













機(jī)器翻譯:谷歌翻譯是如何對(duì)幾乎所有語言進(jìn)行翻譯的?
谷歌翻譯大家想必都不陌生,但你有沒有想過,它究竟是如何將幾乎所有的已知語言翻譯成我們所選擇的語言?本文將解開這個(gè)謎團(tuán),并且向各位展示如何用長短期記憶網(wǎng)絡(luò)(LSTM)構(gòu)建語言翻譯程序。
本文分為兩部分。第一部分簡單介紹神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯(NMT)和編碼器-解碼器(Encoder-Decoder)結(jié)構(gòu)。第二部分提供了使用Python創(chuàng)建語言翻譯程序的詳細(xì)步驟。
什么是機(jī)器翻譯?
機(jī)器翻譯是計(jì)算語言學(xué)的一個(gè)分支,主要研究如何將一種語言的源文本自動(dòng)轉(zhuǎn)換為另一種語言的文本。在機(jī)器翻譯領(lǐng)域,輸入已經(jīng)由某種語言的一系列符號(hào)組成,而計(jì)算機(jī)必須將其轉(zhuǎn)換為另一種語言的一系列符號(hào)。
神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯是針對(duì)機(jī)器翻譯領(lǐng)域所提出的主張。它使用人工神經(jīng)網(wǎng)絡(luò)來預(yù)測某個(gè)單詞序列的概率,通常在單個(gè)集成模型中對(duì)整個(gè)句子進(jìn)行建模。
憑借神經(jīng)網(wǎng)絡(luò)的強(qiáng)大功能,神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯已經(jīng)成為翻譯領(lǐng)域最強(qiáng)大的算法。這種最先進(jìn)的算法是深度學(xué)習(xí)的一項(xiàng)應(yīng)用,其中大量已翻譯句子的數(shù)據(jù)集用于訓(xùn)練能夠在任意語言對(duì)之間的翻譯模型。

谷歌語言翻譯程序
理解Seq2Seq架構(gòu)
顧名思義,Seq2Seq將單詞序列(一個(gè)或多個(gè)句子)作為輸入,并生成單詞的輸出序列。這是通過遞歸神經(jīng)網(wǎng)絡(luò)(RNN)實(shí)現(xiàn)的。具體來說,就是讓兩個(gè)將與某個(gè)特殊令牌一起運(yùn)行的遞歸神經(jīng)網(wǎng)絡(luò)嘗試根據(jù)前一個(gè)序列來預(yù)測后一個(gè)狀態(tài)序列。
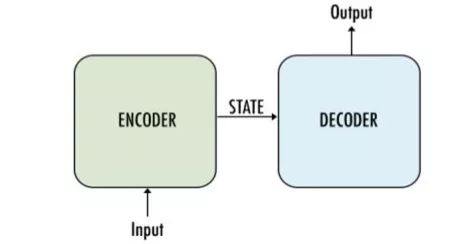
一種簡單的編碼器-解碼器架構(gòu)
它主要由編碼器和解碼器兩部分構(gòu)成,因此有時(shí)候被稱為編碼器-解碼器網(wǎng)絡(luò)。
· 編碼器:使用多個(gè)深度神經(jīng)網(wǎng)絡(luò)層,將輸入單詞轉(zhuǎn)換為相應(yīng)的隱藏向量。每個(gè)向量代表當(dāng)前單詞及其語境。
· 解碼器:與編碼器類似。它將編碼器生成的隱藏向量、自身的隱藏狀態(tài)和當(dāng)前單詞作為輸入,從而生成下一個(gè)隱藏向量,最終預(yù)測下一個(gè)單詞。
任何神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯的最終目標(biāo)都是接收以某種語言輸入的句子,然后將該句子翻譯為另一種語言作為輸出結(jié)果。下圖是一個(gè)漢譯英翻譯算法的簡單展示:
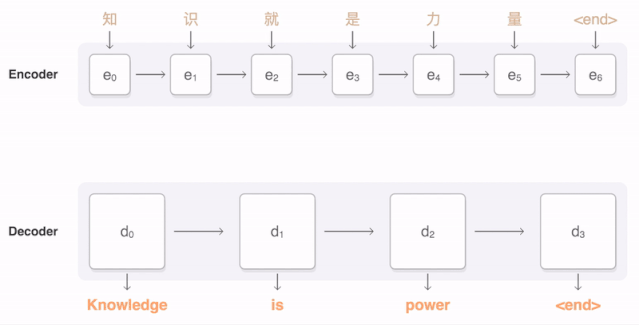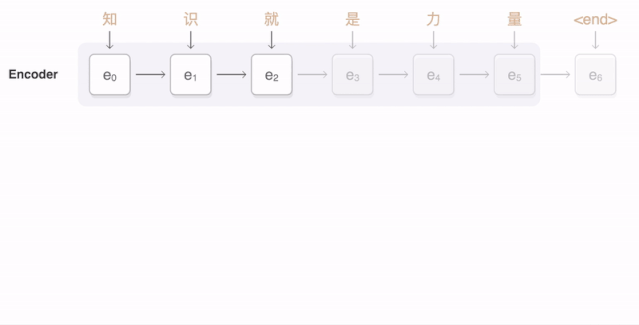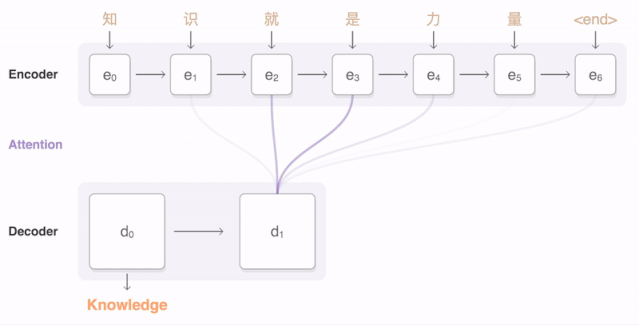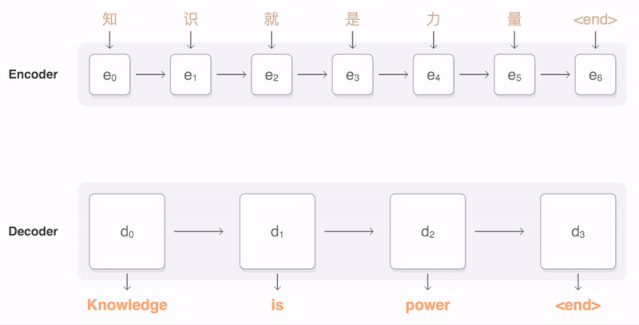
將“Knowledge ispower”翻譯成漢語。
它如何運(yùn)行?
第一步,通過某種方式將文本數(shù)據(jù)轉(zhuǎn)換為數(shù)字形式。為了在機(jī)器翻譯中實(shí)現(xiàn)這一點(diǎn),需要將每個(gè)單詞轉(zhuǎn)換為可輸入到模型中的獨(dú)熱編碼(One Hot Encoding)向量。獨(dú)熱編碼向量是在每個(gè)索引處都為0(僅在與該特定單詞相對(duì)應(yīng)的單個(gè)索引處為1)的向量。
