AI在茫茫人海中,看到只有你被Deepfake了
本文經(jīng)AI新媒體量子位(公眾號(hào)ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請(qǐng)聯(lián)系出處。
自打有了deepfake,再也不敢相信「眼見(jiàn)為實(shí)」了。
要說(shuō)把朱茵換臉成楊冪,把海王換臉成徐錦江,大家還可以一笑而過(guò)。
△圖源:微博用戶@慢三與偏見(jiàn)
可若是公眾人物被deepfake了什么不該說(shuō)的話、不該做的事,就讓人細(xì)思極恐了。

為了防止世界被破壞,為了維護(hù)世界的和平,(狗頭)現(xiàn)在,阿里安全圖靈實(shí)驗(yàn)室也加入了“圍剿”deepfake的隊(duì)列:
打造deepfake檢測(cè)算法S-MIL,多人現(xiàn)場(chǎng)視頻,只要其中1人被換臉,就能精準(zhǔn)識(shí)別。
基于多實(shí)例學(xué)習(xí)的deepfake檢測(cè)方法
魔高一尺,道高一丈。deepfake和deepfake檢測(cè)技術(shù)的較量其實(shí)早已展開(kāi)。
不過(guò),此前存在的deepfake檢測(cè)方法主要分為兩類:幀級(jí)檢測(cè)和視頻級(jí)檢測(cè)。
基于幀級(jí)的方法需要高成本的幀級(jí)別標(biāo)注,在轉(zhuǎn)化到視頻級(jí)任務(wù)時(shí),也需要設(shè)計(jì)巧妙的融合方法才能較好地將幀級(jí)預(yù)測(cè)轉(zhuǎn)化為視頻級(jí)預(yù)測(cè)。簡(jiǎn)單的平均值或者取最大值極易導(dǎo)致漏檢或誤檢。
而基于視頻級(jí)別的檢測(cè)方法,比如LSTM等,在deepfake視頻檢測(cè)時(shí),過(guò)多專注于時(shí)序建模,導(dǎo)致deepfake視頻的檢測(cè)效果受到了一定的限制。

△部分deepfake攻擊,四個(gè)人中只有一人被換臉
