PubSub-VFL——基于發布訂閱架構的高效異構垂直聯邦學習框架

研究背景:垂直聯邦學習面臨的異構挑戰
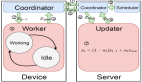
隨著數據隱私保護法規的日益嚴格和跨機構數據協作需求的不斷增長,垂直聯邦學習(Vertical Federated Learning, VFL)作為一種重要的隱私保護機器學習范式受到廣泛關注。在 VFL 中,不同參與方擁有相同用戶的不同特征維度,通過協作訓練可以構建更強大的機器學習模型,樸素的 VFL 框架如下圖所示。

基于分割學習的樸素 VFL 框架
然而,現有的 VFL 系統在實際部署中面臨著嚴峻的異構性挑戰:
- 資源異構性:不同參與方的計算資源、網絡帶寬、存儲能力存在顯著差異
- 數據異構性:各方的數據分布、數據量、特征維度可能差異巨大
- 系統異構性:參與方使用不同的硬件平臺、操作系統和軟件環境
傳統的參數服務器(Parameter Server, PS)架構雖然在數據并行場景下表現出色,但在處理 VFL 中的異構環境時存在明顯不足:
- 同步等待開銷大:系統性能受限于最慢的參與方,導致整體訓練效率低下
- 通信模式固化:點對點的通信方式缺乏靈活性,難以適應動態的網絡環境
- 資源利用率低:無法根據各方的實際資源情況進行自適應調度和優化
核心創新:PubSub-VFL 框架設計
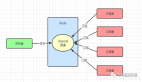
為解決上述挑戰,字節跳動研究團隊提出了 PubSub-VFL 框架,其核心創新在于將發布訂閱(Pub/Sub)架構與參數服務器架構相結合,構建了一個層次化的異步通信機制。系統總體架構如下圖所示。

PubSub-VFL 系統架構
雙層異步協同
PubSub-VFL 采用創新的雙層異步架構設計:
- 參與方間(Inter-party)異步:采用發布/訂閱(Pub/Sub)架構達成參與方之間的異步通信,借助消息代理(Message Broker)對發布者與訂閱者進行解耦此方法使訓練器(Worker)能夠專注于本地訓練,而無需預先保證數據標識符(ID)的嚴格對齊,有效地將訓練過程與數據 ID 匹配任務相分離,進而實現異步操作,消除等待延遲,提升系統并發性。
- 參與方內(Intra-party)異步:在 Pub/Sub 架構的基礎上,我們實現了跨參與方的異步通信,有效地消除了 Worker 端的等待延遲。為了進一步提高每個參與方內部(即參數服務器(PS)與其 Worker 之間)的計算效率,我們通過一個內部異步機制擴展了這一設計。然而,如果控制不當,這種分層異步可能會阻礙模型收斂。為了解決這個問題,我們提出了一種動態半異步機制,該機制根據訓練反饋自適應地調節同步間隔。具體來說,隨著模型接近目標準確率,同步間隔會減小,從而在計算速度和收斂穩定性之間取得平衡。
傳統 PS 架構的局限
- 同步等待開銷大
- 通信模式固化
- 難以處理異構環境
- 資源利用率低
PubSub-VFL 的優勢
- 層次化異步通信
- 靈活的消息傳遞
- 自適應資源調度
- 高效異構處理
下圖具體形象化展示了 PubSub 對比傳統 PS 在性能和架構上的優越性。

傳統異步框架與 Pub/Sub 異步框架
安全系統建模
樸素 VFL 方案因未考慮參與方資源與數據異質性,常導致計算負載失衡、資源利用率低,且集中式資源調度會泄露隱私。為此,PubSub-VFL 提出基于系統畫像的建模方法,通過刻畫雙方硬件能力(CPU 核心數)、模型特性(前向 / 反向傳播耗時),精準量化計算與通信延遲。

最佳參數規劃
傳統 VFL 依賴經驗設置超參數(worker 數量、批大小),難以在資源約束(內存上限等)下最小化迭代耗時。
PubSub-VFL 在系統規劃階段,將超參數優化轉化為帶約束的極小化問題,以

