構(gòu)筑數(shù)字世界的基石:設(shè)計(jì)每日億級(jí)請(qǐng)求、抗網(wǎng)絡(luò)分區(qū)的全局遞增ID系統(tǒng)
在現(xiàn)代分布式系統(tǒng)的宏偉藍(lán)圖中,每一個(gè)數(shù)據(jù)對(duì)象都需要一個(gè)獨(dú)一無(wú)二的身份標(biāo)識(shí)。從電商平臺(tái)的每一筆訂單,到社交網(wǎng)絡(luò)的每一條動(dòng)態(tài),再到金融系統(tǒng)的每一次交易,這個(gè)標(biāo)識(shí)——我們稱之為ID——是整個(gè)數(shù)據(jù)生命周期的起點(diǎn)。它不僅是數(shù)據(jù)庫(kù)的主鍵,更是數(shù)據(jù)分區(qū)、索引、緩存和關(guān)聯(lián)查詢的根基。
當(dāng)業(yè)務(wù)規(guī)模攀升至每日億級(jí)請(qǐng)求時(shí),ID生成系統(tǒng)面臨的挑戰(zhàn)遠(yuǎn)超簡(jiǎn)單的“唯一性”。它必須滿足:
1. 全局唯一:在分布式環(huán)境下,絕對(duì)不允許出現(xiàn)重復(fù)ID。
2. 總體趨勢(shì)遞增:并非嚴(yán)格連續(xù),但必須保持大體上的時(shí)間順序。這對(duì)于數(shù)據(jù)庫(kù)的索引性能至關(guān)重要(例如,InnoDB的B+Tree索引)。
3. 高可用與低延遲:每日1億請(qǐng)求意味著平均QPS超過(guò)1157,峰值可能數(shù)倍于此。系統(tǒng)必須7x24小時(shí)可用,且響應(yīng)時(shí)間必須在毫秒級(jí)別。
4. 高吞吐與可擴(kuò)展性:系統(tǒng)必須能夠輕松應(yīng)對(duì)流量增長(zhǎng)。
5. 抗網(wǎng)絡(luò)分區(qū):在分布式系統(tǒng)著名的CAP定理中,當(dāng)網(wǎng)絡(luò)發(fā)生分區(qū)(P)時(shí),系統(tǒng)必須在一致性(C)和可用性(A)之間做出選擇。對(duì)于ID生成這種核心服務(wù),我們通常優(yōu)先保證可用性。
本文將深入探討如何設(shè)計(jì)一個(gè)滿足以上所有苛刻要求的全局遞增ID系統(tǒng)。
一、 傳統(tǒng)方案的瓶頸與局限
在直面挑戰(zhàn)之前,我們先審視一些傳統(tǒng)方案為何無(wú)法勝任。
1. 數(shù)據(jù)庫(kù)自增ID:
? 原理:依靠數(shù)據(jù)庫(kù)(如MySQL)的AUTO_INCREMENT機(jī)制。
? 瓶頸:?jiǎn)吸c(diǎn)數(shù)據(jù)庫(kù)極易成為性能和可用性的瓶頸。即使通過(guò)設(shè)置不同步長(zhǎng)(step)來(lái)部署多個(gè)數(shù)據(jù)庫(kù)實(shí)例,也無(wú)法保證ID的全局遞增性,只能是多個(gè)遞增序列的拼接,且運(yùn)維復(fù)雜。
2. UUID:
? 原理:基于時(shí)間、節(jié)點(diǎn)ID、隨機(jī)數(shù)等生成128位的字符串。
? 優(yōu)點(diǎn):本地生成,性能極高,無(wú)需中心化協(xié)調(diào)。
? 致命缺點(diǎn):完全無(wú)序。作為數(shù)據(jù)庫(kù)主鍵時(shí),會(huì)導(dǎo)致頻繁的頁(yè)分裂,嚴(yán)重?fù)p害寫(xiě)入性能。且長(zhǎng)度過(guò)長(zhǎng),存儲(chǔ)和索引效率低。
3. Redis INCR:
? 原理:利用Redis的單線程原子性INCR命令生成序列。
? 優(yōu)點(diǎn):性能優(yōu)于數(shù)據(jù)庫(kù)。
? 瓶頸:需要持久化以避免數(shù)據(jù)丟失,這會(huì)影響性能。Redis集群模式下的數(shù)據(jù)同步和故障轉(zhuǎn)移同樣會(huì)引入復(fù)雜性和可用性風(fēng)險(xiǎn)。
顯然,我們需要一個(gè)更分布式、更健壯的方案。
二、 核心架構(gòu):基于“雪花算法”的變體與分段號(hào)
業(yè)界普遍采用的解決方案是Twitter開(kāi)源的Snowflake(雪花算法)。其核心思想是將一個(gè)64位的Long型ID劃分為多個(gè)部分:
| 1 Bit 未使用 | 41 Bit 時(shí)間戳 | 10 Bit 工作節(jié)點(diǎn)ID | 12 Bit 序列號(hào) |? 時(shí)間戳(41位):記錄當(dāng)前時(shí)間與一個(gè)自定義紀(jì)元(如 2020-01-01)的毫秒差。41位可以使用約69年。
? 工作節(jié)點(diǎn)ID(10位):用于標(biāo)識(shí)不同的ID生成器實(shí)例,最多支持1024個(gè)節(jié)點(diǎn)。
? 序列號(hào)(12位):同一毫秒內(nèi)產(chǎn)生的遞增序列,每毫秒最多生成4096個(gè)ID。
Snowflake的優(yōu)勢(shì):
? 本地生成:無(wú)需中心化協(xié)調(diào),性能極高。
? 大致遞增:由于高位是時(shí)間戳,生成的ID整體上是隨時(shí)間遞增的。
? 長(zhǎng)度合適:64位Long型,存儲(chǔ)和索引效率高。
然而,原生Snowflake在“抗網(wǎng)絡(luò)分區(qū)”方面存在缺陷:
? 工作節(jié)點(diǎn)ID分配:如何為1024個(gè)節(jié)點(diǎn)分配唯一的ID?如果使用一個(gè)中心化的配置服務(wù)(如ZooKeeper、Etcd)來(lái)分配,那么這個(gè)配置服務(wù)本身就成為了單點(diǎn),在網(wǎng)絡(luò)分區(qū)時(shí),新上線的節(jié)點(diǎn)可能無(wú)法獲取到節(jié)點(diǎn)ID,導(dǎo)致服務(wù)不可用。
三、 高可用與抗網(wǎng)絡(luò)分區(qū)的深度設(shè)計(jì)
為了解決原生Snowflake的痛點(diǎn),我們?cè)O(shè)計(jì)一個(gè)改進(jìn)版的、能夠抵御網(wǎng)絡(luò)分區(qū)的架構(gòu)。其核心思想是:弱化中心化依賴,引入“分段號(hào)”與“動(dòng)態(tài)配置”。
1. 架構(gòu)總覽
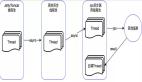
系統(tǒng)由三部分組成:
? ID生成器(Leaf-Server):無(wú)狀態(tài)服務(wù),直接對(duì)外提供生成ID的API。每個(gè)生成器都持有一個(gè)或多個(gè)“號(hào)段”。
? 配置中心(Config Center):一個(gè)高可用的集群(如基于Raft的Etcd集群),用于持久化和管理號(hào)段分配信息。它在正常運(yùn)行時(shí)提供服務(wù),但在網(wǎng)絡(luò)分區(qū)時(shí)允許系統(tǒng)降級(jí)。
? 監(jiān)控與協(xié)調(diào)器(Coordinator):負(fù)責(zé)監(jiān)控ID生成器的狀態(tài)和號(hào)段消耗速度,并在必要時(shí)觸發(fā)號(hào)段預(yù)分配。
2. 核心設(shè)計(jì):號(hào)段(Segment)緩沖機(jī)制
我們不讓每個(gè)ID生成器每次請(qǐng)求都去訪問(wèn)配置中心,而是采用“號(hào)段”預(yù)加載的方式。這是一種“空間換時(shí)間”和“降低依賴”的策略。
? 工作原理:
1) 系統(tǒng)啟動(dòng)時(shí),將一個(gè)足夠大的ID范圍(例如,[0, 1_000_000))定義為一個(gè)“號(hào)段”,并將其狀態(tài)標(biāo)記為“可用”。
2) 一個(gè)ID生成器(Leaf-Server)在啟動(dòng)或需要新號(hào)段時(shí),向配置中心申請(qǐng)一個(gè)可用的號(hào)段。
3)配置中心分配號(hào)段 [0, 1_000_000) 給該生成器,并將該號(hào)段狀態(tài)更新為“已分配”,同時(shí)分配下一個(gè)可用號(hào)段 [1_000_000, 2_000_000) 為“可用”。
4) ID生成器將獲取到的號(hào)段 [0, 1_000_000)緩存在本地內(nèi)存中。
5)當(dāng)應(yīng)用請(qǐng)求ID時(shí),生成器直接從本地內(nèi)存中以原子操作(如 AtomicLong.incrementAndGet())遞增并返回ID,性能極高(每秒可達(dá)千萬(wàn)級(jí))。
