10W閱讀,萬人點(diǎn)贊,這套大數(shù)據(jù)平臺建設(shè)方法論,到底有什么干貨
今天給大家分享一套方法論,累計10W+閱讀,1W+點(diǎn)贊的大數(shù)據(jù)平臺建設(shè)方法論。
在數(shù)據(jù)平臺建設(shè)的前期來說,做大數(shù)據(jù)平都是為了日后的數(shù)據(jù)分析來做基礎(chǔ)的。那樣就一定要規(guī)劃出適合企業(yè)的方案。根據(jù)目前國內(nèi)大部分企業(yè)或者單位的我們可以大致分為幾類:
(1)目前企業(yè)已經(jīng)有明確的數(shù)據(jù)分析需求,對于需要分析的數(shù)據(jù)有明確的目標(biāo)。知道自己想要采集哪些應(yīng)用的數(shù)據(jù),也明確出數(shù)據(jù)分析要達(dá)到的最終效果。這樣我們就可以與相對應(yīng)的應(yīng)用系統(tǒng)做數(shù)據(jù)的采集,并對采集的數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化的處理,最后進(jìn)行存儲、分析、建模。
(2)目前企業(yè)不清楚自己數(shù)據(jù)分析的目標(biāo),但是想做一些大數(shù)據(jù)的治理以及規(guī)劃。
(3)對于一些還沒有完整的信息化體制的企業(yè)來說,可能只有一兩個應(yīng)用。在規(guī)劃信息化建設(shè)時要規(guī)劃好自己企業(yè)的數(shù)據(jù)的建設(shè),要統(tǒng)一應(yīng)用間的數(shù)據(jù)標(biāo)準(zhǔn)。然后做出數(shù)據(jù)中臺的規(guī)劃。
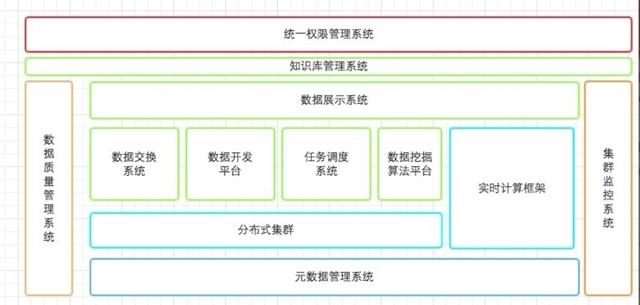
整體方案設(shè)計時需要考慮的因素:
- 數(shù)據(jù)量有多少:幾百GB?幾十TB?
- 數(shù)據(jù)存儲在哪里:存儲在MySQL中?Oracle中?或其他數(shù)據(jù)庫中?
- 數(shù)據(jù)如何從現(xiàn)在的存儲系統(tǒng)進(jìn)入到大數(shù)據(jù)平臺中?如何將結(jié)果數(shù)據(jù)寫出到其他存儲系統(tǒng)中?
- 分析主題是什么:只有幾個簡單指標(biāo)?還是說有很多統(tǒng)計指標(biāo),需要專門的人員去梳理,分組,并進(jìn)行產(chǎn)品設(shè)計;
- 是否需要搭建整體數(shù)倉?
- 是否需要BI報表:業(yè)務(wù)人員有無操作BI的能力,或團(tuán)隊組成比較簡單,不需要前后端人員投入,使用BI比較方便;
對于一個大數(shù)據(jù)平臺主要分為三部分:
- 數(shù)據(jù)接入
- 數(shù)據(jù)處理
- 數(shù)據(jù)分析
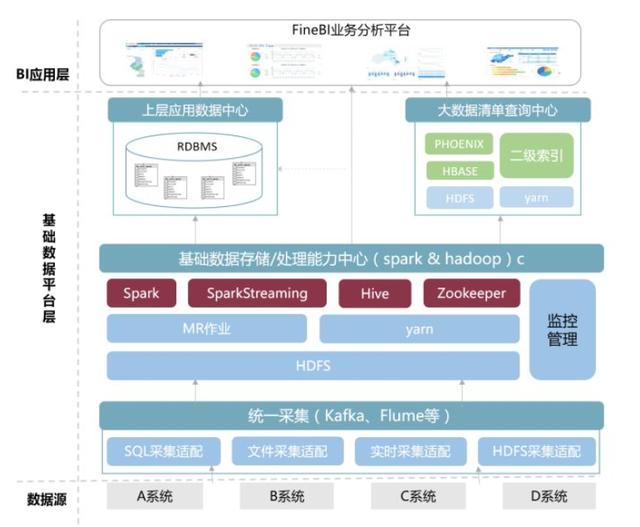
數(shù)據(jù)接入是將數(shù)據(jù)寫入數(shù)據(jù)倉儲中,也就是數(shù)據(jù)整合。因為在企業(yè)中,數(shù)據(jù)可能分布在外部和內(nèi)部,分布在外部的是企業(yè)使用第三方系統(tǒng)產(chǎn)生的數(shù)據(jù)和一些公共數(shù)據(jù),分布在企業(yè)內(nèi)部的是企業(yè)內(nèi)部IT系統(tǒng)產(chǎn)生的數(shù)據(jù)。
