剛剛,谷歌發布機器人最新「大腦」模型!思考能力SOTA,還能「跨物種」學習
谷歌又給機器人「換大腦」了!
剛剛,DeepMind發布了針對機器人和具身智能的Gemini Robotics 1.5系列家族模型,專為機器人和具身智能打造的新一代「大腦」。
Gemini Robotics 1.5系列包括Gemini Robotics 1.5和Gemini Robotics-ER 1.5。
- Gemini Robotics 1.5,最先進的視覺-語言-行動模型,能將視覺信息和指令轉化為機器人的運動指令以執行任務。
- Gemini Robotics-ER 1.5,最強大的視覺-語言模型,能夠對物理世界進行推理,直接調用數字工具,并創建詳細的多步驟計劃來完成任務。
它們結合在一起,就構建出一個強大的智能體框架。

在下面這個1分40秒的視頻,谷歌的研究科學家讓兩個機器人完成了兩個不同任務。

第一個任務是垃圾分類。
請Aloha根據舊金山的垃圾分類標準,把物品分到堆肥(綠桶)、回收(藍桶)和垃圾(黑桶)里。
Aloha通過查閱規則并觀察物品,完成了分類任務。
第二個任務是打包行李。
請Apollo幫忙打包去倫敦旅行的行李,并放入針織帽。
Apollo還主動查詢天氣,提醒倫敦多天會下雨,并貼心地把雨傘也放進包里。
整體看下來,在最新系列模型的加持下,現在機器人已經越來越有科幻電影里的那味了!
為實體任務開啟智能體體驗
想象一下,一個機器人不僅能看懂你家客廳的雜物,還能規劃、思考并親手收拾干凈。
Gemini Robotics 1.5正是朝這個目標邁出的關鍵一步。
它讓機器人具備「思考后行動」的能力,能在復雜環境中像人類一樣理解、推理并完成多步驟任務。
這一突破,有望打開通用機器人的新時代。
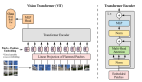
Gemini Robotics-ER 1.5擅長在物理環境中進行規劃與邏輯決策,擁有頂尖的空間理解能力,支持自然語言交互,可評估任務成功率與進度,并能直接調用谷歌搜索等工具獲取信息或使用任何第三方用戶自定義功能。

隨后,Gemini Robotics-ER 1.5會為Gemini Robotics 1.5提供每一步的自然語言指令,后者則運用其視覺與語言理解能力直接執行具體動作。
Gemini Robotics 1.5還能協助機器人反思自身行為,以更好地解決語義復雜的任務,甚至能用自然語言解釋其思考過程——這讓它的決策更加透明。
這兩款模型均基于核心Gemini模型家族構建,并通過不同數據集進行微調以專精于各自職能。
當它們協同工作時,可顯著提升機器人對長周期任務和多樣化環境的泛化能力。
先理解「環境」再「行動」
Gemini Robotics-ER 1.5是首個為具身推理優化的思維模型。
它在學術和內部基準測試中均實現了最先進的性能表現。

下面展示了Gemini Robotics-ER 1.5的部分能力,包括物體檢測與狀態估計、分割掩碼、指向識別、軌跡預測以及任務進度評估與成功檢測。

三「思」而后「行」
傳統上,視覺-語言-動作模型直接將指令或語言規劃轉化為機器人的運動。
但Gemini Robotics 1.5不僅能翻譯指令或規劃,如今還能在行動前進行思考。
這意味著它能以自然語言生成內部推理與分析序列,從而執行需要多步驟或更深層語義理解的任務。
在下面這段3分40秒的視頻,谷歌的科學家展示了機器人如何去完成更復雜的任務。

比如第一段將不同顏色的水果分類放到對應的盤子里。機器人需要能感知環境、分析顏色并逐步完成動作。
第二段Apollo被要求幫助分類洗衣物和打包物品。它能自主思考并在執行中展現出鏈式任務規劃與反應能力,例如調整籃子來更好地撿起衣物,或對臨時變化作出即時反應。
跨越不同形態的具身機器人學習
機器人形態各異、大小不一,具備不同的感知能力和自由度,這使得將從一個機器人學到的動作遷移到另一個機器人變得困難。
Gemini Robotics 1.5展現出卓越的跨具身學習能力。
它能將從一個機器人學到的動作遷移到另一個機器人,無需針對每種新形態專門調整模型。
這一突破加速了新行為的學習進程,助力機器人變得更智能、更實用。
在下面這段2分鐘的視頻里,谷歌科學家展示了不同「物種」機器人之間如何泛化學習。

在Gemini Robotics 1.5中,一個模型可以跨多個機器人使用。
比如Aloha在衣柜場景中已有經驗,而Apollo從未見過,卻能通過遷移學習完成開門、拿衣服等全新動作。
這展示了「跨具身學習」的潛力。
未來,不同場景中的機器人(如物流、零售)可互相學習,從而大大加快通用機器人研發的進程。