPPO對人工智能應用場景的理解,也說明了它對人工智能前沿學術問題的獨特把握。

























