編輯|聽雨
出品 | 51CTO技術棧(微信號:blog51cto)
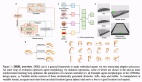
最近,李飛飛、謝賽寧、Yann LeCun 等大佬頻頻提到一個詞——空間智能(Spatial Intelligence)。它不是單純“看懂圖像或視頻”,而是理解空間結構、記住發生的事情,并能預測未來。換句話說,真正的 AI 不只是“看見”,還要感知、理解,并主動組織經驗,這是未來多模態智能的核心能力。
就在近期,這三位大佬首次聯手,發布了論文《Cambrian-S:邁向視頻中的空間超感知》。
 圖片
圖片
論文提出了全新的范式——超感知(Supersensing):AI 模型不僅要看到、識別、回答,還要能記住、理解場景的三維結構,并預測未來、組織經驗,通過此過程構建出自己的內部世界模型(Internal World Model)。
 圖片
圖片
論文共同一作Shusheng Yang在X上表示:真正具備超感知智能的系統,需要主動預測、篩選并組織感官輸入,而不僅僅是被動接收信息。
 圖片
圖片
謝賽寧則指出,Cambrian-S 是團隊在視頻中探索空間超感知的初步嘗試。雖然論文篇幅很長,但細節豐富、觀點前沿,如果你關注視頻多模態模型,絕對值得一讀。
一、如何界定“空間超感知”?
去年,謝賽寧團隊就發布了 Cambrian-1 —— 一個面向圖像的開放式多模態模型探索項目。但他們沒有急著去構建 Cambrian-2 或 Cambrian-3,而是先停下來思考:
- 什么才是真正的多模態智能?
- 用大語言模型(LLM)的范式去建模感知,真的合理嗎?
- 為什么人類的感知如此輕松、直覺,卻又極其強大?
團隊意識到,有某種根本性的東西還缺失。謝賽寧表示,如果沒有先構建出“超感知(supersensing)”,就不可能構建出“超級智能(superintelligence)”。
那么,什么是超感知?它并不是指更先進的傳感器或更高端的攝像機,而是指一個數字生命體如何真正體驗世界——它能夠持續吸收無盡的感官輸入流,并從中不斷學習。
超感知是智能的一部分,就像眼睛是大腦與外界接觸的那一部分。你不需要感知就能解決編程或數學問題。但如果是要讓 AI 代理在真實世界中行動,那它就必須具備感知建模(sensory modeling)能力。謝賽寧還引用了 Karpathy 大神所說的,感知建模也許正是智能所需要的一切。
研究團隊將超感知能力劃分為五個層級:

1、無感知能力(No sensory capabilities):例如語言模型(LLMs),只具備語言理解。它們的推理僅限于文本與符號,其“世界知識”并非基于真實物理世界的感知。
2、語義感知(Semantic perception):能夠將像素解析為物體、屬性與關系。這一層級對應當前多模態大模型(MLLM)在“看圖說話”等任務中表現出的強大能力。
3、流式事件認知(Streaming event cognition):能夠處理實時、無邊界的數據流,并主動解釋與響應正在發生的事件。這一方向與當前讓 MLLM 成為實時助理的努力相契合。
4、隱式三維空間認知(Implicit 3D spatial cognition):能夠理解視頻是三維世界的投影。智能體必須知道“有哪些物體”、“它們在哪里”、“彼此如何關聯”,以及“這些空間配置如何隨時間變化”。當下的視頻模型在這一層面仍然非常受限。
5、預測性世界建模(Predictive world modeling):人腦通過基于先驗預期預測潛在的世界狀態,從而進行“無意識推理”。當預測被打破時,“驚訝(surprise)”會引導注意力、記憶與學習。然而,當前的多模態系統缺乏這種能夠預判未來狀態的內部模型,也無法利用“驚訝”機制去組織感知、形成記憶或做出決策。
二、如何評測“空間超感知”?
為回答這個問題,研究團隊對現有的視頻基準進行了系統審查,發現盡管這些基準在一定程度上具有研究價值,但大多數視頻基準主要關注語言理解和語義感知,而忽視了更高層次的空間超感知能力。
一些新近基準(例如 VSI-Bench)確實開始關注空間感知,但它們仍局限于有限的視頻時長。因此,它們難以反映視覺流(visual streams)那種無邊界、連續性強的特性——而這恰恰是實現“超感知”以及應對真實世界挑戰所必需的能力。

于是,他們提出了一套新的基準 VSI-SUPER——謝賽寧說這是一套更“笨”但更難”的版本,它包含兩條任務:
1、VSI-SUPER Recall(VSR):要求模型在長時程的時空視頻中觀察,并依次回憶出一個異常物體的位置。
2、VSI-SUPER Count(VSC):測試多模態大模型(MLLM)在長視頻場景中持續累積空間信息的能力。
VSR 和 VSC 的設計目的都是打破現有范式,通過將多個短視頻片段拼接成任意長度的長視頻,來考察模型對“無界視覺流”的理解與記憶能力。
團隊測試了當下最強的視頻多模態模型之一 —— Gemini-2.5 Flash,結果發現:盡管 Gemini 在通用視頻基準上表現領先,但在 VSI-SUPER 上仍然失敗。