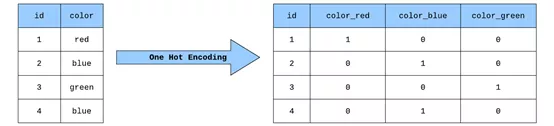
獨(dú)熱編碼
為輸入語言中的每個(gè)唯一單詞設(shè)置索引來創(chuàng)建這些向量,輸出語言也是如此。為每個(gè)唯一單詞分配唯一索引時(shí),也就創(chuàng)建了針對(duì)每種語言的所謂的“詞匯表”。理想情況下,每種語言的詞匯表將僅包含該語言的每個(gè)唯一單詞。
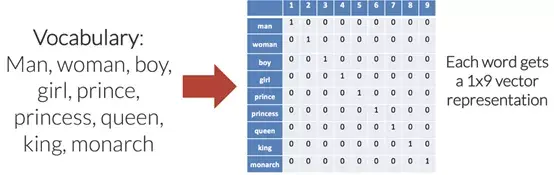
如上圖所示,每個(gè)單詞都變成了一個(gè)長度為9(這是詞匯表的大小)的向量,索引中除去一個(gè)1以外,其余全部都是0。
通過為輸入和輸出語言創(chuàng)建詞匯表,人們可以將該技術(shù)應(yīng)用于任何語言中的任何句子,從而將語料庫中所有已翻譯的句子徹底轉(zhuǎn)換為適用于機(jī)器翻譯任務(wù)的格式。
現(xiàn)在來一起感受一下編碼器-解碼器算法背后的魔力。在最基本的層次上,模型的編碼器部分選擇輸入語言中的某個(gè)句子,并從該句中創(chuàng)建一個(gè)語義向量(thought vector)。該語義向量存儲(chǔ)句子的含義,然后將其傳遞給解碼器,解碼器將句子譯為輸出語言。

編碼器-解碼器結(jié)構(gòu)將英文句子“Iam astudent”譯為德語
就編碼器來說,輸入句子的每個(gè)單詞會(huì)以多個(gè)連續(xù)的時(shí)間步分別輸入模型。在每個(gè)時(shí)間步(t)中,模型都會(huì)使用該時(shí)間步輸入到模型單詞中的信息來更新隱藏向量(h)。
該隱藏向量用來存儲(chǔ)輸入句子的信息。這樣,因?yàn)樵跁r(shí)間步t=0時(shí)尚未有任何單詞輸入編碼器,所以編碼器在該時(shí)間步的隱藏狀態(tài)從空向量開始。下圖以藍(lán)色框表示隱藏狀態(tài),其中下標(biāo)t=0表示時(shí)間步,上標(biāo)E表示它是編碼器(Encoder)的隱藏狀態(tài)[D則用來表示解碼器(Decoder)的隱藏狀態(tài)]。
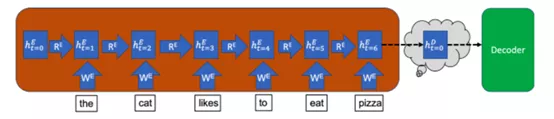
在每個(gè)時(shí)間步中,該隱藏向量都會(huì)從該時(shí)間步的輸入單詞中獲取信息,同時(shí)保留從先前時(shí)間步中存儲(chǔ)的信息。因此,在最后一個(gè)時(shí)間步中,整個(gè)輸入句子的含義都會(huì)儲(chǔ)存在隱藏向量中。最后一個(gè)時(shí)間步中的隱藏向量就是上文中提到的語義向量,它之后會(huì)被輸入解碼器。
另外,請(qǐng)注意編碼器中的最終隱藏向量如何成為語義向量并在t=0時(shí)用上標(biāo)D重新標(biāo)記。這是因?yàn)榫幋a器的最終隱藏向量變成了解碼器的初始隱藏向量。通過這種方式,句子的編碼含義就傳遞給了解碼器,從而將其翻譯成輸出語言。但是,與編碼器不同,解碼器需要輸出長度可變的譯文。因此,解碼器將在每個(gè)時(shí)間步中輸出一個(gè)預(yù)測詞,直到輸出一個(gè)完整的句子。
開始翻譯之前,需要輸入<SOS>標(biāo)簽作為解碼器第一個(gè)時(shí)間步的輸入。與編碼器一樣,解碼器將在時(shí)間步t=1處使用<SOS>輸入來更新其隱藏狀態(tài)。但是,解碼器不僅會(huì)繼續(xù)進(jìn)行到下一個(gè)時(shí)間步,它還將使用附加權(quán)重矩陣為輸出詞匯表中的所有單詞創(chuàng)建概率。這樣,輸出詞匯表中概率最高的單詞將成為預(yù)測輸出句子中的第一個(gè)單詞。
解碼器必須輸出長度可變的預(yù)測語句,它將以該方式繼續(xù)預(yù)測單詞,直到其預(yù)測語句中的下一個(gè)單詞為<EOS>標(biāo)簽。一旦該標(biāo)簽預(yù)測完成,解碼過程就結(jié)束了,呈現(xiàn)出的是輸入句子的完整預(yù)測翻譯。
通過Keras和Python實(shí)現(xiàn)神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯
了解了編碼器-解碼器架構(gòu)之后,創(chuàng)建一個(gè)模型,該模型將通過Keras和python把英語句子翻譯成法語。第一步,導(dǎo)入需要的庫,為將在代碼中使用的不同參數(shù)配置值。
- #Import Libraries
- import os, sys