6) 當(dāng)本地號(hào)段消耗到一定閾值(如10%)時(shí),生成器異步地、非阻塞地向配置中心申請(qǐng)下一個(gè)號(hào)段。這樣,在當(dāng)前號(hào)段用完之前,新的號(hào)段已經(jīng)準(zhǔn)備就緒,實(shí)現(xiàn)了無(wú)縫切換。
3. 抗網(wǎng)絡(luò)分區(qū)的關(guān)鍵策略
號(hào)段緩沖機(jī)制本身已經(jīng)大大降低了對(duì)配置中心的依賴。但為了應(yīng)對(duì)配置中心完全不可用(如發(fā)生網(wǎng)絡(luò)分區(qū))的極端情況,我們還需要以下設(shè)計(jì):
? 降級(jí)與本地續(xù)期:
每個(gè)ID生成器在從配置中心獲取號(hào)段時(shí),除了號(hào)段范圍 [start, end),還會(huì)獲取一個(gè) “續(xù)期令牌” 和 “最大續(xù)期偏移量”。
當(dāng)配置中心不可用時(shí),如果生成器的本地號(hào)段即將用完,它不會(huì)傻等配置中心恢復(fù),而是進(jìn)入 “降級(jí)模式”。
在降級(jí)模式下,生成器可以根據(jù)預(yù)設(shè)的規(guī)則(如每次擴(kuò)展相同步長(zhǎng) step = end - start)和“最大續(xù)期偏移量”的限制,在本地自行擴(kuò)展新的號(hào)段。
例如,原始號(hào)段是 [0, 1_000_000),步長(zhǎng)為100萬(wàn),最大續(xù)期偏移量為10(即最多可自行擴(kuò)展10次)。當(dāng)需要續(xù)期時(shí),生成器就在本地將號(hào)段擴(kuò)展到 [1_000_000, 2_000_000),并更新本地令牌狀態(tài)。
這個(gè)“最大續(xù)期偏移量”是為了防止在網(wǎng)絡(luò)分區(qū)恢復(fù)后,不同生成器因自行擴(kuò)展而產(chǎn)生號(hào)段重疊。它限定了降級(jí)模式下自主權(quán)的邊界。
? 分區(qū)恢復(fù)與協(xié)調(diào):
當(dāng)網(wǎng)絡(luò)分區(qū)恢復(fù),配置中心重新可用后,配置中心會(huì)進(jìn)入一個(gè)“協(xié)調(diào)狀態(tài)”。
它會(huì)向所有ID生成器收集其在降級(jí)期間自行分配的號(hào)段信息。
配置中心通過(guò)一個(gè)協(xié)調(diào)算法(例如,以最早報(bào)告的那個(gè)生成器的擴(kuò)展記錄為基準(zhǔn),對(duì)其他沖突的號(hào)段進(jìn)行“平移”或標(biāo)記廢棄),最終確保全局號(hào)段分配的連續(xù)性和一致性。
這個(gè)過(guò)程中可能會(huì)產(chǎn)生少量的ID“空洞”(即被廢棄的號(hào)段),但這完全符合我們“非連續(xù)”的要求,是可接受的。
4. 確保全局遞增
在上述架構(gòu)中,全局遞增性是如何保證的呢?
? 號(hào)段層面遞增:配置中心是分配號(hào)段的唯一權(quán)威(在非降級(jí)模式下)。它通過(guò)一個(gè)持久化的全局游標(biāo)來(lái)確保每次分配的號(hào)段起點(diǎn)都比上一次大。
? 生成器內(nèi)部遞增:每個(gè)ID生成器在本地使用原子操作消耗號(hào)段,保證了單個(gè)號(hào)段內(nèi)ID的連續(xù)性。
? 時(shí)間戳作為兜底:為了進(jìn)一步增強(qiáng)對(duì)極端情況的容忍度,我們可以在ID結(jié)構(gòu)的高位保留時(shí)間戳。即使號(hào)段分配在極端協(xié)調(diào)下出現(xiàn)小范圍不連續(xù),但由于高位時(shí)間戳的存在,ID的總體趨勢(shì)依然是遞增的。一個(gè)改進(jìn)的ID結(jié)構(gòu)可以是:
| 42位時(shí)間戳(毫秒) | 12位工作節(jié)點(diǎn)ID | 10位序列號(hào) |這里的“序列號(hào)”實(shí)際上就是本地號(hào)段內(nèi)的自增序列。這種結(jié)構(gòu)保證了“同一毫秒內(nèi),同一節(jié)點(diǎn)生成的ID是遞增的”,而跨節(jié)點(diǎn)、跨毫秒的ID則由時(shí)間戳保證大體的遞增順序。
四、 技術(shù)細(xì)節(jié)與運(yùn)維實(shí)踐
1. 性能與伸縮性