這些數(shù)據(jù)一般都是獨(dú)立分布的,也就是所說的數(shù)據(jù)孤島,此時的這些數(shù)據(jù)是沒有什么意義的,因此數(shù)據(jù)接入就是將這些內(nèi)外部的數(shù)據(jù)整合到一起,將這些數(shù)據(jù)綜合起來進(jìn)行分析。
對小公司來說,大概自己找一兩臺機(jī)器架個集群算算,也算是大數(shù)據(jù)平臺了。在初創(chuàng)階段,數(shù)據(jù)量會很小,不需要多大的規(guī)模。這時候組件選擇也很隨意,Hadoop一套,任務(wù)調(diào)度用腳本或者輕量的框架比如luigi之類的,數(shù)據(jù)分析可能hive還不如導(dǎo)入RMDB快。
監(jiān)控和部署也許都沒時間整理,用腳本或者輕量的監(jiān)控,大約是沒有g(shù)anglia、nagios,puppet什么的。這個階段也許算是技術(shù)積累,用傳統(tǒng)手段還是真大數(shù)據(jù)平臺都是兩可的事情,但是為了今后的擴(kuò)展性,這時候上Hadoop也許是不錯的選擇。
比如你的數(shù)據(jù)接入,之前可能找個定時腳本或者爬log發(fā)包找個服務(wù)器接收寫入HDFS,現(xiàn)在可能不行了,這些大概沒有高性能,沒有異常保障,你需要更強(qiáng)壯的解決方案,比如Flume之類的。
你的業(yè)務(wù)不斷壯大,老板需要看的報表越來越多,需要訓(xùn)練的數(shù)據(jù)也需要清洗,你就需要任務(wù)調(diào)度,比如oozie或者azkaban之類的,這些系統(tǒng)幫你管理關(guān)鍵任務(wù)的調(diào)度和監(jiān)控。
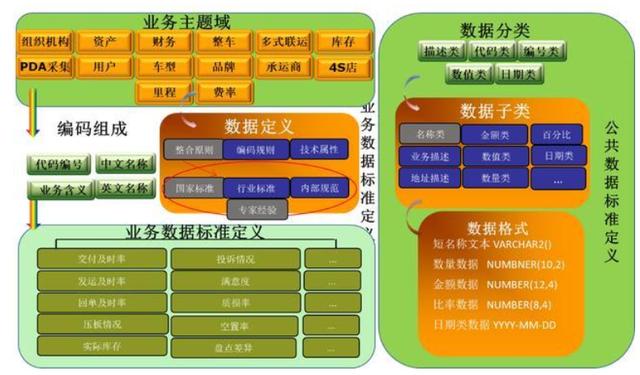
數(shù)據(jù)處理是對接入的數(shù)據(jù)進(jìn)行數(shù)據(jù)清洗和ETL建模,將各個數(shù)據(jù)表之間的關(guān)系建立起來,比如關(guān)聯(lián),聚合,追加等等這些處理。
最后來說說數(shù)據(jù)分析吧。
數(shù)據(jù)分析一般包括兩個階段:數(shù)據(jù)預(yù)處理和數(shù)據(jù)建模分析。
數(shù)據(jù)預(yù)處理是為后面的建模分析做準(zhǔn)備,主要工作時從海量數(shù)據(jù)中提取可用特征,建立大寬表。這個過程可能會用到Hive SQL,Spark QL和Impala。
數(shù)據(jù)建模分析是針對預(yù)處理提取的特征/數(shù)據(jù)建模,得到想要的結(jié)果。如前面所提到的,這一塊最好用的是Spark。
在完成了底層業(yè)務(wù)數(shù)據(jù)整合工作之后,長久物流在整合業(yè)務(wù)系統(tǒng)數(shù)據(jù)的基礎(chǔ)上,通過FineReport數(shù)據(jù)決策系統(tǒng),有效集成了各個業(yè)務(wù)系統(tǒng)的實(shí)時數(shù)據(jù),并根據(jù)各個部門的需求搭建了數(shù)據(jù)分析模板。
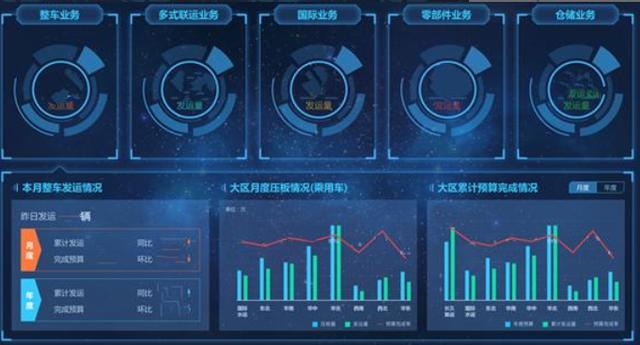
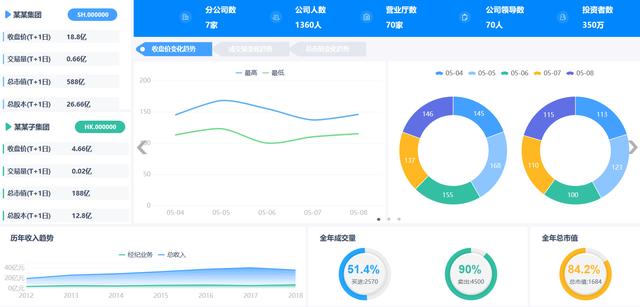
總結(jié)
首先要有Hadoop集群,在有HDFS與Hive后,才能開展數(shù)據(jù)接入工作,才能基于集群建設(shè)工具鏈;當(dāng)工具鏈部分的OLAP引擎構(gòu)建好,才有上層BI、報表系統(tǒng)和數(shù)據(jù)API。
所以弄清了每個部分的相互關(guān)系也就容易明白大數(shù)據(jù)平臺的建設(shè)流程。