為了解決這些問(wèn)題,阿里安全圖靈實(shí)驗(yàn)室的研究人員們提出了基于多實(shí)例學(xué)習(xí)的Sharp-MIL(S-MIL)方法,只需視頻級(jí)別的標(biāo)注,就能對(duì)deepfake作品進(jìn)行檢測(cè)。
核心思想是,只要視頻中有一張人臉被篡改,那么該視頻就被定義為deepfake視頻。這就和多實(shí)例學(xué)習(xí)的思想相吻合。
在多實(shí)例學(xué)習(xí)中,一個(gè)包由多個(gè)實(shí)例組成,只要其中有一個(gè)實(shí)例是正類,那么該包就是正類的,否則就是負(fù)類。
S-MIL就將人臉和輸入視頻分別當(dāng)作多實(shí)例學(xué)習(xí)里的實(shí)例和包進(jìn)行檢測(cè)。
并且,通過(guò)將多個(gè)實(shí)例的聚合由輸出層提前到特征層,一方面使得聚合更加靈活,另一方面也利用了偽造檢測(cè)的目標(biāo)函數(shù)直接指導(dǎo)實(shí)例級(jí)深度表征的學(xué)習(xí),來(lái)緩解傳統(tǒng)多實(shí)例學(xué)習(xí)面臨的梯度消失難題。
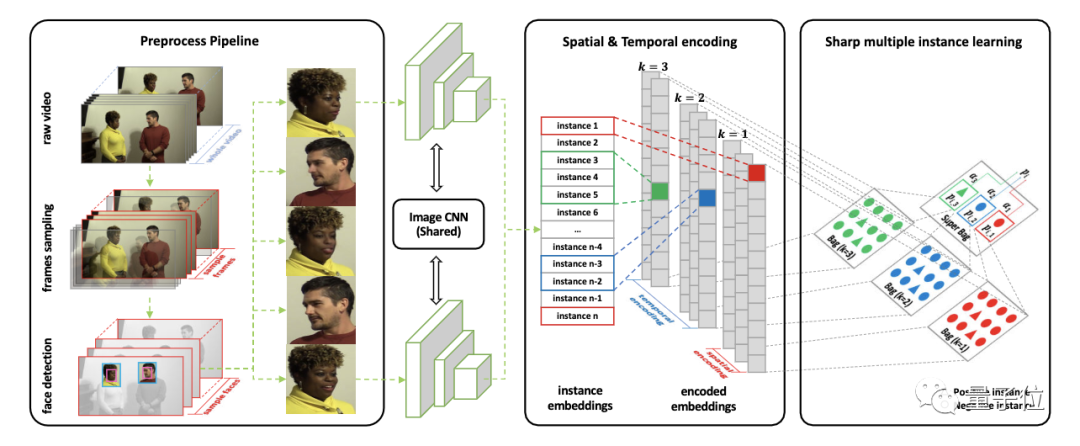
具體而言,算法主要由三個(gè)關(guān)鍵部分組成。
首先,對(duì)輸入視頻中的采樣幀進(jìn)行人臉檢測(cè),并將提取的人臉喂給CNN,以獲取特征作為實(shí)例。
在實(shí)例設(shè)計(jì)上,與傳統(tǒng)多實(shí)例學(xué)習(xí)的設(shè)定一樣,實(shí)例與實(shí)例間是相互獨(dú)立的。
但由于deepfake是單幀篡改的,導(dǎo)致同一人臉在相鄰幀上會(huì)有一些抖動(dòng),就像這樣:

為此,研究人員設(shè)計(jì)了時(shí)空實(shí)例,用來(lái)刻畫幀間一致性,用于輔助deepfake檢測(cè)。
具體而言,使用文本分類里常用的1-d卷積,使用不同大小的核對(duì)輸入的人臉序列從多視角上進(jìn)行編碼,以得到時(shí)空實(shí)例,用于最終檢測(cè)。
