AI就是機器學習?3000字給你講清楚,機器學習到底是怎么一回事
計算機科學家們在人工智能的技術核心--機器學習(Machine Learning)和深度學習(Deep Learning)領域上已經取得重大的突破,機器被賦予強大的認知和預測能力。回顧歷史,在1997年,IBM深藍戰勝國際象棋冠軍卡斯帕羅夫;在2011年,具備機器學習能力的IBM Waston參加綜藝節目贏得100萬美金;在2016年,利用深度學習訓練的Aplphago成功擊敗人類世界冠軍。種種事件表明機器也可以像人類一樣思考,甚至比人類做得更好。
目前,人工智能在金融、醫療、制造等行業得到了廣泛應用。其中,機器學習是人工智能技術發展的主要方向。
一、機器學習與人工智能、深度學習的關系
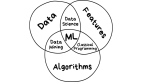
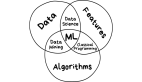
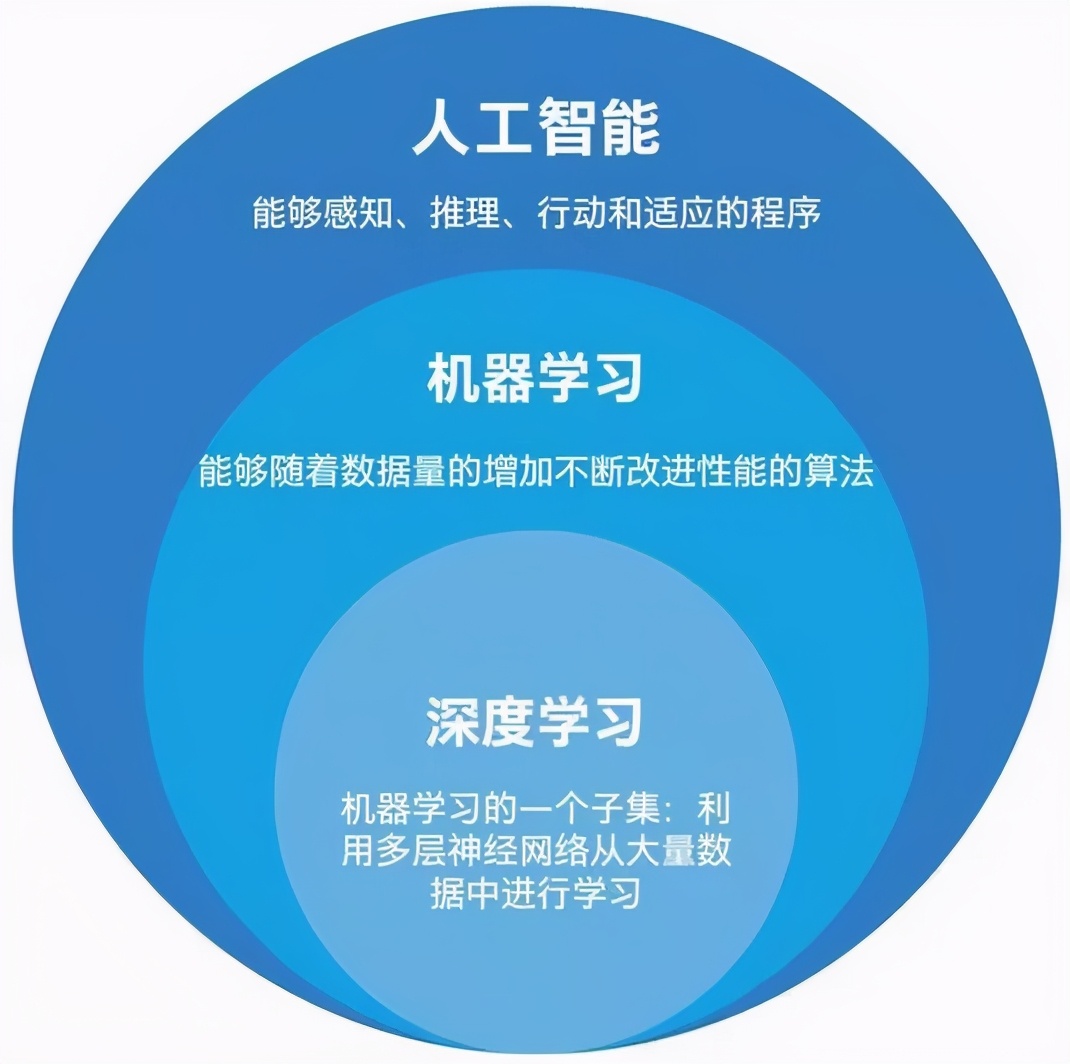
在介紹機器學習之前,先需要對人工智能、機器學習和深度學習三者之間的關系進行梳理。目前業界最常見的劃分是:
- 人工智能:是使用與傳統計算機系統完全不同的工作模式,它可以依據通用的學習策略,讀取海量的大數據,并從中發現規律、聯系和洞見,因此人工智能能夠根據新數據自動調整,而無需重設程序。
- 機器學習:是人工智能研究的核心技術,在大數據的支撐下,通過各種算法讓機器對數據進行深層次的統計分析以進行自學;利用機器學習,人工智能系統獲得了歸納推理和決策能力;而深度學習更將這一能力推向了更高的層次。
- 深度學習是機器學習算法的一種,隸屬于人工神經網絡體系,現在很多應用領域中性能最佳的機器學習都是基于模仿人類大腦結構的神經網絡設計而來的,這些計算機系統能夠完全自主地學習、發現并應用規則。相比較其他方法,在解決更復雜的問題上表現更優異,深度學習是可以幫助機器實現獨立思考的一種方式。
總而言之,人工智能是社會發展的重要推動力,而機器學習,尤其是深度學習技術就是人工智能發展的核心,它們三者之間是包含與被包含的關系。如下圖:
二、機器學習:實現人工智能的高效方法
從廣義上來說,機器學習是一種能夠賦予機器學習的能力,以此讓它完成直接編程無法完成的功能的方法。但從實踐的意義上來說,機器學習是通過經驗或數據來改進算法的研究,通過算法讓機器從大量歷史數據中學習規律,得到某種模式并利用此模型預測未來,機器在學習的過程中,處理的數據越多,預測結果就越精準。
機器學習在人工智能的研究中具有十分重要的地位。它是人工智能的核心,是使計算機具有智能的根本途徑,其應用遍及人工智能的各個領域。從20世紀50年代人們就開始了對機器學習的研究,從最初的基于神經元模型以及函數逼近論的方法研究,到以符號演算為基礎的規則學習和決策樹學習的產生,以及之后的認知心理學中歸納、解釋、類比等概念的引入,至最新的計算學習理論和統計學習的興起,機器學習一直都在相關學科的實踐應用中起著主導作用。現在已取得了不少成就,并分化出許多研究方向,主要有符號學習、連接學習和統計學習等。
