阿里面試:如果讓你負(fù)責(zé)大數(shù)據(jù)平臺(tái)的架構(gòu),需要考慮哪些點(diǎn)?如何設(shè)計(jì)?
一、引言
在當(dāng)今數(shù)字化時(shí)代,大數(shù)據(jù)已經(jīng)成為企業(yè)決策、產(chǎn)品創(chuàng)新及業(yè)務(wù)優(yōu)化的核心驅(qū)動(dòng)力。一個(gè)高效、可擴(kuò)展且安全的大數(shù)據(jù)架構(gòu),對(duì)于充分挖掘數(shù)據(jù)價(jià)值、提升業(yè)務(wù)洞察力至關(guān)重要。大數(shù)據(jù)架構(gòu)設(shè)計(jì)是一個(gè)復(fù)雜而系統(tǒng)的工程,需要綜合考慮業(yè)務(wù)需求、技術(shù)選型、安全合規(guī)等多個(gè)方面。本文將深入探討大數(shù)據(jù)架構(gòu)設(shè)計(jì)時(shí)需要關(guān)注的各個(gè)要點(diǎn)。

二、業(yè)務(wù)需求理解與目標(biāo)設(shè)定
1. 需求驅(qū)動(dòng),明確目標(biāo)
大數(shù)據(jù)架構(gòu)設(shè)計(jì)應(yīng)始于對(duì)業(yè)務(wù)需求的深刻理解。明確數(shù)據(jù)處理的目標(biāo)(如實(shí)時(shí)分析、批量處理、數(shù)據(jù)挖掘等),以及期望實(shí)現(xiàn)的業(yè)務(wù)價(jià)值,是設(shè)計(jì)工作的出發(fā)點(diǎn)。
- 需求調(diào)研:通過(guò)訪談、問(wèn)卷調(diào)查等方式收集業(yè)務(wù)部門(mén)對(duì)數(shù)據(jù)的需求。例如,電商企業(yè)可能需要分析用戶(hù)的購(gòu)買(mǎi)行為,以實(shí)現(xiàn)精準(zhǔn)營(yíng)銷(xiāo);金融企業(yè)則可能更關(guān)注風(fēng)險(xiǎn)評(píng)估和實(shí)時(shí)交易監(jiān)控。
- 需求優(yōu)先級(jí)排序:根據(jù)業(yè)務(wù)影響力和技術(shù)可行性,對(duì)需求進(jìn)行優(yōu)先級(jí)排序。對(duì)于一些關(guān)鍵業(yè)務(wù)需求,應(yīng)優(yōu)先在架構(gòu)設(shè)計(jì)中予以滿(mǎn)足。
- 目標(biāo)設(shè)定:明確架構(gòu)需支持的數(shù)據(jù)量、處理速度、查詢(xún)響應(yīng)時(shí)間等關(guān)鍵指標(biāo)。例如,要求架構(gòu)能夠處理PB級(jí)的數(shù)據(jù)量,查詢(xún)響應(yīng)時(shí)間在秒級(jí)以?xún)?nèi)。
2. 可擴(kuò)展性與靈活性
隨著數(shù)據(jù)量的不斷增長(zhǎng)和業(yè)務(wù)需求的不斷變化,大數(shù)據(jù)架構(gòu)必須具備良好的可擴(kuò)展性和靈活性,以應(yīng)對(duì)未來(lái)的挑戰(zhàn)。
- 模塊化設(shè)計(jì):將系統(tǒng)拆分為獨(dú)立的模塊或服務(wù),便于獨(dú)立升級(jí)和擴(kuò)展。例如,將數(shù)據(jù)采集、存儲(chǔ)、處理、分析等功能模塊分開(kāi)設(shè)計(jì),每個(gè)模塊可以根據(jù)需求進(jìn)行獨(dú)立的優(yōu)化和擴(kuò)展。
- 水平擴(kuò)展:優(yōu)先考慮通過(guò)增加節(jié)點(diǎn)來(lái)提升處理能力,而非提升單個(gè)節(jié)點(diǎn)的性能。水平擴(kuò)展可以避免單點(diǎn)故障,提高系統(tǒng)的可靠性和可擴(kuò)展性。例如,在分布式文件系統(tǒng)中,可以通過(guò)增加數(shù)據(jù)節(jié)點(diǎn)來(lái)擴(kuò)大存儲(chǔ)容量。