- from keras.models importModel
- from keras.layers importInput, LSTM, GRU, Dense, Embedding
- fromkeras.preprocessing.text importTokenizer fromkeras.preprocessing.sequence import pad_sequences
- from keras.utils import to_categorical
- import numpy as np
- import pandas as pd
- import pickle
- importmatplotlib.pyplot as plt
- #Values fordifferent parameters: BATCH_SIZE=64
- EPOCHS=20
- LSTM_NODES=256
- NUM_SENTENCES=20000
- MAX_SENTENCE_LENGTH=50
- MAX_NUM_WORDS=20000
- EMBEDDING_SIZE=200
數(shù)據(jù)集
我們需要一個(gè)包含英語句子及其法語譯文的數(shù)據(jù)集,下載fra-eng.zip文件并將其解壓。每一行的文本文件都包含一個(gè)英語句子及其法語譯文,通過制表符分隔。繼續(xù)將每一行分為輸入文本和目標(biāo)文本。
- input_sentences = []
- output_sentences = [] output_sentences_inputs = [] count =0
- for line inopen('./drive/MyDrive/fra.txt', encoding="utf-8"):
- count +=1
- if count >NUM_SENTENCES:
- break
- if'\t'notin line:
- continue
- input_sentence = line.rstrip().split('\t')[0]
- output = line.rstrip().split('\t')[1]
- output_sentence = output +' <eos>'
- output_sentence_input ='<sos> '+ output
- input_sentences.append(input_sentence)
- output_sentences.append(output_sentence)
- output_sentences_inputs.append(output_sentence_input)
- print("Number ofsample input:", len(input_sentences))
- print("Number ofsample output:", len(output_sentences))
- print("Number ofsample output input:", len(output_sentences_inputs))
- Output:
- Number of sample input: 20000
- Number of sample output: 20000
- Number of sample output input: 20000
在上面的腳本中創(chuàng)建input_sentences[]、output_sentences[]和output_sentences_inputs[]這三個(gè)列表。接下來,在for循環(huán)中,逐個(gè)讀取每行fra.txt文件。每一行都在制表符出現(xiàn)的位置被分為兩個(gè)子字符串。左邊的子字符串(英語句子)插入到input_sentences[]列表中。制表符右邊的子字符串是相應(yīng)的法語譯文。
此處表示句子結(jié)束的<eos>標(biāo)記被添加到已翻譯句子的前面。同理,表示“句子開始”的<sos>標(biāo)記和已翻譯句子的開頭相連接。還是從列表中隨機(jī)打印一個(gè)句子:
- print("English sentence: ",input_sentences[180])
- print("French translation: ",output_sentences[180])
- Output:English sentence: Join us.French translation: Joignez-vous à nous.<eos>
