生圖加入CoT,性能提升80%!微軟港中文打造天才畫手
AI繪畫火爆的當下,大家都有過這樣的體驗:滿心歡喜地輸入一段描述,滿心期待著生成超酷炫的圖像,結果AI給出的作品卻差強人意,不是沒get到重點,就是細節各種「翻車」。
今天要介紹的ImageGen-CoT技術,就像是給AI繪畫開了「外掛」,讓它變得超智能,創作更輕松!
來自微軟和港中文的華人研究者提出了ImageGen-CoT,用思維鏈(CoT)推理提升文本到圖像上下文學習能力。

論文鏈接:https://arxiv.org/abs/2503.19312
它在AI繪畫生成圖像之前,先進行一番思考,梳理出推理步驟,再去創作圖像,就像寫作文前先列提綱一樣。
人類在面對多模態信息時,比如看到「皮革裝訂的書」「皮革蘋果」,再被要求畫「皮革盒子」,能輕松推斷出 「皮革」這個關鍵特征,并應用到新的創作中。

但現有的多模態大語言模型(MLLM)在處理這類文本到圖像上下文學習(T2I-ICL)任務時,卻表現得差強人意,經常抓不住重點,生成的圖像和預期相差甚遠。
ImageGen-CoT的核心就是在圖像生成之前引入思維鏈(CoT)推理。
想象一下,AI就像一個小畫家,以前畫畫的時候,拿到描述就直接動手,毫無規劃,所以畫得亂七八糟。
現在有了ImageGen-CoT,小畫家會先思考:「這個描述里有什么關鍵信息?之前有沒有類似的描述,它們有什么共同點?」
想清楚這些之后,再開始畫畫,這樣畫出來的作品自然更符合期待。
大量的實驗表明,該方法顯著提高了模型性能,SEED-X微調后在T2I-ICL任務上的性能提升高達80%。
使用ImageGen-CoT進行微調的SEED-X在CoBSAT和DreamBench++上分別提高了89%和114%。

ImageGen-CoT如何構建
接下來,詳細介紹ImageGen-CoT框架,首先,介紹ImageGen-CoT的公式化表述。
其次,描述用于收集高質量ImageGen-CoT數據集的自動流程。詳細闡述數據集的公式化表述以及用于使用收集到的數據集對模型進行微調的損失函數。
最后,探索在推理過程中提高模型性能的各種策略,提出一種新穎的混合擴展方法,應對上下文理解和生成方面的挑戰。
兩階段推理:穩扎穩打生成圖像
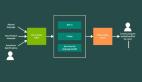
ImageGen-CoT 采用了兩階段推理的方式。
第一階段,模型會根據輸入的文本和指令,生成ImageGen-CoT推理鏈R。
這個推理鏈就像是畫家畫畫前打的草稿,把圖像的關鍵信息、創作思路都梳理清楚。
第二階段,模型把原始輸入X、生成的推理鏈R,還有強制圖像生成標記<image>結合起來,生成最終的目標圖像I。
用公式表示就是:

這里,M代表統一的MLLM,⊕表示連接操作。
這種兩階段的設計,能確保圖像生成更穩定、更準確。
數據集構建
為了能更好地學習,ImageGen-CoT構建了高質量的數據集。
首先,研究人員從現有的T2I-ICL任務訓練數據集中收集各種指令,建立一個指令池。
然后,開啟自動數據集構建流程。在這個流程里,MLLM身兼數職。它先是作為生成器,生成N個包含ImageGen-CoT和下一幅圖像提示的輸出。
然后,MLLM充當選擇器,從N個候選圖像中選擇最佳圖像。
如果圖像達到了質量標準,或者達到了最大迭代次數,流程終止并輸出相應的ImageGen-CoT和圖像對。
要是沒達標,MLLM就會化身為評論者,給這幅圖像挑挑刺,指出哪里畫得不好。
最后,MLLM再作為優化器,根據評論修改提示,然后重新生成圖像,這個過程不斷循環,直到選出最完美的圖像和對應的ImageGen-CoT。

通過這樣嚴格的篩選,構建出的ImageGen-CoT數據集質量超高,每一個樣本都是精心挑選出來的。
訓練與優化
數據集構建好之后,就要用它來訓練MLLM啦。
訓練時,研究人員把ImageGen-CoT數據集分成了兩個部分。
第一部分用來訓練模型生成ImageGen-CoT文本,第二部分訓練模型根據生成的ImageGen-CoT文本生成圖像。
如果模型使用的是離散視覺標記,就用和語言建模類似的損失函數:

其中,y_i是ImageGen-CoT文本中的第i個標記, 表示前面的標記,X是輸入,N是ImageGen-CoT序列中的標記總數。
表示前面的標記,X是輸入,N是ImageGen-CoT序列中的標記總數。
要是用的是連續視覺嵌入,就采用均方誤差損失函數:

其中, 是生成的視覺嵌入,z是相應的目標視覺嵌入。
是生成的視覺嵌入,z是相應的目標視覺嵌入。
通過訓練,模型生成準確ImageGen-CoT的能力越來越強,圖像生成的質量也大幅提升。
研究人員在測試階段也進行了優化,探索了三種測試時擴展策略:單CoT擴展、多CoT擴展和混合擴展。
單CoT擴展就是從一個ImageGen-CoT生成多個圖像變體;多CoT擴展則是生成多個不同的ImageGen-CoT思維鏈,每個思維鏈生成一幅圖像。
混合擴展更厲害,首先生成多個ImageGen-CoT思維鏈,然后為每個思維鏈創建多個圖像變體。
實驗證明,混合擴展策略效果最好。在理解和生成圖像兩方面都能快速提升,為復雜多模態任務的性能優化開辟了新道路。
ImageGen-CoT效果有多驚艷?
為了驗證ImageGen-CoT,研究人員在CoBSAT和DreamBench++這兩個權威的T2I-ICL基準測試中進行了實驗。
測試成績亮眼
在CoBSAT測試中,使用ImageGen-CoT后,SEED-LLaMA的平均分數從0.254提高到0.283,相對提升了11.4%。
SEED-X的提升更明顯,從0.349提高到0.439,相對提升25.8%。
經過ImageGen-CoT數據集微調后,SEED-LLaMA的平均分數達到0.291,比基線提升了14.6%。
SEED-X更是飆升到0.658,相對提升高達88.5%。

在DreamBench++測試中,同樣成績斐然。
SEED-X使用ImageGen-CoT后,CP?PF分數從0.188提升到0.347,相對提升84.6%。
微調后,SEED-X的CP?PF分數達到0.403,相對提升114.4%;SEED-LLaMA微調后的CP?PF分數也從0.078提升到0.101,相對提升29.5%。

這充分證明了ImageGen-CoT在提升模型性能方面的強大實力。
測試時擴展
為了進一步提升模型性能,研究人員探索了各種測試時擴展策略。
采用「N選優」方法,讓模型生成多個圖像變體,并通過真實指標評估(pass@N)。
作為基線方法,首先對普通的SEED-X模型進行實驗,通過改變種子值生成多個圖像。
然后,使用ImageGen-CoT 數據集微調后的SEED-X的三種高級擴展策略:
- 多CoT擴展,生成多個不同的ImageGen-CoT思維鏈,每個思維鏈生成一幅圖像。
- 單CoT擴展,從單個ImageGen-CoT思維鏈生成多個圖像變體。
- 混合擴展,這是一種新穎的方法,結合了兩種策略的優勢,即首先生成多個ImageGen-CoT思維鏈,然后為每個思維鏈生成多個圖像變體。
實驗揭示了三個關鍵發現。
第一,普通的SEED-X@16基線(在CoBSAT上得分為 0.67,在Dreambench++上得分為0.312 )甚至不如最簡單的擴展策略(例如,在CoBSAT@2上得分為0.747 ),這凸顯了整合ImageGen-CoT的必要性。
第二,多CoT擴展在性能上與單CoT擴展相當,證明了生成多樣化的推理路徑與從單個CoT生成不同輸出的效果相同。
最后,混合擴展在各個基準測試中始終獲得最高分數。在N=16時,混合擴展將CoBSAT的性能提高到0.909(比單CoT擴展高1.9% ),將Dreambench++的性能提高到0.543(比單CoT擴展高0.8% )。

ImageGen-CoT的整合實現了在理解和生成維度上的有效雙向擴展。這種雙軸可擴展性為優化復雜多模態任務中的 MLLM性能開辟了新途徑。
定性結果展示
ImageGen-CoT的效果在實際生成的圖像中也體現得淋漓盡致。
比如在生成「帶蕾絲圖案的書」的圖像時,基線SEED-X只能畫出一個基本的書的形狀,完全沒注意到「蕾絲」這個關鍵屬性。
使用ImageGen-CoT提示后,由于模型理解能力有限,生成的圖像質量反而更差了。
但經過ImageGen-CoT數據集微調后,模型成功捕捉到了「蕾絲」屬性,生成了一本精美的蕾絲書,細節滿滿。

生成「在石頭上、在花園里、表情悲傷的雞蛋」的圖像時,基線SEED-X生成的雞蛋只是簡單張嘴,完全忽略了「在石頭上」「在花園里」這些要求和特征。
使用ImageGen-CoT提示后,雖然雞蛋放在了石頭上,但還是缺少面部表情和花園環境。
而微調后的模型則完美理解了所有任務要求,生成的圖像中,雞蛋穩穩地放在石頭上,周圍是美麗的花園,雞蛋還帶著悲傷的表情,和輸入的描述一模一樣。
這些對比,讓我們清晰地看到了ImageGen-CoT如何讓AI繪畫從「青銅」變成「王者」。
背后的秘密:提升理解能力
為什么ImageGen-CoT能夠提升模型性能呢?關鍵在于它增強了模型的理解能力。
研究人員讓模型為下一幅圖像生成文本描述,以此來評估模型的理解能力。
以SEED-X為例,通過提示應用ImageGen-CoT時,其文本生成模式的平均分數從0.174提高到0.457,用ImageGen-CoT數據集微調后,更是提升到0.760。

同時,增強的理解能力也改善了圖像生成,SEED-X的圖像生成平均分數從0.349提升到0.439,微調后進一步提升到0.658。
理解能力的提升也直接帶動了圖像生成性能的提高,這說明ImageGen-CoT讓模型更好地理解了輸入內容,生成更符合要求的圖像。