- 使用云原生技術(shù):利用容器化(如Docker)、微服務(wù)架構(gòu)、Kubernetes等技術(shù),提高系統(tǒng)的靈活性和可擴(kuò)展性。云原生技術(shù)可以實(shí)現(xiàn)資源的動(dòng)態(tài)分配和調(diào)度,使系統(tǒng)能夠快速適應(yīng)業(yè)務(wù)需求的變化。
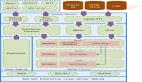
三、數(shù)據(jù)相關(guān)要點(diǎn)
1. 數(shù)據(jù)源與數(shù)據(jù)采集
- 多樣性數(shù)據(jù)源:數(shù)據(jù)可以來(lái)自不同的渠道,如傳感器、日志文件、社交媒體、交易系統(tǒng)等。在設(shè)計(jì)架構(gòu)時(shí),需要考慮如何高效地采集和整合這些多樣化的數(shù)據(jù)源。例如,物聯(lián)網(wǎng)應(yīng)用中,需要采集大量的傳感器數(shù)據(jù);電商平臺(tái)則需要采集用戶(hù)的交易記錄、瀏覽行為等數(shù)據(jù)。
- 數(shù)據(jù)采集工具:常用的工具包括Apache Kafka、Apache Flume、Apache NiFi等,用于高效地收集和傳輸數(shù)據(jù)。不同的采集工具適用于不同的場(chǎng)景,需要根據(jù)數(shù)據(jù)源的特點(diǎn)和業(yè)務(wù)需求進(jìn)行選擇。例如,Kafka適用于處理實(shí)時(shí)數(shù)據(jù)流,F(xiàn)lume適用于大規(guī)模的日志采集和傳輸。
2. 數(shù)據(jù)存儲(chǔ)
- 分布式文件系統(tǒng):如Hadoop Distributed File System (HDFS),用于存儲(chǔ)大規(guī)模非結(jié)構(gòu)化數(shù)據(jù)。HDFS具有高可用性、可擴(kuò)展性和容錯(cuò)性等優(yōu)點(diǎn),能夠存儲(chǔ)PB級(jí)甚至EB級(jí)的數(shù)據(jù)。
- NoSQL數(shù)據(jù)庫(kù):如Cassandra、HBase、MongoDB,用于存儲(chǔ)和查詢(xún)大規(guī)模結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)。NoSQL數(shù)據(jù)庫(kù)具有靈活的數(shù)據(jù)模型和高可擴(kuò)展性,能夠滿(mǎn)足大數(shù)據(jù)存儲(chǔ)和查詢(xún)的需求。例如,MongoDB適合存儲(chǔ)非結(jié)構(gòu)化數(shù)據(jù),HBase則適合進(jìn)行實(shí)時(shí)大規(guī)模數(shù)據(jù)集的讀寫(xiě)操作。
- 數(shù)據(jù)湖:用于存儲(chǔ)來(lái)自不同源的原始數(shù)據(jù),支持多種數(shù)據(jù)格式和存儲(chǔ)選項(xiàng)。數(shù)據(jù)湖具有靈活性和成本效益高的特點(diǎn),允許用戶(hù)在不預(yù)先定義模式的情況下存儲(chǔ)數(shù)據(jù)。例如,企業(yè)可以將各種類(lèi)型的數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)湖中,然后根據(jù)需要進(jìn)行分析和挖掘。
- 數(shù)據(jù)倉(cāng)庫(kù):經(jīng)過(guò)整理和結(jié)構(gòu)化的數(shù)據(jù)存儲(chǔ),適合業(yè)務(wù)報(bào)表和分析。數(shù)據(jù)倉(cāng)庫(kù)通常采用星型或雪花模型構(gòu)建維度表與事實(shí)表,支持MPP數(shù)據(jù)庫(kù)(如Greenplum、Doris)。例如,企業(yè)可以將經(jīng)過(guò)清洗和轉(zhuǎn)換的數(shù)據(jù)存儲(chǔ)在數(shù)據(jù)倉(cāng)庫(kù)中,用于生成各種報(bào)表和進(jìn)行數(shù)據(jù)分析。
3. 數(shù)據(jù)處理
