LLM壓縮技術(shù)全解析:讓 AI 更 “瘦” 更快更智能
當(dāng)下大型語言模型(LLMs)和復(fù)雜深度學(xué)習(xí)系統(tǒng)展現(xiàn)出了令人驚嘆的能力。它們能夠編寫代碼、生成精美圖像,還能理解細(xì)微的語言差別。然而,這些強(qiáng)大的功能背后,是模型規(guī)模不斷膨脹帶來的難題。當(dāng)前最先進(jìn)的模型參數(shù)可達(dá)數(shù)十億甚至數(shù)萬億,這對計算資源、能源消耗和存儲都提出了極高要求。模型壓縮與優(yōu)化技術(shù)應(yīng)運而生,成為解決這些問題的關(guān)鍵,它致力于在不損害模型智能的前提下縮小模型規(guī)模,為人工智能的廣泛應(yīng)用開辟新道路。
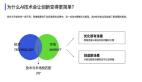
一、為何壓縮AI模型?
壓縮AI模型并非僅僅是學(xué)術(shù)追求,而是有著切實的好處。
(一)資源高效利用
較小的模型意味著對內(nèi)存(RAM)和存儲的需求降低。這使得在智能手機(jī)、物聯(lián)網(wǎng)傳感器、可穿戴設(shè)備和嵌入式系統(tǒng)等硬件資源有限的設(shè)備上部署模型成為可能。以智能手環(huán)為例,其內(nèi)存和存儲容量十分有限,如果能將用于健康監(jiān)測的AI模型進(jìn)行壓縮,就可以直接在設(shè)備上實時分析用戶的心率、睡眠數(shù)據(jù)等,而無需將數(shù)據(jù)上傳至云端處理,既節(jié)省了數(shù)據(jù)傳輸成本,又保護(hù)了用戶隱私。
(二)成本降低
計算量的減少直接意味著云服務(wù)費用的降低。同時,存儲需求的減少也能削減成本。這使得先進(jìn)的人工智能技術(shù)對于企業(yè)和研究人員來說更具經(jīng)濟(jì)可行性。對于小型創(chuàng)業(yè)公司而言,使用壓縮后的模型可以大大降低在AI研發(fā)和應(yīng)用上的成本,讓他們能夠在有限的預(yù)算下開展創(chuàng)新業(yè)務(wù)。
(三)推理速度加快
一般來說,較小的模型運行速度更快。這對于自動駕駛、實時聊天機(jī)器人、實時視頻分析和交互式虛擬助手等實時應(yīng)用至關(guān)重要。低延遲能夠帶來更好的用戶體驗。在自動駕駛場景中,快速的模型推理可以讓車輛迅速對道路上的突發(fā)情況做出反應(yīng),保障行車安全。
(四)節(jié)能
計算量的減少直接轉(zhuǎn)化為功耗的降低。這對于依靠電池供電的設(shè)備來說至關(guān)重要,也有助于推動更可持續(xù)的 “綠色AI” 實踐。例如,衛(wèi)星在太空中依靠太陽能供電,使用壓縮后的AI模型進(jìn)行圖像分析等任務(wù),可以減少能源消耗,延長衛(wèi)星的使用壽命。
(五)提高可及性
縮小模型規(guī)模可以使先進(jìn)的人工智能功能覆蓋更多用戶和設(shè)備,而不受高端硬件或高速互聯(lián)網(wǎng)連接的限制,尤其是對于設(shè)備端AI應(yīng)用。在偏遠(yuǎn)地區(qū),網(wǎng)絡(luò)信號不穩(wěn)定,通過壓縮模型實現(xiàn)設(shè)備端AI,可以讓當(dāng)?shù)鼐用袷褂没贏I的農(nóng)業(yè)病蟲害檢測等應(yīng)用,助力農(nóng)業(yè)生產(chǎn)。
二、關(guān)鍵模型壓縮技術(shù)詳解
(一)剪枝:去除冗余