01 機器學習的結構模型
機器學習的本質就是算法,算法是用于解決問題的一系列指令。程序員開發的用于指導計算機進行新任務的算法是我們今天看到的先進數字世界的基礎。計算機算法根據某些指令和規則,將大量數據組織到信息和服務中。機器學習向計算機發出指令,允許計算機從數據中學習,而不需要程序員做出新的分步指令。
機器學習的基本過程是給學習算法提供訓練數據。然后,學習算法基于數據的推論生成一組新的規則。這本質上就是生成一種新的算法,稱之為機器學習模型。通過使用不同的訓練數據,相同的學習算法可以生成不同的模型。從數據中推理出新的指令是機器學習的核心優勢。它還突出了數據的關鍵作用:用于訓練算法的可用數據越多,算法學習到的就越多。事實上,AI 許多最新進展并不是由于學習算法的激進創新,而是現在積累了大量的可用數據。
02 機器學習的工作流程
- Step1選擇數據
首先將原始數據分成三組:訓練數據、驗證數據和測試數據;
- Step2數據建模
再使用訓練數據來構建使用相關特征的模型;
- Step3驗證模型
使用驗證數據輸入到已經構建的數據模型中;
- Step4測試模型
使用測試數據檢查被驗證的模型的性能表現;
- Step5使用模型
使用完全訓練好的模型在新數據上做預測;
- Step6選擇數據
使用更多數據、不同的特征或調整過的參數來提升算法的性能表現。
03 機器學習發展的關鍵基石
- 海量數據
人工智能的能量來源是穩定的數據流。機器學習只有通過海量數據來訓練自己,才能開發新規則來完成日益復雜的任務。目前我們時刻都在產生大量的數據,而數據存儲成本的降低,使得這些數據易于被使用。
- 超強計算
強大的計算機和通過互聯網連接遠程處理能力使可以處理海量數據的機器學習技術成為可能。ALPHGO之所以能在與對李世石的對決中取得歷史性的勝利,這與它硬件配置的1920個CPU和280個GPU超強運算系統密不可分,可見計算能力對于機器學習是至關重要的。
- 優秀算法
在機器學習中,學習算法(learning algorithms)創建了規則,允許計算機從數據中學習,從而推論出新的指令(算法模型),這也是機器學習的核心優勢。新的機器學習技術,特別是分層神經網絡,也被稱為深度學習,啟發了新的服務,刺激了對人工智能這一領域其他方面的投資和研究。
04 機器學習的算法分類
機器學習基于學習形式的不同通常可分為三類:
- 監督學習(Supervised Learning)
給學習算法提供標記的數據和所需的輸出,對于每一個輸入,學習者都被提供了一個回應的目標。監督學習主要被應用于快速高效地教熟AI現有的知識,被用于解決分類和回歸的問題。常見的算法有決策樹(Decision Trees)、Adaboost算法、人工神經網絡(ArTIficial Neural Network-ANN)算法、SVM(Support Vector Machine)算法等。
- 無監督學習(Unsupervised Learning)