標(biāo)記和填充
下一步是標(biāo)記原句和譯文,并填充長度大于或小于某一特定長度的句子。對(duì)于輸入而言,該長度將是輸入句子的最大長度。對(duì)于輸出而言,它也是輸出句子的最大長度。在此之前,先設(shè)想一下句子的長度。將分別在兩個(gè)單獨(dú)的英語和法語列表中獲取所有句子的長度。
- eng_len = []
- fren_len = [] # populate thelists with sentence lengths for i ininput_sentences:
- eng_len.append(len(i.split()))
- for i inoutput_sentences:
- fren_len.append(len(i.split()))
- length_df = pd.DataFrame({'english':eng_len, 'french':fren_len})
- length_df.hist(bins =20)
- plt.show()
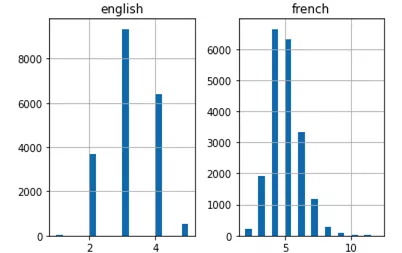
上面的直方圖顯示,法語句子的最大長度為12,英語句子的最大長度為6。
接下來,用Keras的Tokenizer()類矢量化文本數(shù)據(jù)。句子將因此變?yōu)檎麛?shù)序列。然后,用零填充這些序列,使它們長度相等。
標(biāo)記器類的word_index屬性返回一個(gè)單詞索引詞典,其中鍵表示單詞,值表示對(duì)應(yīng)的整數(shù)。最后,上述腳本打印出詞典中唯一單詞的數(shù)量和輸入的最長英文句子的長度。
- #tokenize the input sentences(inputlanguage)
- input_tokenizer =Tokenizer(num_words=MAX_NUM_WORDS) input_tokenizer.fit_on_texts(input_sentences) input_integer_seq = input_tokenizer.texts_to_sequences(input_sentences) print(input_integer_seq)
- word2idx_inputs =input_tokenizer.word_index print('Total uniquewords in the input: %s'%len(word2idx_inputs))
- max_input_len =max(len(sen) for sen in input_integer_seq)
- print("Length oflongest sentence in input: %g"% max_input_len)
- Output:
- Total unique words in the input: 3501
- Length of longest sentence in input: 6
同樣,輸出語句也可以用相同的方式標(biāo)記:
- #tokenize theoutput sentences(Output language)
- output_tokenizer =Tokenizer(num_words=MAX_NUM_WORDS, filters='')
- output_tokenizer.fit_on_texts(output_sentences+output_sentences_inputs) output_integer_seq =output_tokenizer.texts_to_sequences(output_sentences) output_input_integer_seq =output_tokenizer.texts_to_sequences(output_sentences_inputs) print(output_input_integer_seq)
- word2idx_outputs=output_tokenizer.word_index print('Total uniquewords in the output: %s'%len(word2idx_outputs))
- num_words_output=len(word2idx_outputs)+1
- max_out_len =max(len(sen) for sen inoutput_integer_seq)
- print("Length oflongest sentence in the output: %g"% max_out_len)
