AniSoraV3 正式開源,長視頻創作智能體框架AniME技術揭秘
引言
在動畫制作領域,傳統流程復雜且勞動強度大,涵蓋劇本創作、分鏡設計、角色與場景設計、動畫制作、配音以及最終剪輯等多個創作階段。這一過程不僅需要大量專業人員參與,還要求不同團隊間緊密協作,導致成本高昂、制作周期漫長。
近年來,生成式人工智能取得了顯著進展,例如用于動畫生成的 AniSora 等基礎模型,在特定任務中展現出了令人印象深刻的能力。然而,這些方法在特定領域各有優劣,在智能體驅動的視頻生成中,難以維持一致性且精細可控性欠佳。因此,開發一個全自動的長篇動畫生成系統仍是一項亟待解決的挑戰,尤其是在選擇合適的控制條件以及確保跨階段內容一致性方面。
為此,我們提出 AniME,一種導演驅動的多智能體框架。該框架通過引入定制化模型選擇MCP機制,為不同環節的專用智能體配置定制化工具箱,實現了任務分解、跨階段一致性控制以及迭代式反饋優化。AniME 借鑒真實動畫工作室的生產流程,強調全局調度與質量控制,使長篇動畫的自動化生成成為可能。
All In One模型AniSora V3開源
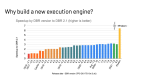
在介紹AniME工作流前,先介紹一下團隊近期開源的動畫視頻生成模型AniSora V3. 此前AniSora已經發布了2個版本的模型,在國內外社區中獲得了比較好的口碑和反饋。本次,V3版本有了比較大的升級,量化版本支持單卡4090推理,單臺4卡4090生成5秒360p視頻僅需30秒,單臺8卡A800僅需8秒。
V3版本除了在動態性、畫面美感、指令遵從等方面進行了增強外,還結合動畫制作實際流程中的相關訴求,增加了多種模態的交互能力,更加貼合動畫制作流程本身,為長視頻創作提供了有力支撐。
角色單張正面立繪生成360度視頻
 圖片
圖片
 圖片
圖片
 圖片
圖片
任意幀引導
該功能在V1版本中已經支持,V3版本中該功能的指令遵從性得到了進一步增強
可以通過首幀、尾幀或任意中間幀,根據劇情生成視頻
風格轉繪
輸入視頻
|
線稿提取
|
風格化
|



多模態引導
首幀+多模態輸入 |
The boy in red and the girl in red are fencing in the scene. |
輸出視頻 |
|
首幀+多模態輸入 |
A worn-out red robot flings its arm away, only to have it fly back and reassemble with a new arm holding a sword. |
輸出視頻 |
|
首幀+audio |
|
輸出視頻 |
|