也就是說(shuō),第二步,是將編碼后的時(shí)空實(shí)例提取出來(lái),形成時(shí)間核大小不同的時(shí)空包。這些包被一起用來(lái)表示一段視頻。
最后,對(duì)這些包進(jìn)行S-MIL,算出所有包的fake分?jǐn)?shù),這樣,就能得到整個(gè)視頻的最終fake分?jǐn)?shù),從而判斷視頻到底是不是deepfake。
S-MIL定義如下:
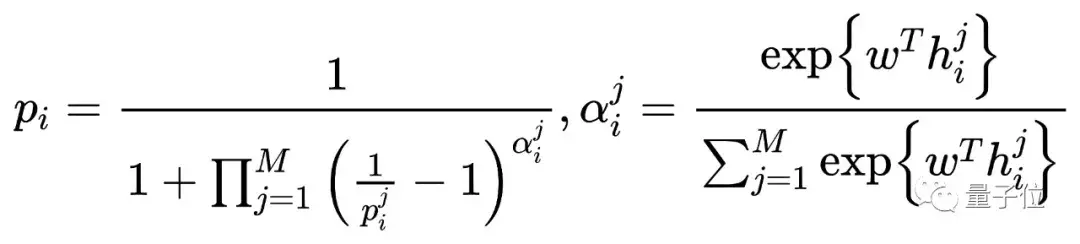
其中,pi和p(i)^(j)分別是第i個(gè)包及其包里的第j個(gè)實(shí)例的正類概率;M為包里的實(shí)例數(shù);w是網(wǎng)絡(luò)參數(shù);h(i)^(j)是包i里的實(shí)例j對(duì)應(yīng)的特征。

由于現(xiàn)有的帶幀標(biāo)簽的數(shù)據(jù)集中,同一視頻中真假人臉混雜的樣本較少,研究人員還構(gòu)建了一個(gè)部分攻擊數(shù)據(jù)集FFPMS。
FFPMS共包含14000幀,包括4種類型的造假視頻(DF、F2F、FS、NT)和原始視頻,既有幀級(jí)標(biāo)簽,也包含視頻級(jí)標(biāo)簽。
檢測(cè)效果達(dá)到SOTA
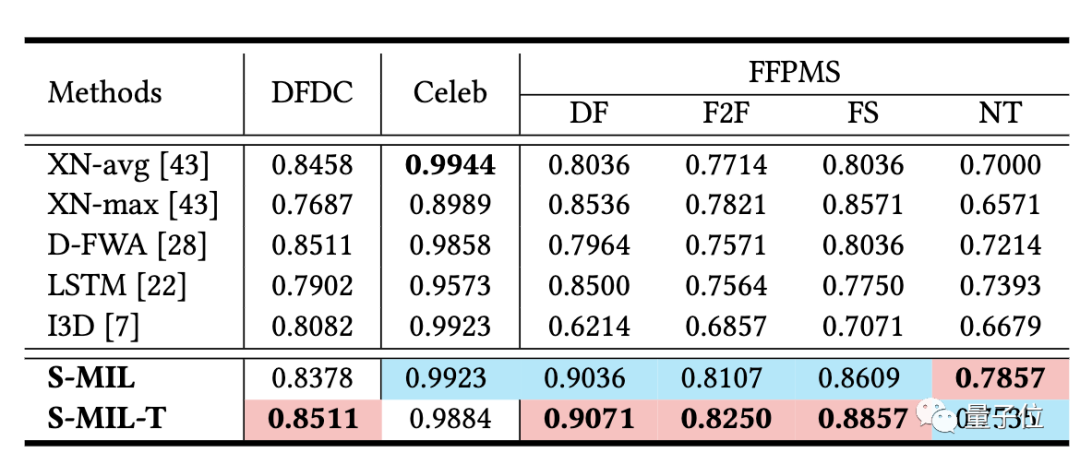
研究人員在DFDC、Celeb和FFPMS數(shù)據(jù)集上對(duì)S-MIL進(jìn)行了評(píng)估。
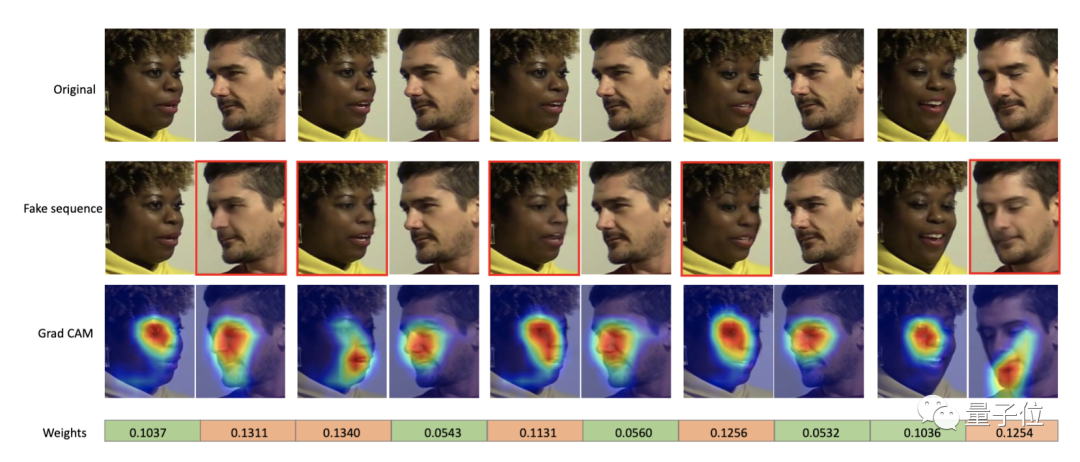
實(shí)驗(yàn)結(jié)果表明,假臉的權(quán)重比較高,說(shuō)明該方法在僅需視頻級(jí)別標(biāo)簽的情況下,可以很好地定位到假臉,具有一定的可解釋性:
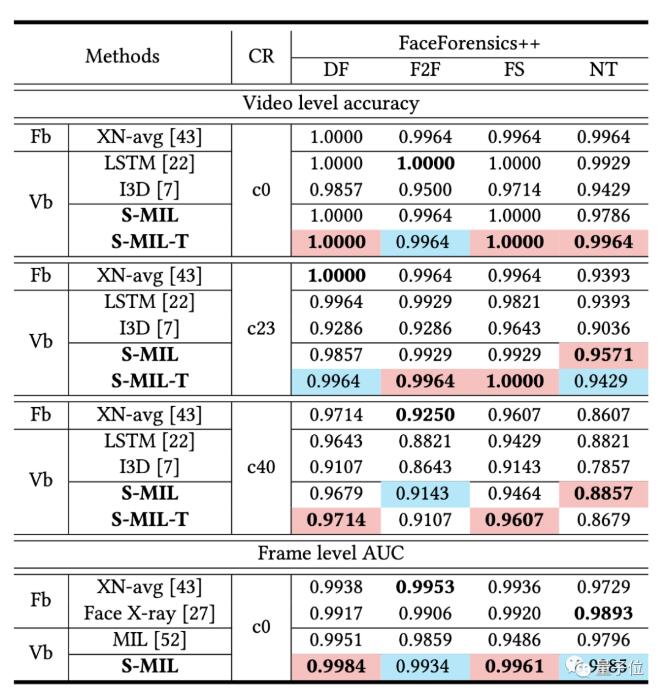
并且,該方法在視頻檢測(cè)上能到達(dá)到state-of-the-art的效果。