模態(tài)編碼器 | 無文本編碼器仍媲美CLIP的SuperClass模型!

今天來看一篇字節(jié)在2024NIPS上的一篇工作,SuperClass,一個(gè)超級簡單且高效的預(yù)訓(xùn)練方法。
研究動機(jī):訓(xùn)練CLIP需要大量的數(shù)據(jù)和算力,嚴(yán)重限制了資源和專業(yè)知識有限的研究人員使用。于是字節(jié)提出 SuperClass 方法,直接利用分詞后的原始文本作為監(jiān)督分類標(biāo)簽,無需額外的文本過濾或篩選,比 CLIP 具有更高的訓(xùn)練效率。
項(xiàng)目地址:https://github.com/x-cls/superclass
01、方法介紹

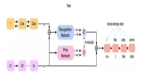
上圖是SuperClass和CLIP的對比圖,與對比學(xué)習(xí)的CLIP不同,SuperClass的主要思想是直接利用分詞的原始文本作為監(jiān)督分類標(biāo)簽。
在模型結(jié)構(gòu)上,SuperClass使用Vision Transformer (ViT) 作為視覺編碼器,并在其后添加全局平均池化層和線性層作為分類頭,輸出logit向量 x。監(jiān)督目標(biāo)來源于與圖像關(guān)聯(lián)的文字,并通過文本衍生的分類標(biāo)簽計(jì)算分類損失。
下面簡單介紹下模型相關(guān)的幾個(gè)主要部分:
文本作為標(biāo)簽
SuperClass直接將分詞后的文本用作K-hot標(biāo)簽,其中K是給定句子中的標(biāo)記數(shù)量。即,對于一個(gè)包含N對圖像I和文本標(biāo)題T的數(shù)據(jù)集 ,SuperClass直接使用現(xiàn)有的子詞級分詞器如CLIP或BERT(詞匯表大小為V)對文本進(jìn)行分詞,得到對應(yīng)的子詞ID集合C作為分類標(biāo)簽,并將其轉(zhuǎn)換為K-hot向量y(當(dāng)c在集合C中時(shí)
,SuperClass直接使用現(xiàn)有的子詞級分詞器如CLIP或BERT(詞匯表大小為V)對文本進(jìn)行分詞,得到對應(yīng)的子詞ID集合C作為分類標(biāo)簽,并將其轉(zhuǎn)換為K-hot向量y(當(dāng)c在集合C中時(shí) ,否則
,否則 )。這種方法無需預(yù)處理或手動設(shè)置閾值,避免了先前方法可能遇到的詞匯表溢出問題。
)。這種方法無需預(yù)處理或手動設(shè)置閾值,避免了先前方法可能遇到的詞匯表溢出問題。
分類損失
SuperClass的主要目標(biāo)是預(yù)訓(xùn)練視覺編碼器而非優(yōu)化多標(biāo)簽分類精度,在多標(biāo)簽場景中,SuperClass 采用 Softmax 損失(通過概率方式表示標(biāo)簽),并評估了包括 Softmax、BCE、soft margin、ASL 和 two - way 等多種損失函數(shù),結(jié)果發(fā)現(xiàn)簡單的 Softmax 損失取得了最佳預(yù)訓(xùn)練效果。這可能是因?yàn)楫?dāng)前多標(biāo)簽分類損失建立在標(biāo)簽精確且完整的假設(shè)基礎(chǔ)上,努力優(yōu)化正負(fù)類別之間的間隔。然而,圖像-文本數(shù)據(jù)中存在固有噪聲,且文本在完整描述圖像內(nèi)容方面的局限性,意味著圖像中所有對象并不總在配對文本中被提及。
損失函數(shù)定義如下:

其中 是歸一化加權(quán)標(biāo)簽。
是歸一化加權(quán)標(biāo)簽。
逆文檔頻率(IDF)作為類別權(quán)重
在子詞詞匯表中,每個(gè)詞都承載著不同程度的信息量,不同類別之間并非同等重要。此外,考慮到子詞詞典中包含許多語句常見詞,這些詞與視覺內(nèi)容無關(guān),并不能提供有效的監(jiān)督信息。
因此,攜帶大量信息的詞在訓(xùn)練過程中應(yīng)被賦予更大權(quán)重。SuperClass使用逆文檔頻率(Inverse Document Frequency 或 IDF )來衡量信息量,IDF 包含特定詞的樣本數(shù)量越少,該詞區(qū)分不同樣本的能力就越強(qiáng)。
SuperClass使用每個(gè)類別(子詞)的IDF統(tǒng)計(jì)作為相應(yīng)分類標(biāo)簽的權(quán)重,賦予不同類別不同的權(quán)重 :
:

其中∣D∣表示圖像-文本對的總數(shù),df(c)是子詞c的文檔頻率,即包含子詞c的文本數(shù)量。為了提高易用性和便攜性,SuperClass實(shí)現(xiàn)了在線IDF統(tǒng)計(jì),這些統(tǒng)計(jì)是在訓(xùn)練過程中計(jì)算的,消除了預(yù)先離線統(tǒng)計(jì)的需求。
特定詞:從文本描述中提取出來并用于構(gòu)建分類任務(wù)的子詞單元,它們根據(jù)自身的文檔頻率來決定各自的信息價(jià)值,并據(jù)此影響模型訓(xùn)練過程中的重要性分配。
文檔頻率(Document Frequency, df(c)):對于每一個(gè)特定詞(即子詞),其文檔頻率是指在整個(gè)訓(xùn)練數(shù)據(jù)集中包含該詞的文本數(shù)量。如果一個(gè)特定詞出現(xiàn)在很多文本中,那么它的df值就會很高;反之,若它只出現(xiàn)在少數(shù)文本里,則df值較低。
02、實(shí)驗(yàn)結(jié)果
由于不需要文本編碼器和構(gòu)建巨大的相似性矩陣,SuperClass 可以節(jié)省大約 50% 的顯存使用,加速 20% 以上。
為了更好度量預(yù)訓(xùn)練得到的視覺表征能力,文中固定住訓(xùn)練好的視覺模型的參數(shù),將其應(yīng)用到 Linear probing 、zero-shot 、10-shot 等分類任務(wù),同時(shí)接入到 LLM 做視覺和語言多模態(tài)下游任務(wù)進(jìn)行評測。
所有實(shí)驗(yàn)中均采用和 CLIP 相同的模型和訓(xùn)練參數(shù)設(shè)置,使用dataset數(shù)據(jù)集的一個(gè)標(biāo)準(zhǔn)子集進(jìn)行預(yù)訓(xùn)練,包含約13億個(gè)圖像-文本對。
與不同類型預(yù)訓(xùn)練方法比較
結(jié)果顯示,SuperClass 在各種模型大小和數(shù)據(jù)規(guī)模都取得不錯(cuò)的精度。與其他無監(jiān)督方法相比(包括基于對比或聚類的方法、基于重構(gòu)的方法和視覺-語言預(yù)訓(xùn)練方法), SuperClass 由于依靠語義信息作為監(jiān)督,訓(xùn)練數(shù)據(jù)多樣,在各種圖像分類數(shù)據(jù)集和不同分類任務(wù)上均取得更好精度,能夠?qū)崿F(xiàn)更好的視覺表征。
與 CLIP 相比,SuperClass 在使用相同數(shù)據(jù)集的訓(xùn)練參數(shù)設(shè)置下,圖像分類精度也基本優(yōu)于 CLIP 模型,比如 ImageNet linear probing 分類,SuperClass 比 CLIP 高 1.1% (85.0 vs. 83.9) 。考慮到 SuperClass 無需文本編碼器和構(gòu)建大規(guī)模 Batch Size ,使其更加適合應(yīng)用于大模型預(yù)訓(xùn)練場景。



與CLIP進(jìn)一步比較
CLIP 廣泛應(yīng)用的另一個(gè)場景是多模態(tài)理解,作為多模態(tài)大模型中的視覺編碼器,展現(xiàn)了很好的跨模態(tài)能力。在預(yù)訓(xùn)練過程中,SuperClass 的特征也對齊到了文本空間,同樣可應(yīng)用于多模態(tài)理解任務(wù)中。
本文采用了 2 種大語言模型,按照 clipcap 中的設(shè)置,使用 GPT-2 作為 Decoder ,在 COCO captions 上評估 image captioning 能力。根據(jù)表 3 的結(jié)果所示,SuperClass 取得了略優(yōu)于 CLIP 的 CIDEr 結(jié)果。根據(jù)表11的結(jié)果, SuperClass 在更多的多模態(tài)下游任務(wù)同樣也取得了更好的精度。總的來說,SuperClass具備更好的跨模態(tài)能力。


模型縮放能力
實(shí)驗(yàn)對比了 SuperClass 和 CLIP 在不同的模型大小和不同的數(shù)據(jù)規(guī)模下的精度,在純視覺任務(wù)和多模態(tài)下游任務(wù)上,SuperClass 和 CLIP 具有相似的 Scalability ;在 Text-VQA 任務(wù)上,SuperClass 明顯取得了比 CLIP 更好的精度和 Scalability。
- 模型規(guī)模的影響:圖2頂部行展示了不同模型規(guī)模下的分類和視覺-語言任務(wù)性能。隨著模型規(guī)模的增加,無論是分類任務(wù)還是LLaVA下游任務(wù),性能都有所提升。通常來說,給定相同的模型規(guī)模,使用SuperClass預(yù)訓(xùn)練的模型比CLIP具有更高的精度。
- 數(shù)據(jù)規(guī)模的影響:圖2底部行展示了不同訓(xùn)練樣本量下的性能變化。隨著觀察到的樣本數(shù)量增加,分類和下游任務(wù)的性能都有顯著提高。在相同數(shù)量的觀察樣本下,使用SuperClass預(yù)訓(xùn)練的模型通常比CLIP具有更高的準(zhǔn)確性,并且在下游任務(wù)上表現(xiàn)出相同或略好的擴(kuò)展行為。