- 批處理:處理大規(guī)模數(shù)據(jù)集的標(biāo)準(zhǔn)方法,工具如Apache Hadoop的MapReduce、Apache Spark。批處理適用于處理大量歷史數(shù)據(jù),如每天的銷(xiāo)售數(shù)據(jù)統(tǒng)計(jì)、每月的財(cái)務(wù)報(bào)表生成等。
- 流處理:實(shí)時(shí)處理數(shù)據(jù)流的工具,如Apache Kafka Streams、Apache Flink、Apache Storm。流處理適用于實(shí)時(shí)數(shù)據(jù)分析和監(jiān)控,如實(shí)時(shí)交易監(jiān)控、實(shí)時(shí)風(fēng)險(xiǎn)預(yù)警等。
- 混合處理:結(jié)合批處理和流處理的架構(gòu),如Lambda架構(gòu)和Kappa架構(gòu)。混合處理可以充分發(fā)揮批處理和流處理的優(yōu)勢(shì),滿(mǎn)足不同業(yè)務(wù)場(chǎng)景的需求。例如,Lambda架構(gòu)中,批處理層負(fù)責(zé)處理離線數(shù)據(jù),加速層負(fù)責(zé)處理實(shí)時(shí)數(shù)據(jù)流,服務(wù)層整合批處理層和加速層的結(jié)果,提供統(tǒng)一的數(shù)據(jù)查詢(xún)和服務(wù)接口。
4. 數(shù)據(jù)集成與ETL
- ETL工具:用于抽取、轉(zhuǎn)換和加載數(shù)據(jù),如Apache Nifi、Apache Airflow、Talend。ETL工具可以將不同數(shù)據(jù)源的數(shù)據(jù)進(jìn)行抽取、清洗、轉(zhuǎn)換和加載,使其符合目標(biāo)系統(tǒng)的要求。例如,將多個(gè)數(shù)據(jù)庫(kù)中的數(shù)據(jù)抽取出來(lái),進(jìn)行清洗和轉(zhuǎn)換后,加載到數(shù)據(jù)倉(cāng)庫(kù)中。
- 數(shù)據(jù)管道:設(shè)計(jì)高效的ETL管道,確保數(shù)據(jù)在各階段的無(wú)縫流動(dòng)和轉(zhuǎn)化。數(shù)據(jù)管道可以實(shí)現(xiàn)數(shù)據(jù)的自動(dòng)化處理和傳輸,提高數(shù)據(jù)處理的效率和可靠性。例如,通過(guò)數(shù)據(jù)管道將實(shí)時(shí)數(shù)據(jù)流從數(shù)據(jù)源傳輸?shù)教幚硐到y(tǒng),再將處理結(jié)果傳輸?shù)酱鎯?chǔ)系統(tǒng)。
5. 數(shù)據(jù)治理與數(shù)據(jù)質(zhì)量
- 數(shù)據(jù)治理:包括數(shù)據(jù)的定義、分類(lèi)、隱私保護(hù)和合規(guī)性策略。數(shù)據(jù)治理可以確保數(shù)據(jù)的一致性、準(zhǔn)確性和安全性,提高數(shù)據(jù)的價(jià)值和可用性。例如,制定數(shù)據(jù)標(biāo)準(zhǔn)和規(guī)范,對(duì)數(shù)據(jù)進(jìn)行分類(lèi)分級(jí)管理,保護(hù)用戶(hù)的隱私數(shù)據(jù)。
- 數(shù)據(jù)質(zhì)量:確保數(shù)據(jù)的準(zhǔn)確性、完整性、一致性和及時(shí)性。數(shù)據(jù)質(zhì)量問(wèn)題可能會(huì)影響數(shù)據(jù)分析的結(jié)果和業(yè)務(wù)決策的準(zhǔn)確性,因此需要建立數(shù)據(jù)質(zhì)量監(jiān)控和管理機(jī)制。例如,通過(guò)數(shù)據(jù)清洗、校驗(yàn)和驗(yàn)證等手段,提高數(shù)據(jù)的質(zhì)量。
四、數(shù)據(jù)分析與機(jī)器學(xué)習(xí)
1. 數(shù)據(jù)分析平臺(tái)