極低分辨率超分
支持90p到720p/1080p的超分,可以用更少的抽卡時間,生成細節更豐富的視頻:
輸入 |
|
1080 |
|
GT |
|



AniSora為動畫視頻創作提供了多種交互功能,但它只能生成單個鏡頭。我們通過AniME組織整體工作流程,實現長視頻的創作。
AniME 架構
AniME 將從故事到視頻的任務分解為多個層級階段,由導演智能體(Director Agent)統籌調度,多個專用智能體(Specialized Agents)協同完成,系統架構如圖1所示。每個智能體 Ai 都有明確的輸入類型 Ii 、輸出類型 Oi 以及本地的模型上下文協議(MCP)工具箱 ,智能體之間通過結構化 JSON 消息進行交互。
 圖片 1 AniME架構圖
圖片 1 AniME架構圖
導演智能體與多智能體協作流程
導演智能體是 AniME 框架的中央控制器,負責管理全局工作流程和質量保證。它將輸入的故事分解為任務工作流,為各個智能體分配子任務,檢查每個專業智能體的工作質量,并維護一個全局資產記憶庫(Asset Memory Bank)存儲統一的角色、場景、風格等資產,保證跨鏡頭一致性。
1. 導演工作流程:給定一個長篇故事 R,導演通過分割過程將其按層級分解為場景和鏡頭,并確定視覺風格 Sv 和聲學設置風格 Sa 。隨后,利用鏈式思維提示生成初始任務列表 T,每個任務都按照下游智能體的格式明確規定了輸入 / 輸出規格。導演還維護著一個工作流圖 W=(N,E),其中每個節點 n∈N對應一個制作任務,邊 E則編碼了明確的依賴關系。 具體算法流程如圖2所示
 圖片 2 AniME多智能體協作算法流程圖
圖片 2 AniME多智能體協作算法流程圖
2. 資產記憶管理:資產記憶庫存儲經過導演審批后的資產,確保整個流程中的一致性和可重用性。每個表格都可查詢、有版本控制,能夠通過語義相似性進行檢索。角色表格不僅存儲參考圖像,還存儲參考風格和聲音樣例,以確保動畫保持視覺保真度。 為防止偏差,導演保持對全局資產的單一寫入權限,同時允許下游專家智能體進行讀取訪問。
專業智能體與模型選擇MCP 機制
AniME 參考真實動畫制作流程,對應一個創作階段設計了專業智能體。每個專業智能體都利用專用的 MCP模型工具箱,可以根據任務需求自適應地選擇模型。
專業智能體
劇本和分鏡智能體(Script and Storyboard Agent):該智能體將敘事文本轉換為時間序列的鏡頭,主要執行三個關鍵步驟:一是利用LLM解析將文本分割為場景和鏡頭;二是進行相機規劃,包括鏡頭類型、軌跡和過渡方式;三是進行參考素材檢索,通過一系列條件生圖模型生成關鍵幀。該智能體可根據需求在多種工具中自適應選擇。其中文本到圖像工具適用于空的定場鏡頭,雖簡單快速但布局控制有限;參考圖像生成工具能維持角色身份一致性,適用于以對話為中心的面板,但無法生成空的定場鏡頭;布局引導生成工具則適用于精確的多角色或物體密集型面板,構圖準確但計算成本較高。此外,基于大型語言模型(LLM)的分割、相機規劃和布局規劃模塊負責協調鏡頭級別的結構。
角色智能體(Character Designer):從文本描述和風格向量出發,通過文生圖模型生成角色的多視角圖像。角色參考圖包括多個視角,確保側面和背面輪廓與標準正面視圖匹配。 在工具選擇上,該智能體主要利用參考圖像生成來確保一致的角色身份,多視角合成和超分模塊則用于確保多角度一致性和圖像清晰度。
場景智能體(Scene Designer):負責生成故事拍攝環境和背景,其輸出包括可在多個場景中重用的分層資產。 工具選擇方面,場景智能體優先采用布局引導生成來實現精確的物體放置,采用深度引導圖像生成來創建空間連貫的場景,采用重新照明模型來維持時間上的照明一致性。文本到圖像工具可選擇性地生成廣泛的定場鏡頭,但對構圖的控制較少。
動畫師(Animator):從關鍵幀、姿勢和相機軌跡合成運動序列,主要使用關鍵幀 / 音頻 / 姿勢 / 相機條件視頻生成模型。對于語音驅動的情景,該智能體將關鍵幀條件視頻擴散與音頻驅動的嘴唇同步相結合。為了維持時間連貫性,可以使用光流引導和運動插值。 對于無語音場景,該智能體主要通過首、尾幀驅動的視頻生成模型來生成片段。
音頻制作智能體(Audio Production Agent):管理對話、音效和音樂。它采用說話人條件的文本轉語音(TTS)生成特定角色的聲音。背景音樂通過文本到音樂生成來創作,然后由音頻混合器平衡語音、音樂和音效。 此智能體在說話人條件的 TTS、文本到音樂生成和音頻混合器程序中進行選擇。
視頻編輯智能體(Video Editor Agent):將所有資產整合為連貫的最終視頻。自動化編輯工具會設計剪輯和過渡效果,通過 FFmpeg 的多遍編碼生成最終視頻。在此階段支持人機交互式操作,以進行精細調整。
質量評估智能體(Quality Evaluator Agent):運用多種多模態評分模型對各個環節的效果進行打分。文本到視頻相似性評分、身份驗證、視聽內容對齊,使用視覺語言模型(VLM)進行敘事一致性評估,并且對視頻進行抽幀,進行身份驗證以防止ID偏移。確保生成的序列符合預期的故事情節。導演智能體會根據評估分數決定下游智能體的任務是否需要重新進行。
模型選擇MCP機制
在 AniME 中,模型上下文協議(MCP)使專業智能體能夠根據導演提供的上下文自主選擇和調用最適合其任務的工具。例如,當導演向分鏡智能體發送場景描述后,劇本和分鏡智能體首先生成分鏡描述并選擇圖像生成工具,為每個鏡頭生成包含所選工具、提示、參考和注釋的結構化 JSON 輸出。通過 MCP,分鏡智能體能夠根據任務需求和場景上下文調整其工具選擇,無需人工干預即可高效、高質量地生成分鏡。導演的作用仍然是提供高級別的場景上下文,而 MCP 則管理專業智能體如何在內部協調其工具。 表1展示了對于導演智能體切分的場景片段,Script & Storyboard 智能體創作各個分鏡時的生圖工具選擇過程。其生成條件的選擇由場景的構圖、一致性需求進行決策。
a) scene_YX01_shot_01 |
|
{ "shot_id":"scene_YX01_shot_01", "tool":"reference_image_generation", "prompt": "Ye holding a blue-and-white porcelain cup, tilting head to drink", "reference_images":["assets/char_YX_front.png"] } |
b) scene_YX01_shot_02 |
|
{ "shot_id":"scene_YX01_shot_02", "tool":"layout_guided_generation", "prompt":"System AI angrily stopping Ye", "layout_bboxes":[ { "object":"Ye Xuan", "bbox":[100,300,400,900] }, { "object":"System AI", "bbox":[600,350,900,850], } ] } |
c) scene_YX01_shot_03 |
|
{ "shot_id":"scene_YX01_shot_03", "tool":"reference_image_generation", "prompt":"Close-up of Ye's facial expression reacting to AI", reference_images":["assets/char_YX_front.png"] } |



