數據庫分類已成過去:未來趨勢前瞻
數據庫分類已過時,現代數據庫融合為通用平臺,可處理多種工作負載。這消除了數據同步、簡化查詢語言和操作模型,并保證事務一致性。多語言持久性在數據庫有硬性限制時有意義,但現在通用平臺性能提升,其必要性降低。
譯自:Database Categories Are Dead: Here's What’s Next[1]
作者:Jesse Hall
傳統的數據庫分類方式已經過時。我們十多年來使用的諸如“NoSQL”、“關系型”、“文檔”、“鍵值”和“圖”等標簽,已不再能描述現代數據庫[2]的工作方式或開發者實際的需求。
這不僅僅是語義上的轉變。創建這些類別的基本假設已經改變。現代應用程序不適合放入整齊的數據庫類別中,為它們提供支持的系統也不應該這樣。
分類的陷阱
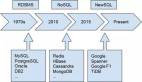
數據庫類別的出現源于真正的技術限制。在 2000 年代初期,你面臨著明確的權衡:
? 關系型數據庫提供 ACID 事務[3]和結構化查詢,但在規模和模式演變方面表現不佳。
? 文檔存儲提供靈活的模式和橫向擴展,但缺乏事務和復雜的查詢。
? 鍵值存儲提供原始性能,但查詢能力有限。
? 圖數據庫[4]擅長處理關系,但在其他訪問模式下表現不佳。
這些權衡迫使在開發早期做出架構決策。選擇你的毒藥:一致性或規模,靈活性或結構,性能或功能。
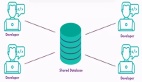
結果是多語言持久性——為同一應用程序的不同部分使用多個數據庫。一個典型的現代堆棧可能包括 PostgreSQL[5] 用于事務數據,Redis 用于緩存,Elasticsearch 用于搜索,Neo4j 用于推薦,以及 InfluxDB[6] 用于指標。
當系統較小且團隊有時間管理復雜性時,這種方法是可行的。但在今天的開發環境中,它就行不通了。
融合
現代數據庫正在融合到一個不同的架構上:通用平臺,可以處理多種工作負載類型,而無需單獨的系統。
這種融合的發生是因為最初的技術限制消失了。在 2010 年看似奇特的分布式計算技術已成為標準。CAP(一致性、可用性和分區容錯性)定理的權衡看似是根本性的,但通過更好的算法和基礎設施證明是可以協商的。
考慮一下數據庫領域發生了什么:
PostgreSQL 添加了 JSONB 列,使其適用于文檔工作負載。它現在包括全文搜索、時間序列擴展,甚至 向量相似性搜索[7],用于 AI 應用程序。
Redis 擴展到簡單的鍵值操作之外,包括用于搜索、圖處理、JSON 文檔和時間序列數據的模塊。
Apache Cassandra[8] 引入了二級索引、物化視圖和更靈活的數據建模。
甚至像 SQL Server 和 Oracle 這樣的傳統關系數據庫也添加了 JSON 支持、圖功能和 NoSQL 風格的靈活性。
MongoDB 在這種融合中走得最遠。最初作為文檔數據庫,現在它在分布式集群中提供 ACID 事務,由 Apache Lucene 提供支持的全文和向量搜索,以及其他現代功能[9]。
這種模式超越了任何單一供應商。過去五年中最成功的數據庫是那些超越了其原始類別的數據庫。
這對開發者為何重要
這種融合的實際影響是巨大的。現代應用程序可以圍繞能夠處理各種工作負載類型的平臺進行整合,而不是管理多個數據庫系統。
這種整合消除了整個類別的問題:
? 沒有數據同步。當你的用戶資料、會話緩存、搜索索引和分析都位于同一系統中時,你不需要復雜的 ETL(提取、轉換、加載)管道來保持數據一致。
? 統一的查詢語言。開發者學習一種語法,而不是 SQL 加上 Redis 命令加上 Cypher 加上你的搜索引擎使用的任何領域特定語言。
? 單一的操作模型。一種備份策略,一種監控系統,一種擴展方法,一種安全模型。
? 事務一致性。跨多種數據類型的操作可以使用相同的 ACID 保證,從而消除了困擾多語言架構的分布式事務復雜性。
真正的公司正在看到結果。制藥公司正在將臨床報告的生成時間從幾周減少到幾分鐘。金融平臺正在管理數千億美元的資產,同時將擴展性能提高 64%。電子商務網站正在實現亞毫秒級的搜索響應時間,而無需單獨的搜索基礎設施。
多語言持久性的清算
當數據庫有硬性限制時,多語言持久性是有意義的。但當這些限制不再存在時,它就顯得不那么有意義了。
多語言方法假設專業化總是勝過泛化。但專業化是有代價的:運營復雜性、數據一致性挑戰以及管理多個系統的認知開銷。
當性能優勢明顯時,這些成本是可以接受的。當通用平臺在其自身領域中匹配或超過專用系統時,權衡計算就會發生變化。
考慮一下搜索。Elasticsearch 成為全文搜索的默認選擇,因為關系數據庫處理得很差。但是,當 MongoDB 的 Atlas Search 使用與 Elasticsearch 相同的 Apache Lucene 基礎提供亞毫秒級的響應時間時,維護單獨的搜索集群有什么好處?
同樣的邏輯適用于所有數據庫類別。當通用平臺提供與專用向量數據庫相當的向量搜索性能,或與專用系統匹配的時間序列處理時,多個數據庫的架構復雜性變得更難證明是合理的。
引用鏈接
[1] Database Categories Are Dead: Here's What’s Next:https://thenewstack.io/database-categories-are-dead-heres-whats-next/
[2]現代數據庫:https://thenewstack.io/introduction-to-databases/
[3]ACID 事務:https://thenewstack.io/acid-compliant-distributed-sql-enters-the-agentic-ai-era/
[4]圖數據庫:https://thenewstack.io/common-uses-cases-for-graph-databases/
[5]PostgreSQL:https://thenewstack.io/postgresql-18-delivers-significant-performance-gains-for-oltp-and-analytics/
[7]向量相似性搜索:https://thenewstack.io/combining-the-power-of-text-based-keyword-and-vector-search/
[8]Apache Cassandra:https://thenewstack.io/why-apache-cassandra-5-0-is-a-game-changer-for-developers/