如Apache Hive、Apache Drill,用于數(shù)據(jù)倉(cāng)庫(kù)查詢(xún)。數(shù)據(jù)分析平臺(tái)可以提供強(qiáng)大的數(shù)據(jù)分析和查詢(xún)功能,幫助企業(yè)從海量數(shù)據(jù)中提取有價(jià)值的信息。例如,使用Hive進(jìn)行SQL查詢(xún),對(duì)數(shù)據(jù)倉(cāng)庫(kù)中的數(shù)據(jù)進(jìn)行分析和挖掘。
2. 機(jī)器學(xué)習(xí)
工具如Apache Spark MLlib、TensorFlow、Scikit - learn,用于大規(guī)模數(shù)據(jù)的機(jī)器學(xué)習(xí)模型訓(xùn)練和預(yù)測(cè)。機(jī)器學(xué)習(xí)可以幫助企業(yè)發(fā)現(xiàn)數(shù)據(jù)中的潛在模式和規(guī)律,進(jìn)行預(yù)測(cè)和決策。例如,使用機(jī)器學(xué)習(xí)算法進(jìn)行客戶(hù)細(xì)分、風(fēng)險(xiǎn)評(píng)估、推薦系統(tǒng)等。
五、安全性與隱私保護(hù)
1. 數(shù)據(jù)加密
在數(shù)據(jù)傳輸和存儲(chǔ)過(guò)程中應(yīng)用加密技術(shù),確保數(shù)據(jù)的安全性。例如,使用SSL/TLS協(xié)議對(duì)數(shù)據(jù)傳輸進(jìn)行加密,使用對(duì)稱(chēng)加密算法(如AES)對(duì)數(shù)據(jù)存儲(chǔ)進(jìn)行加密。
2. 訪問(wèn)控制
實(shí)現(xiàn)細(xì)粒度的訪問(wèn)權(quán)限管理,如基于角色的訪問(wèn)控制(RBAC)。訪問(wèn)控制可以確保只有授權(quán)用戶(hù)可以訪問(wèn)特定的數(shù)據(jù),防止數(shù)據(jù)泄露和濫用。例如,根據(jù)用戶(hù)的角色和職責(zé),分配不同的訪問(wèn)權(quán)限,對(duì)敏感數(shù)據(jù)進(jìn)行嚴(yán)格的訪問(wèn)控制。
3. 審計(jì)與監(jiān)控
實(shí)時(shí)監(jiān)控和審計(jì)數(shù)據(jù)訪問(wèn)和使用情況,確保合規(guī)性和安全性。審計(jì)與監(jiān)控可以及時(shí)發(fā)現(xiàn)異常行為和安全事件,采取相應(yīng)的措施進(jìn)行處理。例如,通過(guò)安全審計(jì)系統(tǒng)記錄用戶(hù)的訪問(wèn)行為,對(duì)異常訪問(wèn)進(jìn)行實(shí)時(shí)報(bào)警。
4. 隱私保護(hù)與數(shù)據(jù)脫敏
對(duì)用戶(hù)敏感信息進(jìn)行對(duì)外查詢(xún)、展現(xiàn)、統(tǒng)計(jì)等操作時(shí),必須經(jīng)過(guò)模糊化處理;對(duì)用戶(hù)敏感信息進(jìn)行開(kāi)放前,應(yīng)通過(guò)數(shù)據(jù)脫敏、數(shù)據(jù)模糊標(biāo)簽化、群體統(tǒng)計(jì)等方式進(jìn)行處理。隱私保護(hù)可以保護(hù)用戶(hù)的個(gè)人信息不被泄露,符合相關(guān)法律法規(guī)的要求。例如,對(duì)用戶(hù)的身份證號(hào)碼、手機(jī)號(hào)碼等敏感信息進(jìn)行脫敏處理。
六、可擴(kuò)展性與性能優(yōu)化
1. 水平擴(kuò)展
通過(guò)增加節(jié)點(diǎn)來(lái)擴(kuò)展系統(tǒng)容量和處理能力。水平擴(kuò)展可以避免單點(diǎn)故障,提高系統(tǒng)的可靠性和可擴(kuò)展性。例如,在分布式計(jì)算系統(tǒng)中,可以通過(guò)增加計(jì)算節(jié)點(diǎn)來(lái)提升處理能力。
2. 性能優(yōu)化
- 緩存:使用緩存技術(shù)(如Redis)減少數(shù)據(jù)訪問(wèn)的延遲,提高系統(tǒng)的響應(yīng)速度。緩存可以存儲(chǔ)經(jīng)常訪問(wèn)的數(shù)據(jù),避免頻繁地訪問(wèn)磁盤(pán)或數(shù)據(jù)庫(kù)。例如,將熱門(mén)商品的信息緩存到Redis中,提高用戶(hù)訪問(wèn)的響應(yīng)速度。