想象一下修剪盆景樹,小心地剪掉不必要的樹枝以保持其健康和形狀。在人工智能中,剪枝就是識別并去除神經(jīng)網(wǎng)絡(luò)中對最終輸出貢獻(xiàn)較小的冗余連接(權(quán)重),甚至是整個神經(jīng)元或結(jié)構(gòu)。通常,幅度較小(接近零)的權(quán)重被認(rèn)為不太重要。剪枝算法會識別這些權(quán)重并將其永久設(shè)置為零。更先進(jìn)的技術(shù)可能會評估神經(jīng)元的激活模式或使用敏感性分析。這會在模型中創(chuàng)建稀疏性。
剪枝分為非結(jié)構(gòu)化剪枝(去除單個權(quán)重)和結(jié)構(gòu)化剪枝(去除神經(jīng)元、濾波器或?qū)樱K膬?yōu)點是可以顯著減少模型參數(shù)數(shù)量(模型大小),如果操作得當(dāng)(結(jié)構(gòu)化剪枝),尤其是在硬件或庫支持稀疏計算的情況下,還能提高推理速度,模型大小最多可減少90%,推理速度可加快6倍。而且該技術(shù)可以在訓(xùn)練后或訓(xùn)練過程中使用。不過,剪枝也存在缺點,如果剪枝過于激進(jìn),可能會對模型精度產(chǎn)生負(fù)面影響;非結(jié)構(gòu)化剪枝在沒有專門硬件/軟件支持的情況下可能無法提高速度;找到壓縮和精度之間的平衡通常需要反復(fù)調(diào)整,還需要仔細(xì)進(jìn)行微調(diào)。剪枝技術(shù)適用于在內(nèi)存嚴(yán)格受限的設(shè)備上部署模型,或者在可以接受輕微精度損失的情況下減小大型模型的規(guī)模。比如在移動設(shè)備上對ResNet模型進(jìn)行剪枝,可實現(xiàn)更快的圖像分類;經(jīng)過剪枝的YOLO模型能在無人機(jī)上實時檢測物體,且內(nèi)存使用減少60%。
(二)量化:降低數(shù)值精度
以表示顏色為例,可以用數(shù)百萬種色調(diào)(如高精度數(shù)字,32位浮點型,F(xiàn)P32),也可以用較小的調(diào)色板(如低精度數(shù)字,8位整數(shù),INT8)。量化就是減少用于存儲模型權(quán)重和/或激活值的數(shù)值精度。它將高精度的浮點數(shù)(如FP32)映射到較低精度的表示形式(如FP16、INT8或更少的比特位),從而大幅減少每個參數(shù)所需的內(nèi)存。
量化分為訓(xùn)練后量化(PTQ)和量化感知訓(xùn)練(QAT)。其優(yōu)點是能顯著減小模型大小(如從FP32到INT8可減少4倍),在具有優(yōu)化的低精度指令的硬件(如GPU和TPU)上,有大幅提高推理速度的潛力,還能降低功耗、加速計算(如推理速度加快2倍),并且得到了TensorFlow Lite、PyTorch Mobile等框架的支持,在移動/邊緣機(jī)器學(xué)習(xí)工具包(如TensorFlow Lite、ONNX)中也有很好的支持。然而,量化幾乎總是會導(dǎo)致一定的精度損失,盡管量化感知訓(xùn)練等技術(shù)可以減輕這種損失;不同模型對量化的敏感度不同,有些部分可能比其他部分更容易受到低精度的影響;還可能存在硬件特定的兼容性問題。量化技術(shù)適用于智能手機(jī)、物聯(lián)網(wǎng)設(shè)備上的邊緣AI,加速數(shù)據(jù)中心的推理,以及減少內(nèi)存帶寬瓶頸。例如,在安卓智能手機(jī)上部署量化后的BERT模型用于自然語言處理任務(wù);WhatsApp使用8位量化在本地運行語音轉(zhuǎn)文本模型。
(三)知識蒸餾:向 “大師” 學(xué)習(xí)
想象一個經(jīng)驗豐富的大型 “教師” 模型訓(xùn)練一個更小、更快的 “學(xué)生” 模型。學(xué)生不僅學(xué)習(xí)正確答案(硬標(biāo)簽),還通過模仿教師模型的輸出概率(軟標(biāo)簽或logits)來學(xué)習(xí)教師得出結(jié)論的方式。大型預(yù)訓(xùn)練教師模型處理數(shù)據(jù),其輸出層的概率(包含比最終預(yù)測更豐富的信息)被用作訓(xùn)練較小學(xué)生模型的損失函數(shù)的一部分。