- Output:
- Total unique words in the output: 9511
- Length of longest sentence in the output: 12
現(xiàn)在,可以通過上面的直方圖來驗(yàn)證兩種語言中最長句子的長度。還可以得出這樣的結(jié)論:英語句子通常較短,平均單詞量比法語譯文句子的單詞量要少。
接下來需要填充輸入。填充輸入和輸出的原因是文本的句子長度不固定,但長短期記憶網(wǎng)絡(luò)希望輸入的例句長度都相等。因此需要將句子轉(zhuǎn)換為長度固定的向量。為此,一種可行的方法就是填充。
- #Padding theencoder input
- encoder_input_sequences =pad_sequences(input_integer_seq,maxlen=max_input_len) print("encoder_input_sequences.shape:",encoder_input_sequences.shape)
- #Padding thedecoder inputs decoder_input_sequences =pad_sequences(output_input_integer_seq,maxlen=max_out_len, padding='post')
- print("decoder_input_sequences.shape:",decoder_input_sequences.shape)
- #Padding thedecoder outputs decoder_output_sequences =pad_sequences(output_integer_seq,maxlen=max_out_len, padding='post')
- print("decoder_output_sequences.shape:",decoder_output_sequences.shape)
- encoder_input_sequences.shape: (20000, 6)
- decoder_input_sequences.shape: (20000, 12)
- decoder_output_sequences.shape: (20000, 12)
輸入中有20000個(gè)句子(英語),每個(gè)輸入句子的長度都為6,所以現(xiàn)在輸入的形式為(20000,6)。同理,輸出中有20000個(gè)句子(法語),每個(gè)輸出句子的長度都為12,所以現(xiàn)在輸出的形式為(20000,12),被翻譯的語言也是如此。
大家可能還記得,索引180處的原句為join us。標(biāo)記生成器將該句拆分為join和us兩個(gè)單詞,將它們轉(zhuǎn)換為整數(shù),然后通過對(duì)輸入列表中索引180處的句子所對(duì)應(yīng)的整數(shù)序列的開頭添加四個(gè)零來實(shí)現(xiàn)前填充(pre-padding)。
- print("encoder_input_sequences[180]:",encoder_input_sequences[180])Output:
- encoder_input_sequences[180]: [ 0 0 0 0 464 59]
要驗(yàn)證join和us的整數(shù)值是否分別為464和59,可將單詞傳遞給word2index_inputs詞典,如下圖所示:
- prnt(word2idx_inputs["join"])
- print(word2idx_inputs["us"])Output:
- 464
- 59
更值得一提的是,解碼器則會(huì)采取后填充(post-padding)的方法,即在句子末尾添加零。而在編碼器中,零被填充在開頭位置。該方法背后的原因是編碼器輸出基于出現(xiàn)在句末的單詞,因此原始單詞被保留在句末,零則被填充在開頭位置。而解碼器是從開頭處理句子,因此對(duì)解碼器的輸入和輸出執(zhí)行后填充。
詞嵌入向量(Word Embeddings)
圖源:unsplash
我們要先將單詞轉(zhuǎn)換為對(duì)應(yīng)的數(shù)字向量表示,再將向量輸入給深度學(xué)習(xí)模型。我們也已經(jīng)將單詞轉(zhuǎn)化成了數(shù)字。那么整數(shù)/數(shù)字表示和詞嵌入向量之間有什么區(qū)別呢?