表格 1 StoryBoard Agent的自動分鏡示例:“在玄夜的修煉室里,他雙手捧起青花瓷杯仰頭欲飲,人工智能氣急敗壞地阻止他,叫他快停下。”
借助這一機制以及各智能體的協同工作,AniME 能夠順利完成從故事腳本到最終視頻的生成流程,各環節銜接緊密,有效保障了生成內容的質量與一致性。
效果
AniME的多智能體協作已經用于內部的端到端動漫內容生成。例如對于小說片段:“一位算命先生曾說我生日那天會走大運,一飛沖天。可沒想到,那天我居然被車撞了……然后直接被吸進了一個超級吞噬系統。在這個系統里,我叫玄夜,是個氣海被毀的倒霉蛋,而且馬上就要被天元宗圣女休夫了。” AniME各模塊的工作流程及輸出如示意圖2所示。通過各智能體協作,該片段可以自動化轉換為長動畫視頻片段。

最終視頻效果如下:https://www.bilibili.com/video/BV1ipt1zGEj5
總結
本文提出了 AniME,一個導演驅動的多智能體長篇動畫生成框架。通過引入模型選擇MCP 機制,使不同智能體能夠自主選擇最優生成方式,實現了從文本故事到最終視頻的全流程自動化。AniME 在保證風格一致性、角色身份保持和跨場景敘事連貫性方面展現出強大能力,推動了生成式 AI 在長篇動畫制作中的落地。
參考文獻
1. Anthropic. 2024. Introducing the Model Context Protocol. Retrieved Aug 18, 2024 from http://www.anthropic.com/news/model-context-protocol
2. Chenpeng Du, Yiwei Guo, Hankun Wang, et al . 2025. Vall-t: Decoder-only generative transducer for robust and decoding-controllable text-to-speech. In ICASSP.
3. Yudong Jiang, Baohan Xu, Siqian Yang, et al . 2024. Anisora: Exploring the frontiers of animation video generation in the sora era. arXiv:2412.10255 (2024).
4. Yunxin Li, Haoyuan Shi, Baotian Hu, et al . 2024. Anim-director: A large multimodal model powered agent for controllable animation video generation. In SIGGRAPH Asia.
5. Navonil Majumder, Chia-Yu Hung, Deepanway Ghosal, et al . 2024. Tango 2: Aligning-based text-to-audio generations through direct preference optimization. In ACM MM.
6. Haoyuan Shi, Yunxin Li, Xinyu Chen, et al. 2025. AniMaker: Automated Multi-Agent Animated Storytelling with MCTS-Driven Clip Generation. arXiv:2506.10540 (2025).
7. Weijia Wu, Zeyu Zhu, and Mike Zheng Shou. 2025. Automated movie generation via multi-agent cot planning. arXiv:2503.07314 (2025).
8. Haotian Xia, Hao Peng, Yunjia Qi, et al. 2025. StoryWriter: A Multi-Agent Framework for Long Story Generation. arXiv:2506.16445 (2025).
9. Ling Yang, Zhaochen Yu, Chenlin Meng, et al. 2024. Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs. In ICML.