













超過Google,微信AI在NLP領(lǐng)域又獲一項(xiàng)世界第一
本文經(jīng)AI新媒體量子位(公眾號ID:QbitAI)授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
微信AI,NLP領(lǐng)域又獲一項(xiàng)世界第一,這次是在機(jī)器閱讀理解方面。
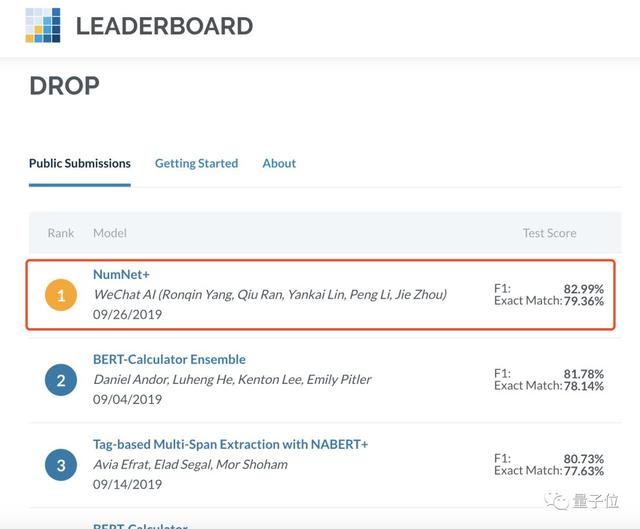
在專門考驗(yàn)計(jì)算機(jī)數(shù)學(xué)推理能力的DROP數(shù)據(jù)集上,微信AI最新方案超過了Google Research,排名第一,成為SOTA。
今年3月,在第七屆對話系統(tǒng)技術(shù)挑戰(zhàn)賽(DSTC7)上,首次亮相的微信智言團(tuán)隊(duì)一路過關(guān)斬將,最終拿下冠軍。
不過這一次,微信AI團(tuán)隊(duì)說,這不僅是他們在機(jī)器閱讀理解方面的進(jìn)展,也是他們在數(shù)學(xué)推理方面的第一篇工作。
這一方案,并沒有以當(dāng)前業(yè)界主流的BERT為核心,而是以數(shù)字感知的圖神經(jīng)網(wǎng)絡(luò)(NumGNN)方案為基礎(chǔ)。
微信AI團(tuán)隊(duì)介紹,在NumGNNd為核心的情況下,結(jié)合NAQANet的基礎(chǔ)模塊以及改進(jìn)的前處理方法,在不使用BERT、RoBERTa等預(yù)訓(xùn)練模型的條件下,就能獲得了高達(dá)67.97%的F1值。
在實(shí)際提交到榜單上的NumNet+上,他們又進(jìn)一步融入RoBERTa的能力,并增加了對多span型問題的支持,從而使單模型 F1值能夠高達(dá)82.99%。
從而,他們也得出了一個結(jié)論:
即使不使用BERT等預(yù)訓(xùn)練模型,模型的效果就已經(jīng)比使用BERT的好了。
微信AI團(tuán)隊(duì)說,這一方案可以幫助人工智能提升閱讀理解能力和邏輯推理能力,將來也會將其中的技術(shù)應(yīng)用到騰訊小微智能對話助手中。
不過區(qū)別于谷歌和百度等智能語音助手的To C產(chǎn)品形式,目前騰訊小微智能對話助手,主要還是以云服務(wù)形式對外輸出。
微信成績意味著什么?AI考數(shù)學(xué)
先從數(shù)據(jù)集DROP說起。
DROP數(shù)據(jù)集,由AI2(Allen Institute for Artificial Intelligence)實(shí)驗(yàn)室提出,主要考察的是模型做類似數(shù)學(xué)運(yùn)算相關(guān)的操作能力。
(小巧合,微信之父張小龍英文名也叫Allen,但allen.ai的域名屬于AI2)
與SQuAD數(shù)據(jù)集中大多都是“劉德華老婆是誰?”的問題不同,其中的問題會涉及到數(shù)學(xué)運(yùn)算的情況。
比如說,給我們5個人每個人買2個蛋撻,一共要買幾個蛋撻?