單個(gè)整數(shù)表示和詞嵌入向量之間有兩個(gè)主要區(qū)別。在整數(shù)表示中,一個(gè)單詞僅用單個(gè)整數(shù)表示。而在向量表示中,一個(gè)單詞可以用50、100、200或任何你喜歡的維數(shù)表示。因此詞嵌入向量可以獲取更多與單詞有關(guān)的信息。其次,單個(gè)整數(shù)表示無法獲取不同單詞之間的關(guān)系。而詞嵌入向量卻能做到這一點(diǎn)。
對(duì)于英語句子(即輸入),我們將使用GloVe詞嵌入模型。對(duì)于輸出的法語譯文,我們將使用自定義詞嵌入模型。點(diǎn)擊此處可下載GloVe詞嵌入模型。
首先,為輸入內(nèi)容創(chuàng)建詞嵌入向量。在此之前需要將GloVe詞向量加載到內(nèi)存中。然后創(chuàng)建一個(gè)詞典,其中單詞為鍵,其對(duì)應(yīng)的向量為值:
- from numpy import array
- from numpy import asarray
- from numpy import zeros
- embeddings_dictionary=dict() glove_file =open(r'./drive/My Drive/glove.twitter.27B.200d.txt', encoding="utf8")
- for line in glove_file:
- rec = line.split() word= rec[0]
- vector_dimensions =asarray(rec[1:], dtype='float32')
- embeddings_dictionary[word] = vector_dimensions glove_file.close()
回想一下,輸入中包含3501個(gè)唯一單詞。我們將創(chuàng)建一個(gè)矩陣,其中行數(shù)代表單詞的整數(shù)值,而列數(shù)將對(duì)應(yīng)單詞的維數(shù)。該矩陣將包含輸入句子中單詞的詞嵌入向量。
- num_words =min(MAX_NUM_WORDS, len(word2idx_inputs)+1)
- embedding_matrix =zeros((num_words, EMBEDDING_SIZE)) for word, index inword2idx_inputs.items(): embedding_vector = embeddings_dictionary.get(word) if embedding_vector isnotNone: embedding_matrix[index] =embedding_vector
創(chuàng)建模型
第一步,為神經(jīng)網(wǎng)絡(luò)創(chuàng)建一個(gè)嵌入層。嵌入層被認(rèn)為是網(wǎng)絡(luò)的第一隱藏層。它必須指定3個(gè)參數(shù):
· input_dim:表示文本數(shù)據(jù)中詞匯表的容量。比如,如果數(shù)據(jù)被整數(shù)編碼為0-10之間的值,那么詞匯表的容量為11個(gè)單詞。
· output_dim:表示將嵌入單詞的向量空間大小。它決定該層每個(gè)單詞的輸出向量大小。比如,它可以是32或100,甚至還可以更大。如果大家對(duì)此有疑問,可以用不同的值測試。
· input_length:表示輸入序列的長度,正如大家為Keras模型的輸入層所定義的那樣。比如,如果所有的輸入文檔都由1000個(gè)單詞組成,那么該值也為1000。
- embedding_layer = Embedding(num_words, EMBEDDING_SIZE,weights=[embedding_matrix], input_length=max_input_len)
接下來需要做的是定義輸出,大家都知道輸出將是一個(gè)單詞序列。回想一下,輸出中唯一單詞的總數(shù)為9511。因此,輸出中的每個(gè)單詞都可以是這9511個(gè)單詞中的一個(gè)。輸出句子的長度為12。每個(gè)輸入句子都需要一個(gè)對(duì)應(yīng)的輸出句子。因此,輸出的最終形式將是:(輸入量、輸出句子的長度、輸出的單詞數(shù))
- #shape of the output
- decoder_targets_one_hot = np.zeros((len(input_sentences), max_out_len,num_words_output),
- dtype='float32'
- )decoder_targets_one_hot.shapeShape: (20000, 12, 9512)
為了進(jìn)行預(yù)測,該模型的最后一層將是一個(gè)稠密層(dense layer),因此需要以獨(dú)熱編碼向量的形式輸出,因?yàn)槲覀儗⒃诔砻軐邮褂胹oftmax激活函數(shù)。為創(chuàng)建獨(dú)熱編碼輸出,下一步是將1分配給與該單詞整數(shù)表示對(duì)應(yīng)的列數(shù)。
- for i, d in enumerate(decoder_output_sequences):
- for t, word in enumerate(d):
- decoder_targets_one_hot[i, t,word] = 1
下一步是定義編碼器和解碼器網(wǎng)絡(luò)。編碼器將輸入英語句子,并輸出長短期記憶網(wǎng)絡(luò)的隱藏狀態(tài)和單元狀態(tài)。
- encoder_inputs =Input(shape=(max_input_len,))
- x =embedding_layer(encoder_inputs) encoder =LSTM(LSTM_NODES, return_state=True)
- encoder_outputs,h, c =encoder(x) encoder_states = [h, c]
下一步是定義解碼器。解碼器將有兩個(gè)輸入:編碼器的隱藏狀態(tài)和單元狀態(tài),它們實(shí)際上是開頭添加了令牌后的輸出語句。
- decoder_inputs =Input(shape=(max_out_len,))
- decoder_embedding =Embedding(num_words_output,LSTM_NODES) decoder_inputs_x =decoder_embedding(decoder_inputs) decoder_lstm =LSTM(LSTM_NODES,return_sequences=True, return_state=True)
- decoder_outputs, _, _ =decoder_lstm(decoder_inputs_x,initial_state=encoder_states) #Finally, theoutput from the decoder LSTM is passed through a dense layer to predict decoderoutputs.