你可能會問——這不就是一個數據或規模(scaling)問題嗎?
謝賽寧表示,某種程度上,確實是。但這也是他們為什么要構建全新的 Cambrian-S 視頻多模態大模型系列。團隊希望在現有范式下盡可能地推動極限。他們認為,數據與規模對于實現超感知(supersensing)是必要的,但并非充分條件。核心問題在于:目前根本沒有真正用于空間認知的訓練數據。
因此,團隊構建了 VSI-590K 數據集,它包含 59 萬條訓練樣本,來源包括:
- 第一人稱視角探索的室內環境(帶 3D 標注)
- 模擬器生成的視頻
- 利用 VGGT 等視覺工具進行偽標注的 YouTube 視頻

團隊還探索了后訓練策略、數據混合方案以及一系列工程細節,訓練了從 0.5B 到 7B 參數規模的模型。

結果顯示:這些模型在空間推理上表現強勁,比基礎 MLLM 提升高達 30%,即便是最小的模型也表現不俗。
數據與模型已經開源,但他們很明確:這仍然無法解決 VSI-SUPER 的任務。團隊越來越確信,用 LLM 的方式去構建多模態模型,并不是通向超感知的最終道路。
三、全新原型:預測感知
基于上述基礎,團隊打造了 Cambrian-S 系列模型,其特點包括:1、具備競爭力的通用視頻/圖像理解能力2、領先的空間感知性能
團隊還觀察到:1、它能夠很好地泛化到未見過的空間任務2、在去偏測試(debias stress test)下表現穩健
然而,它在 VSI-SUPER 上仍然失敗:1、在 VSR(長時程空間回憶) 任務中,幾乎無法泛化到超過 60 分鐘的視頻2、在 VSC(持續計數) 任務中,10 分鐘視頻的計數仍然困難

展望未來,團隊正在原型化一個新方向——預測感知(predictive sensing)。論文引用了大量來自認知科學和發展心理學的研究,這些研究指出,人類視覺系統帶寬極高,但效率驚人。每只眼睛約有 600 萬個視錐細胞,理論傳輸速度約 1.6 Gbit/s,但大腦僅用約 10 bits/s 來指導行為。
舉一個 Jurgen 提出的世界模型例子:
以棒球為例。棒球擊球手只有幾毫秒的時間決定如何揮棒——這比視覺信號從眼睛傳到大腦所需的時間還短。我們之所以能擊中每小時 100 英里(約 160 公里)的快速球,是因為我們能夠本能地預測球的運動方向與落點。對于職業球員來說,這一切幾乎都是無意識完成的。
 Credit: https://worldmodels.github.io/
Credit: https://worldmodels.github.io/
那么,大腦是如何做到的呢?一個領先理論是:大腦在后臺運行一個預測性世界模型(predictive world model)來進行感知,不斷預測未來并與實際發生的情況比較。
- 如果預測誤差低 → 屬于預期,可忽略
- 如果預測誤差高 → 屬于驚訝(surprise),大腦會注意并更新記憶
而目前的 LLMs 中,還沒有可比的機制。
為了驗證這一想法,團隊在 Cambrian-S 上訓練了一個潛變量幀預測(latent frame prediction, LFP)頭,在推理階段,模型會持續預測下一個輸入的期望,將該期望與實際觀測進行比較,將兩者的差異定義為“驚訝值(surprise)”。“驚訝值”用于兩方面:
1、驚訝驅動的記憶管理 —— 壓縮或跳過不令人驚訝的幀,將計算資源集中在驚訝幀上2、驚訝驅動的事件分割 —— 利用驚訝峰值檢測事件邊界或場景變化

通過利用這個內部預測模型提供的信號,已經在空間認知任務上看到了喜人的性能提升。
這目前只是一個簡化的預測性世界模型原型——但僅憑這一機制,小模型就在VSI-Super評測基準上超越了Gemini。
值得一提的是,團隊還同步發布了兩個相關項目:
1、關于多模態基準設計的研究:如何對基準進行應力測試,以及如何正確去除語言偏差

2、一份經驗總結:構建模擬器以收集空間感知視頻,也是為 Cambrian-S 使用的數據來源

四、作者介紹
 圖片
圖片
共同一作Shusheng Yang是紐約大學計算機科學專業的博士生,曾參與 Qwen 模型的開發,指導老師是謝賽寧教授。
 圖片
圖片
共同一作Jihan Yang,是紐約大學庫朗研究所的一名博士后副研究員,師從謝賽寧教授。此前,Jihan Yang于香港大學獲得了博士學位,中山大學獲得了學士學位。 他的研究興趣集中在機器學習和計算機視覺領域,特別關注多模態和具身智能。
 圖片
圖片
核心作者黃品志是紐約大學本科生,師從謝賽寧教授,曾在谷歌Gemini 實習。
目前所有鏈接已經開源:
項目主頁:https://cambrian-mllm.github.io/
論文鏈接:https://arxiv.org/abs/2511.04670
代碼鏈接:https://github.com/cambrian-mllm/cambrian-s
Cambrian-S 模型合集:https://huggingface.co/collections/nyu-visionx/cambrian-s-models
VSI-590K 數據集:https://huggingface.co/datasets/nyu-visionx/VSI-590K
VSI-SUPER 基準合集:https://huggingface.co/collections/nyu-visionx/vsi-super