知識蒸餾的優(yōu)點是可以將復(fù)雜知識從大型模型轉(zhuǎn)移到小得多的模型中,通常能很好地保持精度,學(xué)生模型可以從教師模型的 “泛化” 能力中受益,在模型大小縮小10倍的情況下仍能保持95%以上的精度,非常適合特定任務(wù)的部署。但它也存在缺點,需要有一個訓(xùn)練良好(通常成本較高)的教師模型;訓(xùn)練過程可能比標(biāo)準(zhǔn)訓(xùn)練更復(fù)雜;學(xué)生模型可能無法捕捉到教師模型的每一個細(xì)微差別;知識轉(zhuǎn)移過程耗時。該技術(shù)適用于從大型通用模型創(chuàng)建高度專業(yè)化、高效的模型,以及在資源受限的硬件上部署復(fù)雜的人工智能功能。比如將GPT風(fēng)格的變壓器模型進(jìn)行知識蒸餾,得到一個可以在沒有GPU的筆記本電腦上運行的小型聊天機(jī)器人;在醫(yī)療領(lǐng)域,蒸餾后的BERT模型可以在低功耗平板電腦上根據(jù)醫(yī)療記錄診斷疾病。
(四)權(quán)重共享:參數(shù)復(fù)用
權(quán)重共享通過在不同層之間重用權(quán)重來減少冗余。一組權(quán)重被強(qiáng)制使用相同的值,從而減少需要存儲的唯一權(quán)重的總數(shù)。這就好比使用一組有限的 “印章”,而不是每次都單獨繪制每個細(xì)節(jié)。在卷積神經(jīng)網(wǎng)絡(luò)(CNNs)中應(yīng)用共享濾波器,可以將參數(shù)減少50%以上。
權(quán)重共享的優(yōu)點是顯著降低內(nèi)存使用,在某些情況下還能提高模型的泛化能力,并且通常與量化技術(shù)結(jié)合使用。但它也有限制模型靈活性的缺點,如果分組過于激進(jìn)可能會影響性能,還需要專門的訓(xùn)練或轉(zhuǎn)換。該技術(shù)適用于自動編碼器,例如用于壓縮安全攝像頭視頻流的權(quán)重共享模型;以及在對模型占用空間要求較高的圖像處理應(yīng)用中的CNN模型。
(五)低秩分解:簡化數(shù)學(xué)運算
低秩分解將大型權(quán)重矩陣分解為更小的低秩矩陣。它利用線性代數(shù)的性質(zhì),用較少的參數(shù)來近似原始矩陣,對于全連接層特別有效。通常使用奇異值分解(SVD)等技術(shù),分析權(quán)重矩陣的冗余,將每個大型矩陣分解為較小矩陣的乘積,用分解后的版本替換原始層,然后對分解后的模型進(jìn)行微調(diào)。
在推薦系統(tǒng)中,低秩分解可以將參數(shù)減少70%,并且在適當(dāng)調(diào)整的情況下能夠保持精度,對密集層和注意力頭很有用。不過,尋找最優(yōu)秩的計算量較大,確定合適的秩也比較復(fù)雜,而且并非對所有層都同樣有益。例如,亞馬遜使用低秩分解來縮小產(chǎn)品推薦模型。
(六)二值化:極致壓縮
二值化將權(quán)重表示為1位值(-1或1),是一種極端的量化形式,其中權(quán)重有時甚至激活值都被限制為僅兩個值,通常是+1和 -1(或0和1)。這實現(xiàn)了最大程度的壓縮,并有可能進(jìn)行極快的位運算,但往往會導(dǎo)致顯著的精度下降。它通過犧牲精度來實現(xiàn)激進(jìn)的壓縮,用二進(jìn)制運算代替浮點運算,使用專門的訓(xùn)練技術(shù)來處理二進(jìn)制約束,并利用位運算實現(xiàn)極快的計算。