- 數(shù)據(jù)分區(qū)與分片:將數(shù)據(jù)分割成更小的部分,提高數(shù)據(jù)的訪問(wèn)速度和系統(tǒng)的整體性能。數(shù)據(jù)分區(qū)可以將查詢(xún)限制在較小的數(shù)據(jù)集上,從而加快響應(yīng)速度;數(shù)據(jù)分片可以將數(shù)據(jù)分布到多個(gè)節(jié)點(diǎn)上,實(shí)現(xiàn)負(fù)載均衡和高可用性。例如,在數(shù)據(jù)庫(kù)中對(duì)表進(jìn)行分區(qū),根據(jù)時(shí)間或地域等因素將數(shù)據(jù)劃分到不同的分區(qū)中。
- 優(yōu)化存儲(chǔ):根據(jù)數(shù)據(jù)訪問(wèn)模式選擇合適的存儲(chǔ)方案,如HDFS用于大文件存儲(chǔ),HBase用于列式存儲(chǔ)等。不同的存儲(chǔ)方案適用于不同的數(shù)據(jù)訪問(wèn)模式,選擇合適的存儲(chǔ)方案可以提高數(shù)據(jù)的存儲(chǔ)和訪問(wèn)效率。例如,對(duì)于經(jīng)常進(jìn)行范圍查詢(xún)的數(shù)據(jù),使用列式存儲(chǔ)可以提高查詢(xún)效率。
- 使用內(nèi)存計(jì)算:利用內(nèi)存計(jì)算技術(shù)(如Spark的內(nèi)存計(jì)算)提高數(shù)據(jù)處理的速度。內(nèi)存計(jì)算可以將數(shù)據(jù)存儲(chǔ)在內(nèi)存中,避免磁盤(pán)I/O的開(kāi)銷(xiāo),提高數(shù)據(jù)處理的效率。例如,使用Spark進(jìn)行內(nèi)存計(jì)算,對(duì)大規(guī)模數(shù)據(jù)集進(jìn)行快速處理。
七、高可用性與容錯(cuò)性
1. 冗余和副本
通過(guò)數(shù)據(jù)冗余和多副本機(jī)制提高系統(tǒng)的容錯(cuò)能力。例如,在分布式文件系統(tǒng)中,將數(shù)據(jù)復(fù)制多個(gè)副本存儲(chǔ)在不同的節(jié)點(diǎn)上,當(dāng)某個(gè)節(jié)點(diǎn)出現(xiàn)故障時(shí),可以從其他節(jié)點(diǎn)獲取數(shù)據(jù)副本。
2. 自動(dòng)恢復(fù)
設(shè)計(jì)自動(dòng)化的故障檢測(cè)和恢復(fù)機(jī)制,確保系統(tǒng)的高可用性。例如,使用ZooKeeper進(jìn)行分布式協(xié)調(diào)和故障檢測(cè),當(dāng)節(jié)點(diǎn)出現(xiàn)故障時(shí),自動(dòng)進(jìn)行故障轉(zhuǎn)移和恢復(fù)。
八、可視化與報(bào)告
1. 數(shù)據(jù)可視化工具
如Tableau、PowerBI、Apache Superset,用于生成可視化圖表和報(bào)告。數(shù)據(jù)可視化可以將復(fù)雜的數(shù)據(jù)以直觀的圖表和報(bào)表形式展示出來(lái),幫助用戶(hù)更好地理解和分析數(shù)據(jù)。例如,使用Tableau制作銷(xiāo)售報(bào)表、用戶(hù)行為分析圖表等。
2. 儀表盤(pán)
實(shí)時(shí)監(jiān)控系統(tǒng)性能和數(shù)據(jù)流的可視化儀表盤(pán)。儀表盤(pán)可以提供實(shí)時(shí)的系統(tǒng)狀態(tài)信息,幫助管理員及時(shí)發(fā)現(xiàn)和解決問(wèn)題。例如,通過(guò)儀表盤(pán)監(jiān)控?cái)?shù)據(jù)處理的吞吐量、延遲等指標(biāo)。
九、DevOps與自動(dòng)化
1. CI/CD
持續(xù)集成和持續(xù)部署,提高開(kāi)發(fā)和運(yùn)維的效率。CI/CD可以實(shí)現(xiàn)代碼的自動(dòng)化構(gòu)建、測(cè)試和部署,減少人工干預(yù),提高軟件的交付速度和質(zhì)量。例如,使用Jenkins等工具實(shí)現(xiàn)CI/CD流程。
