首次實現第一視角視頻與人體動作同步生成!新框架攻克視角-動作對齊兩大技術壁壘
AI生成第三視角視頻已經駕輕就熟,但第一視角生成卻仍然“不熟”。
為此,新加坡國立大學、南洋理工大學、香港科技大學與上海人工智能實驗室聯合發布EgoTwin ,首次實現了第一視角視頻與人體動作的聯合生成。
一舉攻克了視角-動作對齊與因果耦合兩大瓶頸,為可穿戴計算、AR及具身智能打開落地新入口。
 圖片
圖片
EgoTwin 是一個基于擴散模型的框架,能夠以視角一致且因果連貫的方式聯合生成第一人稱視角視頻和人體動作。
生成的視頻可以通過從人體動作推導出的相機位姿,借助 3D 高斯點渲染(3D Gaussian Splatting)提升到三維場景中。
 圖片
圖片
下面具體來看。
第一視角視頻與人體動作同步生成
核心挑戰:第一視角生成的“兩難困境”
第一視角視頻的本質是人體動作驅動的視覺記錄——頭部運動決定相機的位置與朝向,全身動作則影響身體姿態與周圍場景變化。
二者之間存在內在的耦合關系,無法被單獨分離。傳統視頻生成方法難以適配這一特性,主要面臨兩大難題:
- 視角對齊難題生成視頻中的相機軌跡,必須與人體動作推導的頭部軌跡精準匹配。但現有方法多依賴預設相機參數生成視頻,而第一視角的相機軌跡并非外部給定,而是由穿戴者頭部動作內生決定,需要二者同步生成以保證對齊。
- 因果交互難題每一時序的視覺畫面為人體動作提供空間上下文(如“看到門把手”引導伸手動作),而新生成的動作又會改變后續視覺幀(如“開門”導致門的狀態與相機朝向變化)。這種“觀察-動作”的閉環依賴,要求模型捕捉二者隨時間的因果關聯。
三大創新破解核心難題
 圖片
圖片
△EgoTwin能同時生成“第一視角的場景視頻”和“匹配的人體動作”
為解決上述挑戰,EgoTwin基于擴散Transformer架構,構建了“文本-視頻-動作”三模態的聯合生成框架,通過三大關鍵設計實現突破兩大難題。
三通道架構是指動作分支僅覆蓋文本與視頻分支下半部分的層數。
每個通道均配備獨立的tokenizer與Transformer模塊,并以相同顏色標示跨通道共享的權重。
 圖片
圖片
下圖展示了“文本-視頻-動作”三個模態的雙向因果注意力交互機制。
 圖片
圖片
創新1:以頭部為中心的動作表征,讓視角對齊“一目了然”
傳統人體動作表征以身體根部為中心,頭部姿態需通過人體運動學計算推導,容易造成誤差累計。
EgoTwin提出以頭部為中心的動作表征,直接將動作錨定在頭部關節,實現與第一視角觀測精準對齊:
- 明確包含頭部絕對/相對位置(
 ,
, )與旋轉角度(
)與旋轉角度( ,
, ),其他關節的位置與速度(
),其他關節的位置與速度( )則基于頭部坐標系定義;
)則基于頭部坐標系定義; - 初始幀頭部姿態歸一化為“零平移+單位旋轉”,讓相機視角與頭部動作的對應關系更直接,無需額外復雜計算。實驗證明,相比傳統表征,該設計使頭部姿態回歸誤差顯著降低,為視角對齊奠定基礎。
創新2:控制論啟發的交互機制,捕捉因果關聯“動態閉環”
借鑒控制論中“觀察-動作”反饋循環原理,EgoTwin在注意力機制中加入結構化掩碼,實現了視頻與動作之間的雙向因果交互:
- 視頻 tokens 僅關注前序動作 tokens:體現“當前視覺畫面由過去動作產生”;
- 動作 tokens 同時關注當前與后續視頻 tokens:實現“基于場景變化推斷動作”;
- 初始姿態與初始視覺幀允許雙向注意力,保證生成序列的起點一致性。
這種設計避免了“全局一致但幀級錯位”的問題,實現細粒度時序同步。
創新3:視頻動作聯合的異步擴散訓練框架,平衡效率與生成質量
考慮到視頻與動作的模態差異(如動作采樣率通常是視頻的2倍),EgoTwin采用異步擴散訓練策略:為視頻與動作分支分別設置獨立采樣時間步、添加高斯噪聲,再通過統一時間步嵌入融合,適配不同模態的演化節奏。
同時,框架采用三階段訓練范式,兼顧效率與性能:
- 動作VAE預訓練:單獨訓練動作變分自編碼器,通過重構損失與KL散度正則化,確保動作表征的有效性;
- 文本-動作預訓練:凍結文本分支(保留預訓練文本理解能力),僅訓練動作分支,加速模型收斂;
- 三模態聯合訓練:加入視頻分支,學習文本條件下視頻與動作的聯合分布,支持多種生成任務。
實驗驗證:性能全面超越基線
模型能夠根據文字和視頻生成動作,或者根據文字和動作生成視頻,甚至能把生成的視頻和動作變成3D場景(比如還原出房間的 3D 結構,再把人的動作放進去)。
首先看一下可視化結果。
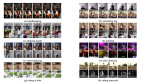
 △基于文本聯合生成視頻和動作
△基于文本聯合生成視頻和動作
EgoTwin還支持根據動作和文本生成視頻(TM2V)、根據文本和視頻生成動作(TV2M)額外二種生成模式。
 △基于文本和動作聯合生成視頻
△基于文本和動作聯合生成視頻
 △基于文本和視頻聯合生成動作
△基于文本和視頻聯合生成動作
為客觀評估,團隊還從數據、指標、結果三方面系統展開測試。
 圖片
圖片
實驗證明,EgoTwin比之前的基礎模型好很多:視頻和動作的匹配度更高,比如鏡頭和頭部的位置誤差變小了,手的動作在視頻里也更容易對應上;
 圖片
圖片
消融實驗進一步驗證了核心設計的必要性:移除以頭部為中心的動作表征、因果交互機制或異步擴散訓練策略后,模型性能均出現明顯下降,證明三大創新缺一不可。
 圖片
圖片
EgoTwin不僅顯著縮小了跨模態誤差,也為可穿戴交互、AR 內容創作、具身智能體仿真等應用提供了可直接落地的生成基座。
感興趣的朋友可戳下方鏈接了解更多具體內容~
論文地址:https://arxiv.org/abs/2508.13013項目主頁與示例:https://egotwin.pages.dev