- decoder_dense =Dense(num_words_output,activation='softmax')
- decoder_outputs =decoder_dense(decoder_outputs)
訓(xùn)練模型
編譯定義了優(yōu)化器和交叉熵?fù)p失的模型。
- #Compile
- model =Model([encoder_inputs,decoder_inputs],decoder_outputs)
- model.compile(
- optimizer='rmsprop',
- loss='categorical_crossentropy',
- metrics=['accuracy']
- )
- model.summary()
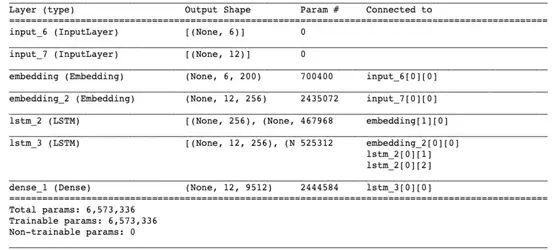
結(jié)果在意料之中。編碼器lstm_2接受來自嵌入層的輸入,而解碼器lstm_3使用編碼器的內(nèi)部狀態(tài)及嵌入層。該模型總共有大約650萬個(gè)參數(shù)!訓(xùn)練模型時(shí),筆者建議指定EarlyStopping()的參數(shù),以避免出現(xiàn)計(jì)算資源的浪費(fèi)和過擬合。
- es =EarlyStopping(monitor='val_loss', mode='min', verbose=1)
- history = model.fit([encoder_input_sequences,decoder_input_sequences], decoder_targets_one_hot, batch_size=BATCH_SIZE, epochs=20,
- callbacks=[es], validation_split=0.1,
- )
保存模型權(quán)重。
- model.save('seq2seq_eng-fra.h5')
繪制訓(xùn)練和測試數(shù)據(jù)的精度曲線。
- #Accuracy
- plt.title('model accuracy')
- plt.plot(history.history['accuracy'])
- plt.plot(history.history['val_accuracy'])
- plt.ylabel('accuracy')
- plt.xlabel('epoch')
- plt.legend(['train', 'test'], loc='upper left')
- plt.show()
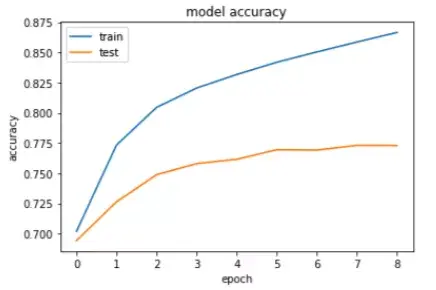
如大家所見,該模型達(dá)到了約87%的訓(xùn)練精度和約77%的測試精度,這表示該模型出現(xiàn)了過擬合。我們只用20000條記錄進(jìn)行了訓(xùn)練,所以大家可以添加更多記錄,還可以添加一個(gè)dropout層來減少過擬合。
測試機(jī)器翻譯模型
加載模型權(quán)重并測試模型。
- encoder_model = Model(encoder_inputs, encoder_states)
- model.compile(optimizer='rmsprop', loss='categorical_crossentropy')
- model.load_weights('seq2seq_eng-fra.h5')
設(shè)置好權(quán)重之后,是時(shí)候通過翻譯幾個(gè)句子來測試機(jī)器翻譯模型了。推理模式的工作原理與訓(xùn)練過程略有不同,其過程可分為以下4步:
· 編碼輸入序列,返回其內(nèi)部狀態(tài)。
· 僅使用start-of-sequence字符作為輸入,并使用編碼器內(nèi)部狀態(tài)作為解碼器的初始狀態(tài)來運(yùn)行解碼器。
· 將解碼器預(yù)測的字符(在查找令牌之后)添加到解碼序列中。
· 將先前預(yù)測的字符令牌作為輸入,重復(fù)該過程,更新內(nèi)部狀態(tài)。
由于只需要編碼器來編碼輸入序列,因此我們將編碼器和解碼器分成兩個(gè)獨(dú)立的模型。
- decoder_state_input_h =Input(shape=(LSTM_NODES,))
- decoder_state_input_c=Input(shape=(LSTM_NODES,)) decoder_states_inputs=[decoder_state_input_h, decoder_state_input_c] decoder_inputs_single=Input(shape=(1,))