最后,通過動態規劃遍歷離散決策空間,高效找到最優參數配置,解決了異質性場景下資源浪費與訓練延遲問題。
數據隱私保護
為了強隱私保護能力,PubSub-VFL 集成了高斯差分隱私(Gaussian Differential Privacy, GDP)協議:
- 嵌入信息保護:對傳輸的嵌入向量添加高斯噪聲,防止嵌入反轉攻擊(Embedding Inversion Attack, EIA)
- 理論收斂保證:研究團隊從理論上證明了即使在差分隱私保護下,PubSub-VFL 仍能保證穩定收斂
- 隱私-效用平衡:通過自適應噪聲調節機制,在保護隱私的同時最大化模型性能
實驗驗證:顯著的性能提升
實驗設置
- 實驗環境:為評估我們 PubSub-VFL 系統的性能,我們在五個數據集上進行了廣泛的實驗。所有實驗均使用 Python 3.9 和 PyTorch 1.12 開發,并在配備 Intel (R) Xeon (R) Gold 6530(64 核 CPU)的服務器上進行評估。
- 數據集:我們在四個公共基準數據集上評估了 PubSub-VFL,涵蓋了回歸和分類任務,以及一個大規模的合成數據集。對于回歸任務,我們使用了 Energy 和 Blog 數據集。對于分類任務,我們采用了 Bank 和 Credit 數據集。為了評估可擴展性,我們使用 scikit-learn 生成了一個包含 100 萬樣本和 500 個特征的合成數據集。
- 模型:對于頂部模型,我們使用了一個兩層的多層感知器(MLP)。對于底部模型,我們使用了兩種不同大小的模型,即一個 10 層的 MLP 和一個 ResNet,這可以驗證 PubSub-VFL 在不同模型大小下的性能。
- 基線:我們采用了以下基線:1)純 VFL;2)帶 PS 的 VFL;3)異步 VFL(AVFL);4)帶 PS 的異步 VFL。
性能與資源利用率
PubSub-VFL 在計算和通信效率方面表現出色。與表現最佳的基線 AVFL-PS 相比,PubSub-VFL 的運行時間減少了7倍,CPU 利用率提高了35%。這些收益源于“工人”空閑時間的減少和并行性的提高。此外,分層異步機制提高了收斂效率,導致通信成本低于其他方法。
PubSub-VFL 方案在模型精度方面表現優異。在多個基準數據集上的實驗結果顯示,PubSub-VFL 的精度與現有最先進方法相當甚至更高,也證明了該方案在不同任務和模型規模下的魯棒性。
數據集 | 度量 | VFL | VFL-PS | AVFL | AVFL-PS | PubSub-VFL |
Energy | RMSE | 84.58 | 84.44 | 85.41 | 85.39 | 85.64 |
Blog | RMSE | 23.20 | 23.12 | 23.38 | 23.45 | 22.34 |
Bank | AUC | 94.54 | 94.13 | 94.12 | 94.16 | 96.54 |
Credit | AUC | 81.90 | 81.34 | 80.83 | 80.34 | 82.34 |
Synthetic | AUC | 91.27 | 91.31 | 90.97 | 91.21 | 92.87 |
在資源和數據異構場景中,PubSub-VFL 同樣表現出色。當 CPU 核心比例為50:14時,PubSub-VFL 的 CPU 利用率仍高達87.42%,而 AVFL-PS 僅為42.12%。這表明 PubSub-VFL 能有效平衡計算效率,減少運行時間并保持高 CPU 利用率。
參數敏感性分析與消融分析
實驗還驗證了系統各組件的有效性:
- 工作節點數量:在4-16個節點范圍內,性能隨節點數增加而提升,但邊際效應遞減
- 批處理大小:存在最優批處理大小,過大或過小都會影響效率
- 隱私預算:隱私保護強度與模型性能之間存在可調節的權衡關系
通過消融研究,我們發現等待截止時間和內部半異步機制對 PubSub-VFL 的性能至關重要,它們有效地平衡了同步和異步,以減輕梯度陳舊性并確保及時更新。移除這些機制會導致顯著的性能下降。
技術亮點與創新貢獻
PubSub-VFL 框架的主要技術貢獻包括:
- 架構創新
首次將 Pub/Sub 架構引入 VFL,實現了層次化異步通信機制,有效解決了異構環境下的同步等待問題
- 系統優化
提出系統分析規劃驅動的超參數優化方法,能夠根據實際資源情況自動調整系統配置
- 隱私保護
集成高斯差分隱私協議,在保護隱私的同時提供理論收斂保證
應用前景與行業意義
PubSub-VFL 框架在多個領域具有廣闊的應用前景:
- 金融科技領域:銀行、保險公司等金融機構可以在不共享敏感客戶數據的前提下,聯合訓練風險評估和欺詐檢測模型,提升金融服務的智能化水平。
- 醫療健康領域:不同醫院和研究機構可以協作訓練疾病診斷和藥物發現模型,在保護患者隱私的同時推動醫療 AI 的發展。
- 智能制造領域:制造企業可以與供應鏈伙伴聯合優化生產流程和質量控制,在保護商業機密的前提下實現協同創新。
- 廣告營銷領域:廣告平臺和品牌方可以在保護用戶隱私的前提下,聯合訓練更精準的推薦和定向廣告模型。
總結與展望
PubSub-VFL 框架通過引入發布訂閱架構和系統分析規劃機制,成功解決了垂直聯邦學習在異構環境下面臨的效率和隱私挑戰。該研究不僅在理論上提供了新的架構設計思路,更在實踐中展現了顯著的性能優勢,為聯邦學習技術的產業化應用奠定了重要基礎。
目前,本文所提及的工作成果(《PubSub-VFL: Towards Efficient Two-Party Split Learning in Heterogeneous Environments via Publisher/Subscriber Architecture》)被機器學習頂級會議 NeurIPS 2025 正式接收。該研究提出了 PubSub-VFL 框架,創新性地將發布訂閱(Publisher/Subscriber)架構引入垂直聯邦學習,在異構環境下顯著提升了雙方分割學習的計算效率,為聯邦學習在實際部署中面臨的資源異構和數據異構問題提供了高效解決方案。