這個問題對于人來說很簡單,但對于機(jī)器來說卻很困難。
微信AI團(tuán)隊(duì)解釋了這背后的原因:機(jī)器不僅要能夠比較數(shù)字相對的大小,還要能夠知道和哪些數(shù)字做比較并進(jìn)行推理,這就需要把數(shù)字相對的大小等等知識注入模型。
但在之前大多數(shù)機(jī)器閱讀理解模型中,基本上都將數(shù)字與非數(shù)字單詞同等對待,無法獲知數(shù)字的大小關(guān)系,也不能完成諸如計(jì)數(shù)、加減法等數(shù)學(xué)運(yùn)算。
正是基于這一原因,微信AI團(tuán)隊(duì)提出了一種數(shù)字感知的圖神經(jīng)網(wǎng)絡(luò)(numerically-aware graph neural network,NumGNN),并基于此提出了NumNet。
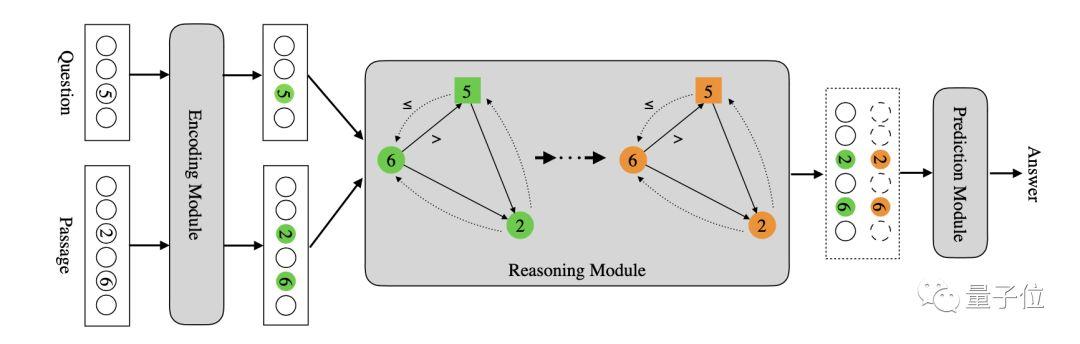
一方面利用圖的拓?fù)浣Y(jié)構(gòu)編碼數(shù)字間的大小關(guān)系,將文章和問題中的數(shù)字作為圖結(jié)點(diǎn),在具有“>”和“<=”關(guān)系的數(shù)字間建立有向邊,從而將數(shù)字的大小關(guān)系作為先驗(yàn)知識注入模型。
具體來講,給定一個問題和一段文本,先把問題里面的數(shù)字和文本里面的數(shù)字都抽出來。
每個數(shù)字就是圖上一個節(jié)點(diǎn),同時對于任意兩個數(shù)字,假如A數(shù)字和B數(shù)字,如果A大于B的話,那么A和B中間加一條有向邊,表示數(shù)字A和B之間是A大于B的關(guān)系。
如果A小于等于B,則會加另外一種有向邊,把它們兩個連接起來。通過這種操作,用圖的拓譜結(jié)構(gòu)把數(shù)字相對大小知識注入模型。
另一方面,是結(jié)合文本信息去做更復(fù)雜的數(shù)學(xué)推理,具體的實(shí)現(xiàn)方式是使用圖卷積神經(jīng)網(wǎng)絡(luò)在前述圖結(jié)構(gòu)上執(zhí)行推理,從而支持更復(fù)雜的數(shù)學(xué)推理功能。
超過Google方案,斬獲全球第一
在DROP數(shù)據(jù)集的LEADERBOARD上,微信AI團(tuán)隊(duì)的方案為NumNet+。
微信AI團(tuán)隊(duì)介紹稱,這一方案的基礎(chǔ)與NumNet一樣,都是NumGNN。
在新的方案中,用預(yù)訓(xùn)練模型替換了NumNet中的未經(jīng)過預(yù)訓(xùn)練的Transformer作為encoder,進(jìn)一步融入了RoBERTa的能力以及對多span型問題的支持。
從而實(shí)現(xiàn)了單模型 F1值 82.99%的效果,一舉超過Google Research的BERT-Calculator Ensemble方案,成為榜單第一。
盡管取得的效果還不錯,但在微信AI團(tuán)隊(duì)來看,但還有很多缺陷。
比如說,目前能夠支持的數(shù)學(xué)表達(dá)式種類還是受到一定限制。尤其是DROP數(shù)據(jù)集的局限,其對文本理解的要求更高,但需要的數(shù)學(xué)推理難度比解數(shù)學(xué)應(yīng)用題那類問題來得相對簡單一點(diǎn)。
微信AI團(tuán)隊(duì)說,如何把兩者更好的結(jié)合起來,使得整個模型的能力進(jìn)一步的提升,是他們下一步考慮的問題。
而且,他們也說,并不會把注意力集中在用GNN來解決數(shù)字推理的問題上,后面也會重點(diǎn)去考慮其他的方式。
更具體來說,是能夠?qū)rithmetic word problems (AWPs)相關(guān)工作中處理復(fù)雜數(shù)學(xué)表達(dá)式相關(guān)的方法能夠進(jìn)行吸收融合,進(jìn)一步提升模型的推理能力。
更多詳情,可以前往DROP數(shù)據(jù)集LEADERBOARD:
https://leaderboard.allenai.org/drop/submissions/public
而微信AI這次的研究成果,已經(jīng)被EMNLP2019收錄,論文也已公開發(fā)表:
NumNet: Machine Reading Comprehension with Numerical Reasoning
https://arxiv.org/abs/1910.06701
項(xiàng)目地址:
https://github.com/llamazing/numnet_plus