給學習算法提供的數據是未標記的,并且要求算法識別輸入數據中的模式,主要是建立一個模型,用其試著對輸入的數據進行解釋,并用于下次輸入。現實情況下往往很多數據集都有大量的未標記樣本,有標記的樣本反而比較少。如果直接棄用,很大程度上會導致模型精度低。這種情況解決的思路往往是結合有標記的樣本,通過估計的方法把未標記樣本變為偽的有標記樣本,所以無監督學習比監督學習更難掌握。主要用于解決聚類和降維問題,常見的算法有聚類算法、K-means算法、Expectation Maximisation(EM)算法、Affinity Propagation聚類算法、層次聚類算法等。
- 強化學習(Reinforcement Learning)
該算法與動態環境相互作用,把環境的反饋作為輸入,通過學習選擇能達到其目標的最優動作。強化學習這一方法背后的數學原理與監督/非監督學習略有差異。監督/非監督學習更多地應用了統計學,而強化學習更多地結合了離散數學、隨機過程這些數學方法。常見的算法有TD(λ)算法、Q-learning算法等。
三、機器學習在BI的應用:自然語言分析
隨著機器學習的普及,對話型用戶交互接口逐漸成為業界的熱門話題。Natural Language to SQL( NL2SQL)就是這樣的一項技術,它將用戶的自然語句轉為可以執行的SQL語句,從而免除業務用戶學習SQL語言的煩惱,成功將自然語言應用于BI領域。
Smartbi的自然語言分析就是利用了NL2SQL技術,將自然語言通過神經網絡轉化為計算機可以識別的數據庫查詢語言。用戶通過語音或者鍵盤輸入后,“AI智能小麥”會將輸入的自然語言轉為語言元模型的形式,通過小麥內置的知識抽取算法,經過深度學習模型將元模型轉化為機器可以理解的數據庫語言。最后通過Smartbi預置的查詢引擎和圖形引擎,快速準確地找到用戶想要的查詢結果,自動生成圖形輸出,也可以在Smartbi中對查詢結果進行組合和進一步分析。
四、機器學習在BI的應用:數據挖掘
數據挖掘利用機器學習技術從大量數據中挖掘出有價值的信息。對比傳統的數據分析,數據挖掘揭示數據之間未知的關系,可以做一些預測性的分析,例如精準營銷、銷量預測、流失客戶預警等等。
雖然數據挖掘學習門檻較高,但是有越來越多的軟件工具支持機器學習模型的自動構建,這些模型可以嘗試許多不同的算法來找出最成功的算法。一旦通過訓練數據找到了能夠進行預測的最佳模型,就可以部署它,并對新的數據進行預測。例如Smartbi的數據挖掘平臺在一個界面上通過可視化的操作實現數據預處理、算法應用、模型訓練、評估、部署等全生命周期的管理。同時,內置分類、聚類、關聯、回歸五大類數十個算法節點并支持自動推薦,參數也能實現自動調優。

機器學習是人工智能應用的又一重要研究領域。當今,盡管在機器學習領域已經取得重大技術進展,但就目前機器學習發展現狀而言,自主學習能力還十分有限,還不具備類似人那樣的學習能力,同時機器學習的發展也面臨著巨大的挑戰,諸如泛化能力、速度、可理解性以及數據利用能力等技術性難關必須克服。但令人可喜的是,在某些復雜的類人神經分析算法的開發領域,計算機專家已經取得了很大進展,人們已經可以開發出許多自主性的算法和模型讓機器展現出高效的學習能力。對機器學習的進一步深入研究,勢必推動人工智能技術的深化應用與發展。