二值化可以使模型大小縮小32倍(從32位到1位),能夠在微控制器上實現(xiàn)AI,大幅降低模型大小和功耗。但其缺點是在復(fù)雜任務(wù)上精度會大幅下降,嚴(yán)重影響復(fù)雜模型的性能,主要適用于輕量級任務(wù)。在物聯(lián)網(wǎng)領(lǐng)域,二進(jìn)制傳感器可以使用100KB的模型檢測工廠機(jī)器故障;還適用于可穿戴設(shè)備和嵌入式設(shè)備的超高效模型。
(七)混合方法:集各家之長
通常,將多種技術(shù)結(jié)合可以獲得最佳效果。例如,先對模型進(jìn)行剪枝,然后再進(jìn)行量化;或者使用知識蒸餾來訓(xùn)練剪枝/量化后的學(xué)生模型。混合方法利用了多種技術(shù)的優(yōu)勢,能夠?qū)崿F(xiàn)比單個方法更好的壓縮效果和性能。例如,將知識蒸餾與低秩分解相結(jié)合,可以將GPT-3壓縮10倍,從而加快ChatGPT的響應(yīng)速度;先對模型進(jìn)行剪枝再量化,如ConvNeXt模型在縮小90%的同時精度提高了3.8%。不過,混合方法的實現(xiàn)和優(yōu)化可能比較復(fù)雜,還可能需要額外的計算資源。像MobileNet(用于移動設(shè)備的CNN)使用深度可分離卷積 + 量化;DistilBERT結(jié)合了知識蒸餾和剪枝以實現(xiàn)高效的自然語言處理;用于自主無人機(jī)導(dǎo)航的混合壓縮模型則結(jié)合了蒸餾模型、量化層和剪枝卷積濾波器。
三、模型壓縮的意義與挑戰(zhàn)
(一)意義
模型壓縮帶來了巨大的效率提升,顯著降低了計算成本、存儲需求和功耗。同時,大幅加快了推理速度,減少了延遲,提升了實時性能。它還推動了人工智能的普及,使先進(jìn)的AI技術(shù)能夠應(yīng)用于日常設(shè)備,為預(yù)算有限的組織提供了使用AI的機(jī)會。此外,降低了AI運行的能源消耗,有助于實現(xiàn)可持續(xù)發(fā)展。
(二)挑戰(zhàn)
然而,模型壓縮也面臨諸多挑戰(zhàn)。大多數(shù)壓縮技術(shù)都存在降低模型精度的風(fēng)險,如何在壓縮模型的同時最小化精度損失是關(guān)鍵難題。實現(xiàn)和有效調(diào)整這些技術(shù)需要專業(yè)知識,過程較為復(fù)雜。一些技術(shù)(如結(jié)構(gòu)化剪枝或特定的量化級別)需要特定的硬件支持或優(yōu)化的軟件庫(如TensorRT、ONNX Runtime、TensorFlow Lite)才能充分發(fā)揮其速度優(yōu)勢。而且,為特定模型和任務(wù)找到最佳的壓縮策略和參數(shù),往往需要進(jìn)行大量的實驗。
在實際應(yīng)用中,還需要應(yīng)對動態(tài)工作負(fù)載的挑戰(zhàn),即如何根據(jù)實時數(shù)據(jù)的變化調(diào)整壓縮策略。此外,硬件限制也不容忽視,并非所有芯片都支持4位量化等高級壓縮技術(shù)。
模型壓縮與優(yōu)化已經(jīng)成為人工智能實際部署和擴(kuò)展的關(guān)鍵環(huán)節(jié)。通過理解和應(yīng)用剪枝、量化、知識蒸餾、權(quán)重共享、低秩分解、二值化等技術(shù),開發(fā)者能夠顯著減小模型規(guī)模,提高推理速度,降低部署成本。在實際應(yīng)用中,根據(jù)具體的使用場景和硬件目標(biāo),將多種壓縮方法結(jié)合使用往往能取得最佳效果。隨著壓縮技術(shù)的成熟和工具的不斷改進(jìn),人工智能將在更多設(shè)備和應(yīng)用中變得更加易用和高效,最終實現(xiàn)將最先進(jìn)的人工智能能力普及到每一個設(shè)備,同時最大限度地降低能源消耗,提升性能的目標(biāo)。