同時監督和強化的單階段大模型微調,告別“先背書再刷題”,推理泛化雙提升|中科院&美團等
通過單階段監督微調與強化微調結合,讓大模型在訓練時能同時利用專家演示和自我探索試錯,有效提升大模型推理性能。
中國科學院自動化研究所深度強化學習團隊聯合美團,提出一種單階段監督-強化微調方法——SRFT (Supervised Reinforcement Fine-Tuning)。該方法通過基于熵的動態加權機制,將兩種訓練范式結合。


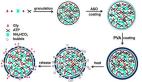
圖注:SRFT方法示意圖,展示了對探索試錯(rollout)數據和演示(demonstration)數據的協同學習,以及平衡監督和強化信號的熵感知策略更新。
在大語言模型(LLM)的推理能力提升上,監督微調(SFT) 和強化學習(RL,有時也稱作強化微調,RFT)是兩條核心技術路線。但它們各自都存在瓶頸:
SFT擅長模仿專家解題思路,類似“背書”,能快速為模型打下基礎,但缺點是容易陷入死記硬背,缺乏在新問題上靈活應用和尋找最優解的能力;
RFT/RL通過不斷試錯來探索解題方法,類似“刷題”,能夠發現更優解法,但其探索過程效率低下,容易面臨模式崩潰風險。
因此,目前研究者通常采用兩階段順序方法SFT→RFT/RL:先用SFT學習高質量數據集,再用RFT/RL進一步優化對齊LLM策略(即先“背完書”再“去刷題”)。
然而,這種串行方式不僅影響學習效率,還常常導致模型在“刷題”時忘了“書本”上的知識,引發知識遺忘等問題,如何讓兩者在同一階段協同作用,做到“邊背邊練”,成為提升 LLM 推理能力的關鍵之一。
結果顯示,SRFT方法能夠同時從高質量演示數據(demonstrations)與LLM自身的探索試錯(rollouts)中學習,在5項數學推理任務中實現59.1%的平均準確率,較zero-RL基線提升9.0% ;在三項分布外任務上取得62.5%的平均準確率,較zero-RL基線提升10.9% ,展現了卓越的泛化能力。

△SRFT與其它算法的性能對比
分析:面向 LLM 推理的 SFT 和 RL
研究團隊首先對SFT與RL在LLM微調中的作用進行了分析,并深入探究了二者結合的有效路徑。
SFT和RL對LLM的作用:大錘vs.手術刀

圖注:LLM 微調前后分布可視化, (a) SFT 與 RL 前后分布改變示例 (b) 在5個數據集上統計了分布變化的頻率。
通過對微調前后模型對token概率的改變進行可視化,仔細分析實驗結果,可以得到以下發現:
- SFT導致大部分 token (50%以上)的概率分布改變(粗粒度)
- RL/RFT只對特定 token (少于2%)進行有針對性的調整,同時保留了大部分內容(細粒度)
從理論上看,SFT的目標是最大化專家數據的似然,將專家演示的條件概率分布 “注入” 模型,類似人們通過“背書”學習,其梯度公式揭示了其內在機制:

該公式表明,對單個樣本訓練,SFT主要通過提高目標標記的概率,同時降低詞匯表中所有其他標記的概率,這會銳化模型的分布,從而產生更具確定性的輸出。 通過這種“一刀切”的方式,SFT強制模型去擬合專家數據,但也可能因此抑制模型的探索性和多樣性。
訓練動態可視化如下圖所示,數字表示訓練后的準確率。SRFT 通過在結合兩種方法實現直接優化,到達與SFT→RL接近的區域,且無需兩階段轉換。

為了進一步探究訓練動態,研究人員還從模型訓練軌跡的角度對幾種微調方法進行了可視化。論文提出了一種新穎的可視化方法。其核心思想是:
將不同模型看作高維空間中的點,通過計算它們在生成相同回復(response)時輸出token概率分布的“距離”,來描繪其在訓練過程中的“移動軌跡”。
具體而言,論文引入了三個參考模型——基礎模型(Qwen-2.5-Math-7B)、DeepSeek-R1和QwQ-32B作為坐標系,通過模型與參考模型回復的 teacher forcing 距離來間接測量模型在不同微調步驟中的訓練動態(如果兩個模型對所有提示(prompt)中的所有回復token分配相似的概率,則認為它們是接近的)。
結果表明,所有微調范式在提升性能的同時,均會偏離基礎模型空間,此外:
- SFT使模型在概率空間中移動的距離最遠,印證了其“大錘”般的全局性影響。
- SFT→RL的兩階段路徑揭示了一個問題:SFT可能將模型推得“過遠”,后續的RL反而需要將其“拉回”到離基礎模型更近的區域才能達到最優,這暗示了串行方法的低效性。
- SRFT的單階段路徑則顯得更為直接和高效,它在學習專家知識的同時,沒有過度偏離初始模型,從而實現了更精準的優化。
結合兩種范式:從兩階段到單階段
熵是信息論中的一個重要概念,它衡量的是隨機變量的不確定性。在 LLM 的推理過程中,熵可以反映模型輸出分布的不確定性,近期的諸多工作也展示了熵在 LLM 訓練中的重要性。
高熵表示模型的輸出分布較為均勻,不確定性較大;低熵則表示模型的輸出分布較為集中,不確定性較小。