? 水平擴(kuò)展:ID生成器(Leaf-Server)是無(wú)狀態(tài)的,可以通過(guò)簡(jiǎn)單地增加實(shí)例數(shù)量來(lái)水平擴(kuò)展。負(fù)載均衡器(如Nginx、Kubernetes Service)將請(qǐng)求分發(fā)到不同的生成器。
? 吞吐量:由于ID生成主要在本地內(nèi)存中完成,單機(jī)QPS可達(dá)數(shù)十萬(wàn)甚至百萬(wàn)級(jí)。每日1億的請(qǐng)求量對(duì)這套架構(gòu)來(lái)說(shuō)壓力很小。
? 號(hào)段大小:號(hào)段大小(step)是需要權(quán)衡的參數(shù)。設(shè)置過(guò)大,會(huì)導(dǎo)致在應(yīng)用重啟時(shí)浪費(fèi)大量ID;設(shè)置過(guò)小,會(huì)增加與配置中心交互的頻率。根據(jù)每日1億的量級(jí),假設(shè)每個(gè)號(hào)段服務(wù)10分鐘,那么號(hào)段大小可設(shè)置為約 100,000,000 / (24*6) ≈ 700,000。我們可以設(shè)置為100萬(wàn),這樣既方便計(jì)算,也為流量峰值提供了緩沖。
2. 容災(zāi)與數(shù)據(jù)持久化
? 配置中心:使用Etcd或ZooKeeper集群,通過(guò)Raft協(xié)議保證配置信息(當(dāng)前全局游標(biāo)、已分配的號(hào)段)的強(qiáng)一致性和持久化。即使少數(shù)節(jié)點(diǎn)宕機(jī),集群仍可正常服務(wù)。
? ID生成器:在降級(jí)模式下自行擴(kuò)展號(hào)段時(shí),應(yīng)將擴(kuò)展決策(如新的號(hào)段起點(diǎn))寫(xiě)入本地磁盤(pán)。這樣即使在降級(jí)期間進(jìn)程重啟,也能知道自己所處的號(hào)段位置,避免重復(fù)發(fā)號(hào)。
3. 監(jiān)控與告警
? 監(jiān)控指標(biāo):
每個(gè)ID生成器的本地號(hào)段剩余量。
配置中心的連接狀態(tài)和請(qǐng)求延遲。
全局ID消耗速度。
系統(tǒng)是否進(jìn)入降級(jí)模式。
? 告警策略:
當(dāng)某個(gè)生成器的號(hào)段剩余量低于閾值時(shí),發(fā)出預(yù)警。
當(dāng)配置中心不可用時(shí),發(fā)出嚴(yán)重告警,提示運(yùn)維人員介入。
當(dāng)有生成器進(jìn)入降級(jí)模式時(shí),發(fā)出告警,提醒關(guān)注網(wǎng)絡(luò)分區(qū)風(fēng)險(xiǎn)。
五、 總結(jié)
設(shè)計(jì)一個(gè)每日億級(jí)請(qǐng)求、抗網(wǎng)絡(luò)分區(qū)的全局遞增ID系統(tǒng),是一項(xiàng)在CAP定理的約束下尋求最佳實(shí)踐的藝術(shù)。我們通過(guò)融合并改進(jìn)雪花算法與號(hào)段緩沖機(jī)制,構(gòu)建了一個(gè)高性能、高可用的解決方案。
其核心精髓在于:
1. 解耦與緩沖:通過(guò)號(hào)段預(yù)加載,將中心化協(xié)調(diào)的頻率降至最低,實(shí)現(xiàn)了高性能和高可用。
2. 優(yōu)雅降級(jí):通過(guò)“本地續(xù)期”機(jī)制,在網(wǎng)絡(luò)分區(qū)這種不可避免的故障發(fā)生時(shí),系統(tǒng)能犧牲部分管理性(嚴(yán)格的一致性)來(lái)保證核心功能(發(fā)號(hào))的可用性。
3. 智能協(xié)調(diào):在網(wǎng)絡(luò)恢復(fù)后,通過(guò)協(xié)調(diào)機(jī)制清理“戰(zhàn)場(chǎng)”,最大限度地恢復(fù)秩序,并將副作用(ID空洞)控制在可接受的范圍內(nèi)。
這套架構(gòu)不僅是ID生成的解決方案,其背后所體現(xiàn)的設(shè)計(jì)思想——弱化中心依賴、允許有損服務(wù)、最終一致性協(xié)調(diào)——對(duì)于構(gòu)建任何需要抵御網(wǎng)絡(luò)分區(qū)的分布式核心服務(wù),都具有極高的參考價(jià)值。它正是構(gòu)筑數(shù)字世界堅(jiān)實(shí)基石的工程智慧所在。