GRPO訓練不再「自嗨」!快手可靈 x 中山大學推出「GRPO衛(wèi)兵」,顯著緩解視覺生成過優(yōu)化
論文第一作者為王晶,中山大學二年級博士生,研究方向為強化學習與視頻生成;通訊作者為中山大學智能工程學院教授梁小丹。
目前,GRPO 在圖像和視頻生成的流模型中取得了顯著提升(如 FlowGRPO 和 DanceGRPO),已被證明在后訓練階段能夠有效提升視覺生成式流模型的人類偏好對齊、文本渲染與指令遵循能力。
在此過程中,重要性比值的 clip 機制被引入,用于約束過于自信的正負樣本梯度,避免破壞性的策略更新,從而維持訓練的穩(wěn)定性。然而,實證分析顯示,該機制存在系統(tǒng)性偏差:其均值長期低于 1,導致過度自信的正梯度無法得到有效限制;同時,不同去噪步下比值的分布方差差異顯著,使得部分步驟的 clip 機制失效。
結果,模型在訓練過程中容易陷入過度優(yōu)化狀態(tài)——即代理獎勵持續(xù)上升,但圖像質量及文本與提示的對齊度反而下降,導致優(yōu)化后的模型在實際應用中效果不佳。
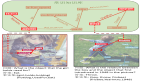
圖像質量隨優(yōu)化過程的變化如下:

為此,中山大學、快手可靈以及港中文 MMLab 等團隊聯(lián)合提出了 GRPO-Guard,這是首個針對 GRPO 在流模型中出現(xiàn)的過度優(yōu)化問題而設計的解決方案。GRPO-Guard 能在保證快速收斂的同時,大幅降低過度優(yōu)化的風險。
在 Flow-GRPO、DanceGRPO 等多種 GRPO 變體、不同擴散骨干模型(如 SD3.5-M、FLUX1.dev),GRPO-Guard 在文本渲染、GenEval、PickScore 等多種代理任務中均展現(xiàn)出穩(wěn)定顯著的提升,同時有效緩解 reward hacking 現(xiàn)象,提高優(yōu)化后模型的實際應用價值。
目前該項目的論文和代碼均已開源:

- 論文標題:GRPO-Guard: Mitigating Implicit Over-Optimization in Flow Matching via Regulated Clipping
- 論文鏈接:https://arxiv.org/abs/2510.22319
- 代碼地址:https://github.com/yifan123/flow_grpo

核心問題:比值分布偏移破壞 Clip 約束
在 FlowGRPO 中,通常采用高斯概率函數計算重要性比值中的

由于二階項的引入,log-importance ratio 在 off-policy 情況下會受到二次項的影響,表現(xiàn)出均值低于 1 且不同去噪步驟(denoising step)方差差異顯著的現(xiàn)象。

具體來說,二階項  的影響,使得重要性比值的均值
的影響,使得重要性比值的均值
偏向小于 1,同時方差隨著去噪步驟的增加而逐漸增大。

理想情況下,重要性比值的均值應接近 1,以保證左右 clip 區(qū)間均衡,使有害的正負樣本梯度能夠被有效約束。然而,均值偏移和方差差異會導致預先設定的 clip 機制失效:一方面,正樣本梯度無法被充分約束;另一方面,部分步驟的 clip 機制失效,從而使策略(policy)陷入過度優(yōu)化狀態(tài)。
此外,F(xiàn)lowGRPO 中不同去噪步驟的梯度存在顯著差異。具體而言

其中,受系數梯度系數  影響,高噪聲步驟的梯度貢獻較小,而低噪聲步驟的梯度貢獻較大,這可能導致模型在訓練中偏向于單一的噪聲條件。不同步驟的梯度系數(左一)及實際梯度貢獻(左二)如圖所示:
影響,高噪聲步驟的梯度貢獻較小,而低噪聲步驟的梯度貢獻較大,這可能導致模型在訓練中偏向于單一的噪聲條件。不同步驟的梯度系數(左一)及實際梯度貢獻(左二)如圖所示:

解決思路:RatioNorm 和跨步梯度平衡
針對上述問題,為每個去噪步驟單獨設定特定的 clip 范圍顯得過于繁瑣。為此,我們提出 GRPO-Guard,在原有 GRPO 框架上引入兩項關鍵改進:
- 比率歸一化(RatioNorm):對每個去噪步驟的重要性比值分布進行標準化,使其均值接近 1,方差保持一致,從而恢復 clip 機制的有效性,避免因正樣本裁剪失效而引發(fā)的過度優(yōu)化。

該機制對梯度的影響如下所示:

- 跨步梯度平衡:基于 RatioNorm 對各去噪步驟的梯度進行均衡,使策略在整個噪聲時間表上均勻探索,如右圖(右 1)所示。這不僅防止了單步過擬合,還提升了訓練的穩(wěn)定性與生成多樣性。整體策略損失(policy loss)如下所示:其中

經過 RatioNorm 調整后的重要性比值分布對比:

FlowGRPO:均值小于 1,破壞性正樣本約束失效

GRPO-Guard:均值接近 1,破壞性正樣本得到約束
實驗結果:顯著緩解過優(yōu)化
我們在 FlowGRPO 和 DanceGRPO 兩種不同的 GRPO 算法、SD3.5-M 和 Flux1.dev 兩種擴散骨干模型,以及 GenEval、PickScore 和文本渲染等多種任務上驗證了 GRPO-Guard 的有效性。實驗結果表明,GRPO-Guard 能顯著緩解過度優(yōu)化現(xiàn)象,同時保持與 baseline 相近的性能提升。
具體而言,不同任務的 proxy score 與 gold score 對比顯示:在 baseline 方法中,gold score 存在明顯下降趨勢,而在 GRPO-Guard 下,這一下降趨勢被顯著緩解。


訓練過程圖像質量可視化:FlowGRPO/DanceGRPO 等算法隨著訓練的進行,策略(policy)過度優(yōu)化問題明顯,導致圖像質量顯著下降。GRPO-Guard 則在訓練過程后期仍然保持了較高的圖像質量。

更多可視化樣例顯示,在 baseline 方法下,在文本響應和圖像質量都呈現(xiàn)出明顯的退化,而 GRPO-Guard 能在提升目標 reward 的同時較好地保持文本響應和圖像質量。



在 PickScore 任務中,baseline 方法在訓練后期生成的人體比例存在不一致現(xiàn)象,且多人臉型過于相似,極大影響了生成多樣性,GRPO-Guard 顯著緩解了這個問題。

總結與展望:邁向更穩(wěn)健的視覺生成式強化學習
作為首先關注 GRPO 在視覺生成中過優(yōu)化現(xiàn)象的研究,GRPO-Guard 通過比率歸一化(RatioNorm)和跨步梯度平衡,有效穩(wěn)定策略更新,恢復裁剪機制對正樣本的約束,并緩解過度優(yōu)化。實驗表明,無論在不同 GRPO 變體、擴散骨干模型,還是多種代理任務中,GRPO-Guard 都能保持甚至提升生成質量,并提升訓練的穩(wěn)定性和多樣性。
本質上過優(yōu)化問題的出現(xiàn)是由于 proxy score 和 gold score 的巨大差距而導致的,雖然 GRPO-Guard 從優(yōu)化過程上緩解了過優(yōu)化現(xiàn)象,但并未徹底根治。未來,應該構建更精確的獎勵模型,使代理分數更接近真實評估(gold score),從而進一步減少 reward hacking 并提升優(yōu)化效果。這將為 GRPO 在流模型及更廣泛的生成任務中的實際應用提供更可靠的技術保障。