2. 基礎(chǔ)設(shè)施即代碼(IaC)
使用工具如Terraform、Ansible管理和部署大數(shù)據(jù)基礎(chǔ)設(shè)施。IaC可以將基礎(chǔ)設(shè)施的配置和管理以代碼的形式進(jìn)行描述,實(shí)現(xiàn)基礎(chǔ)設(shè)施的自動(dòng)化部署和管理。例如,使用Terraform定義云資源的配置,自動(dòng)創(chuàng)建和管理云服務(wù)器、存儲(chǔ)等資源。
十、技術(shù)選型與生態(tài)系統(tǒng)
1. 選擇合適的技術(shù)棧
在選擇架構(gòu)時(shí),需要考慮技術(shù)棧的靈活性和適應(yīng)性,支持多種工具和技術(shù)的集成,以便快速適應(yīng)業(yè)務(wù)變化。例如,支持多語(yǔ)言編程、兼容不同的數(shù)據(jù)存儲(chǔ)系統(tǒng)、支持多種分析工具等。同時(shí),要考慮技術(shù)的成熟度和社區(qū)支持,選擇穩(wěn)定可靠的技術(shù)。
2. 融入大數(shù)據(jù)生態(tài)系統(tǒng)
大數(shù)據(jù)技術(shù)通常形成了一個(gè)龐大的生態(tài)系統(tǒng),各個(gè)組件之間可以相互協(xié)作和集成。例如,Hadoop生態(tài)系統(tǒng)包括HDFS、MapReduce、Hive、Pig等組件,Spark生態(tài)系統(tǒng)包括Spark Core、Spark SQL、Spark Streaming等組件。在設(shè)計(jì)架構(gòu)時(shí),要考慮如何融入這些生態(tài)系統(tǒng),充分利用生態(tài)系統(tǒng)的優(yōu)勢(shì)。
十一、成本考量
1. 硬件成本
包括服務(wù)器、存儲(chǔ)設(shè)備等硬件的采購(gòu)和維護(hù)成本。在設(shè)計(jì)架構(gòu)時(shí),需要根據(jù)業(yè)務(wù)需求和數(shù)據(jù)量,合理選擇硬件配置,避免過(guò)度投資。例如,對(duì)于數(shù)據(jù)量較小的企業(yè),可以選擇使用云服務(wù)提供商的基礎(chǔ)設(shè)施,降低硬件成本。
2. 軟件成本
包括數(shù)據(jù)庫(kù)軟件、數(shù)據(jù)分析工具、機(jī)器學(xué)習(xí)框架等軟件的授權(quán)和使用成本。一些商業(yè)軟件可能需要支付較高的授權(quán)費(fèi)用,因此可以考慮使用開(kāi)源軟件來(lái)降低成本。例如,使用開(kāi)源的Hadoop、Spark等框架進(jìn)行大數(shù)據(jù)處理。
3. 運(yùn)維成本
包括系統(tǒng)的監(jiān)控、維護(hù)、升級(jí)等運(yùn)維工作的成本。設(shè)計(jì)架構(gòu)時(shí),要考慮系統(tǒng)的易維護(hù)性和可管理性,減少運(yùn)維工作量和成本。例如,采用自動(dòng)化運(yùn)維工具(如Ansible、Puppet)進(jìn)行系統(tǒng)的配置管理和故障恢復(fù)。
大數(shù)據(jù)架構(gòu)設(shè)計(jì)是一個(gè)綜合性的工程,需要綜合考慮業(yè)務(wù)需求、數(shù)據(jù)處理、安全性、可擴(kuò)展性、性能優(yōu)化等多個(gè)方面的要點(diǎn)。一個(gè)優(yōu)秀的大數(shù)據(jù)架構(gòu)應(yīng)該能夠滿(mǎn)足企業(yè)的業(yè)務(wù)目標(biāo),適應(yīng)數(shù)據(jù)量的增長(zhǎng)和業(yè)務(wù)需求的變化,確保數(shù)據(jù)的安全性和隱私性,提供高效的數(shù)據(jù)處理和分析能力。在設(shè)計(jì)過(guò)程中,需要根據(jù)企業(yè)的實(shí)際情況進(jìn)行權(quán)衡和選擇,不斷優(yōu)化和調(diào)整架構(gòu),以實(shí)現(xiàn)大數(shù)據(jù)的最大價(jià)值。