- decoder_inputs_single_x=decoder_embedding(decoder_inputs_single) decoder_outputs,h, c =decoder_lstm(decoder_inputs_single_x, initial_state=decoder_states_inputs) decoder_states = [h, c] decoder_outputs =decoder_dense(decoder_outputs) decoder_model =Model( [decoder_inputs_single] +decoder_states_inputs, [decoder_outputs] + decoder_states
我們想讓輸出內(nèi)容為法語的單詞序列。因此需要將整數(shù)轉(zhuǎn)換回單詞。我們將為輸入和輸出創(chuàng)建新詞典,其中鍵為整數(shù),對(duì)應(yīng)的值為單詞。
- idx2word_input = {v:k for k, v inword2idx_inputs.items()}
- idx2word_target = {v:k for k, v inword2idx_outputs.items()}
該方法將接受帶有輸入填充序列的英語句子(整數(shù)形式),并返回法語譯文。
- deftranslate_sentence(input_seq):
- states_value = encoder_model.predict(input_seq) target_seq = np.zeros((1, 1))
- target_seq[0, 0] =word2idx_outputs['<sos>']
- eos = word2idx_outputs['<eos>']
- output_sentence = [] for _ inrange(max_out_len):
- output_tokens, h, c = decoder_model.predict([target_seq] + states_value) idx = np.argmax(output_tokens[0, 0, :])
- if eos == idx:
- break
- word =''
- if idx >0:
- word =idx2word_target[idx] output_sentence.append(word) target_seq[0, 0] = idx
- states_value = [h, c] return' '.join(output_sentence)
預(yù)測
為測試該模型性能,從input_sentences列表中隨機(jī)選取一個(gè)句子,檢索該句子的對(duì)應(yīng)填充序列,并將其傳遞給translate_sentence()方法。該方法將返回翻譯后的句子。
- i = np.random.choice(len(input_sentences))
- input_seq=encoder_input_sequences[i:i+1]
- translation=translate_sentence(input_seq) print('Input Language: ', input_sentences[i])
- print('Actualtranslation : ', output_sentences[i])
- print('Frenchtranslation : ', translation)
結(jié)果:

很成功!該神經(jīng)網(wǎng)絡(luò)翻譯模型成功地將這么多句子譯為了法語。大家也可以通過谷歌翻譯進(jìn)行驗(yàn)證。當(dāng)然,并非所有句子都能被正確翻譯。為進(jìn)一步提高準(zhǔn)確率,大家可以搜索“注意力”機(jī)制(Attention mechanism),將其嵌入編碼器-解碼器結(jié)構(gòu)。
圖源:unsplash
大家可以從manythings.org上面下載德語、印地語、西班牙語、俄語、意大利語等多種語言的數(shù)據(jù)集,并構(gòu)建用于語言翻譯的神經(jīng)網(wǎng)絡(luò)翻譯模型。
神經(jīng)機(jī)器翻譯(NMT)是自然語言處理領(lǐng)域中的一個(gè)相當(dāng)高級(jí)的應(yīng)用,涉及非常復(fù)雜的架構(gòu)。本文闡釋了結(jié)合長短期記憶層進(jìn)行Seq2Seq學(xué)習(xí)的編碼器-解碼器模型的功能。編碼器是一種長短期記憶,用于編碼輸入語句,而解碼器則用于解碼輸入內(nèi)容并生成對(duì)應(yīng)的輸出內(nèi)容。




