消融實(shí)驗(yàn) (Ablations)
詞級分詞器 vs. 子詞級分詞器:表4展示了兩種分詞器在幾個(gè)下游任務(wù)上的性能差異。對于較小的模型(如ViT-S/16),詞級分詞器在分類任務(wù)上的表現(xiàn)優(yōu)于子詞級分詞器,可能是因?yàn)楫?dāng)模型容量有限時(shí),干凈的監(jiān)督信息更有助于收斂。然而,隨著模型規(guī)模的增大,無論是在分類任務(wù)還是視覺-語言任務(wù)上,子詞級分詞器逐漸超過了詞級分詞器。

不同的子詞級分詞器:表5比較了幾種子詞級分詞器(如CLIP、WordPiece、SentencePiece)在分類任務(wù)和LLaVA下游任務(wù)上的表現(xiàn)。最終選擇了CLIP中使用的分詞器。

分類損失函數(shù)的選擇:表6展示了不同分類損失函數(shù)(如Softmax、BCE、ASL、soft margin、two - way)的效果。最簡單的Softmax損失在多標(biāo)簽場景下大幅超越了其他損失函數(shù)。作者認(rèn)為這是因?yàn)楝F(xiàn)有的多標(biāo)簽分類損失假設(shè)標(biāo)簽既準(zhǔn)確又詳盡,而實(shí)際的圖像-文本數(shù)據(jù)存在大量噪聲,單個(gè)文本無法捕捉所有圖像內(nèi)容。

IDF權(quán)重的作用:表7探討了是否使用IDF作為類別權(quán)重以及移除停用詞的影響。結(jié)果顯示,使用IDF權(quán)重可以顯著提高分類任務(wù)的準(zhǔn)確性,而在視覺-語言任務(wù)上的影響不大。保留停用詞有助于視覺編碼器在分類任務(wù)上獲得更好的性能。

不同觀察樣本量的影響:表8展示了不同觀察樣本量對分類和視覺-語言任務(wù)性能的影響。隨著觀察樣本量的增加,尤其是在分類和LLaVA下游任務(wù)上,模型的性能有明顯提升。

不同模型規(guī)模的影響:表9展示了不同模型規(guī)模對分類和視覺-語言任務(wù)性能的影響。隨著模型規(guī)模的增加,無論是分類任務(wù)還是LLaVA下游任務(wù),性能都有所提升。通常來說,給定相同的模型規(guī)模,使用SuperClass預(yù)訓(xùn)練的模型比CLIP具有更高的精度。

03、總結(jié)
最后瞎寫幾句,從信息論的角度,SuperClass通過將每個(gè)子詞視為一個(gè)類別標(biāo)簽,并賦予相應(yīng)的權(quán)重(如IDF),實(shí)際上是在最大化圖像特征與這些子詞之間的互信息。互信息I(X;Y) 是衡量兩個(gè)隨機(jī)變量之間關(guān)聯(lián)程度的一個(gè)度量,它反映了觀察到一個(gè)變量后能減少另一個(gè)變量不確定性的程度。具體來說,當(dāng)模型學(xué)習(xí)到某個(gè)特定子詞時(shí),就意味著減少了對于該子詞所代表概念在圖像中的不確定性。因此,通過這種方式,SuperClass確保了那些出現(xiàn)頻率較低但信息量較大的詞匯得到了足夠的重視,從而增強(qiáng)了模型對于圖像內(nèi)容的理解能力。
相比之下,對比學(xué)習(xí)通常涉及構(gòu)造正負(fù)樣本對,并通過最小化正樣本間的距離同時(shí)最大化負(fù)樣本間的距離來進(jìn)行優(yōu)化。這種做法雖然有助于提高模型的區(qū)分能力,但也引入了一定程度上的間接性。也就是說,模型不僅要學(xué)會正確地區(qū)分正負(fù)樣本,還要理解這些樣本背后隱藏的關(guān)系。而在SuperClass中,由于直接使用了文本令牌作為監(jiān)督信號,信息傳遞變得更加直接和明確。模型可以直接從輸入數(shù)據(jù)中提取有用信息,并將其映射到相應(yīng)的類別標(biāo)簽上,減少了中間環(huán)節(jié)所帶來的不確定性。
很有意思的一篇工作,SuperClass作為一種極其簡單有效的方法,在預(yù)訓(xùn)練視覺編碼器方面不僅能夠?qū)崿F(xiàn)與對比學(xué)習(xí)方法相媲美的性能,而且在計(jì)算效率和擴(kuò)展性方面也表現(xiàn)出色。這些結(jié)果為視覺和多模態(tài)相關(guān)的任務(wù)提供了有力支持。