圖注:兩種結合方式的性能、熵變化曲線
在該論文中,研究人員主要從SFT和RL結合的角度對熵展開了分析,如上圖所示。 在RL后進行SFT,會使模型的熵短暫增加,這表明模型在學習新的知識和模式時,其輸出分布變得更加不確定。
隨著訓練的進行,熵逐漸降低,模型逐漸收斂,輸出分布變得更加確定,最終提升模型性能。
相比之下,RL在訓練過程中則會使熵顯著降低,模型的輸出分布變得更加集中。這是因為RL通過獎勵函數引導模型學習特定的策略,使模型更傾向于生成能夠獲得高獎勵的輸出。然而,這種低熵的狀態也可能導致模型的可塑性降低,限制了后續訓練的效果。

圖注:不同結合方式的訓練效率
論文接著比較了純RL、不同SFT步數的順序SFT→RL方法,以及單階段SFT+RL方法。結果表明,與順序SFT→RL方法相比,單階段SFT+RL方法實現了更優的訓練效率。單階段SFT+RL方法通過統一優化有效利用演示數據,提速2.28倍。這種方法能夠直接針對目標進行策略優化,同時保留從數據集中通過監督學習進行知識蒸餾的優勢。
方法:監督強化微調(SRFT)
本論文提出SRFT (Supervised Reinforcement Fine-Tuning),將監督微調(SFT)和強化學習微調(RFT/RL)單階段結合。以下是對方法的描述:
核心思想
SRFT的核心在于其單階段學習機制:通過SFT實現粗粒度行為策略逼近,通過RL實現細粒度策略精化,借助于單階段訓練,將微調同時應用于演示數據和自生成的試錯數據。
從演示數據(demonstration)中學習

分布不匹配緩解策略

其中:
- 正樣本目標:類似于監督微調,最大化正確響應的似然
- 負樣本目標:實施似然最小化,減少分配給錯誤響應的概率

單階段集成方法
統一損失函數
通過同時利用演示數據和自探索試錯數據,SRFT有效平衡了SFT的粗粒度調整與RL的細粒度優化。總損失函數結合了所有四個組件:
關鍵機制總結
1. 熵感知權重:兩種熵感知權重機制確保訓練穩定性
- :當策略展現高熵(不確定性)時,權值降低,減少SFT對訓練的影響
- :當熵較高時,使RL訓練中正樣本訓練的權值上升,使熵下降,從而促進熵的穩定
2. 單階段優化:直接朝著目標函數優化,同時保持來自數據集的監督學習的知識蒸餾優勢
這種方法使SRFT能夠同時從演示數據和自探索試錯數據中受益,同時通過兩種熵感知權重機制保持穩定的訓練動態。
結果:性能顯著優于zero-RL方法,與其它結合方法相比提升明顯
關鍵發現
主要實驗結果(包含5個數學推理基準和3個非數學基準):

仔細分析SRFT與SFT、RL以及SFT與RL結合相關方法的性能比較,可以得到以下發現:
- 顯著性能提升:
- SRFT在五個挑戰性競賽級推理基準上取得了59.1%的平均準確率
- 比最佳zero-RL基線方法提升了+9.0個百分點
- 比SFT方法提升了+4.8個百分點
- 比SFT+RL組合方法提升了+3.4個百分點
- 泛化能力優秀:
- 平均分數: SRFT取得62.5分,比最佳基線提升+4.7個百分點
- 跨域表現: 在所有三個分布外基準上都表現出色
訓練動態分析:更穩、更長、更高效

△訓練動態曲線(獎勵、回復長度、熵)
- 訓練獎勵動態
- SRFT相比純RL實現了更快的性能改進,提速2.33倍
- 兩種方法都顯示出訓練獎勵的上升趨勢
- SRFT的收斂更加穩定
- 響應長度變化
- RL:傾向于生成更簡潔的響應
- SRFT:顯示出響應的逐步延長,表明發展出更全面詳細的推理過程
- 推理質量:響應長度的增加表明模型發展出更深入的推理過程
- 訓練熵動態
- RL: 表現出快速的熵下降
- SRFT: 維持更穩定的熵,表明策略能夠在訓練期間繼續探索
- 訓練穩定性: 熵感知權重機制的有效性得到驗證
總結
該工作分析探究了SFT與RL在LLM推理任務中各自的特點與結合方式,提出的SRFT方法通過基于熵的權重機制實現了SFT與RL的單階段結合。SRFT成功地在單階段訓練流程中實現了知識學習(SFT)與自主探索(RFT/RL)的動態平衡 ,在多項任務上取得了推理性能和泛化性能雙提升。
更多研究細節,可參考原論文。
項目網頁: https://anonymous.4open.science/w/SRFT2025
論文鏈接: https://arxiv.org/abs/2506.19767
模型鏈接: https://huggingface.co/Yuqian-Fu/SRFT