譯者 | 布加迪
審校 | 重樓
本文將探討如何構(gòu)建一個(gè)RAG系統(tǒng)并使其完全由語音激活。
RAG(檢索增強(qiáng)生成)是一種將外部知識(shí)用于額外上下文以饋入到大語言模型(LLM),從而提高模型準(zhǔn)確性和相關(guān)性的技術(shù)。這是一種比不斷微調(diào)模型可靠得多的方法,可以改善生成式AI的結(jié)果。
傳統(tǒng)上,RAG系統(tǒng)依賴用戶文本查詢來搜索矢量數(shù)據(jù)庫。然后將檢索到的相關(guān)文檔用作生成式AI的上下文輸入,生成式AI負(fù)責(zé)生成文本格式的結(jié)果。然而,我們可以進(jìn)一步擴(kuò)展RAG系統(tǒng),以便能夠接受和生成語音形式的輸出。
本文將探討如何構(gòu)建一個(gè)RAG系統(tǒng)并使其完全由語音激活。
構(gòu)建一個(gè)完全由語音激活的RAG系統(tǒng)
我在本文中假設(shè)讀者對(duì)LLM和RAG系統(tǒng)已有一定的了解,因此不會(huì)進(jìn)一步解釋它們。
要構(gòu)建具有完整語音功能的RAG系統(tǒng),我們將圍繞三個(gè)關(guān)鍵組件來構(gòu)建它:
- 語音接收器和轉(zhuǎn)錄
- 知識(shí)庫
- 音頻文件響應(yīng)生成
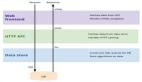
總的來說,項(xiàng)目工作流程如下圖所示:
建一個(gè)完全本地的語音激活的實(shí)用RAG系統(tǒng)-AI.x社區(qū)")
如果你已準(zhǔn)備好,不妨開始準(zhǔn)備這個(gè)項(xiàng)目成功所需要的一切。
首先,我們不會(huì)在這個(gè)項(xiàng)目中使用Notebook IDE,因?yàn)槲覀兿M鸕AG系統(tǒng)像生產(chǎn)系統(tǒng)一樣工作。因此,應(yīng)該準(zhǔn)備一個(gè)標(biāo)準(zhǔn)的編程語言IDE,比如Visual Studio Code(VS Code)。
接下來,我們還想為項(xiàng)目創(chuàng)建一個(gè)虛擬環(huán)境。你可以使用任何方法,比如Python或Conda。
python -m venv rag-env-audio準(zhǔn)備好虛擬環(huán)境后,我們安裝本教程所需的所有庫。
pip install openai-whisper chromadb sentence-transformers sounddevice numpy scipy PyPDF2 transformers torch langchain-core langchain-community如果你可以訪問GPU,也可以下載PyTorch庫的GPU版本。
pip install torch torchaudio --index-url https://download.pytorch.org/whl/cu118一切準(zhǔn)備就緒后,我們將開始構(gòu)建一個(gè)語音激活的RAG系統(tǒng)。要注意的是,包含所有代碼和數(shù)據(jù)集的項(xiàng)目存儲(chǔ)庫位于該存儲(chǔ)庫中:https://github.com/CornelliusYW/RAG-To-Know/tree/main/RAG-Project/RAG-Voice-Activated。
我們首先使用以下代碼導(dǎo)入所有必要的庫和環(huán)境變量。
import os
import whisper
import chromadb
from sentence_transformers import SentenceTransformer
import sounddevice as sd
import numpy as np
from scipy.io.wavfile import write
from sklearn.metrics.pairwise import cosine_similarity
from transformers import AutoModelForCausalLM, AutoTokenizer
from langchain_text_splitters import RecursiveCharacterTextSplitter
import torch
AUDIO_FILE = "user_input.wav"
RESPONSE_AUDIO_FILE = "response.wav"
PDF_FILE = "Insurance_Handbook_20103.pdf"
SAMPLE_RATE = 16000
WAKE_WORD = "Hi"
SIMILARITY_THRESHOLD = 0.4
MAX_ATTEMPTS = 5將對(duì)各自代碼中使用的所有變量進(jìn)行解釋。現(xiàn)在,暫且保持原樣。
在導(dǎo)入所有必要的庫之后,我們將為RAG系統(tǒng)設(shè)置所有必要的函數(shù)。我將逐個(gè)分析,這樣你就能理解我們的項(xiàng)目中發(fā)生了什么。
第一步是創(chuàng)建一項(xiàng)功能來記錄輸入語音,并將語音轉(zhuǎn)錄成文本數(shù)據(jù)。我們將使用聲音設(shè)備庫用于記錄語音,使用OpenAI Whisper用于音頻轉(zhuǎn)錄。
# For recording audio input.
def record_audio(filename, duration=5, samplerate=SAMPLE_RATE):
print("Listening... Speak now!")
audio = sd.rec(int(duration * samplerate), samplerate=samplerate, channels=1, dtype='float32')
sd.wait()
print("Recording finished.")
write(filename, samplerate, (audio * 32767).astype(np.int16))
# Transcribe the Input audio into text
def transcribe_audio(filename):
print("Transcribing audio...")
model = whisper.load_model("base.en")
result = model.transcribe(filename)
return result["text"].strip().lower()上述函數(shù)將成為接受和返回作為文本數(shù)據(jù)的語音的基礎(chǔ)。我們將在這個(gè)項(xiàng)目中多次使用它們,所以請牢記這一點(diǎn)。
我們將為RAG系統(tǒng)創(chuàng)建一個(gè)入口功能,準(zhǔn)備好接受音頻的功能。在下一段代碼中,我們在使用WAKE_WORD(喚醒詞)訪問系統(tǒng)之前創(chuàng)建一個(gè)語音激活函數(shù)。這個(gè)喚醒詞可以是任何內(nèi)容,你可以根據(jù)需要進(jìn)行設(shè)置。
上述語音激活背后的想法是,如果我們錄制的轉(zhuǎn)錄語音與喚醒詞匹配,RAG系統(tǒng)就會(huì)被激活。然而,如果轉(zhuǎn)錄需要完全匹配喚醒詞,這將是不可行的,因?yàn)檗D(zhuǎn)錄系統(tǒng)很有可能生成不同格式的文本結(jié)果。為此我們可以使轉(zhuǎn)錄輸出實(shí)現(xiàn)標(biāo)準(zhǔn)化。然而我想使用嵌入相似度,這樣即使喚醒詞的組成略有不同,系統(tǒng)仍然會(huì)被激活。
# Detecting Wake Word to activate the RAG System
def detect_wake_word(max_attempts=MAX_ATTEMPTS):
print("Waiting for wake word...")
text_embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
wake_word_embedding = text_embedding_model.encode(WAKE_WORD).reshape(1, -1)
attempts = 0
while attempts = SIMILARITY_THRESHOLD:
print(f"Wake word detected: {WAKE_WORD}")
return True
attempts += 1
print(f"Attempt {attempts}/{max_attempts}. Please try again.")
print("Wake word not detected. Exiting.")
return False通過結(jié)合WAKE_WORD和SIMILARITY_THRESHOLD變量,我們將最終獲得語音激活功能。
接下來,不妨使用PDF文件構(gòu)建知識(shí)庫。為此,我們將準(zhǔn)備一個(gè)函數(shù),用于從該文件中提取文本并將其分割成塊。
def load_and_chunk_pdf(pdf_file):
from PyPDF2 import PdfReader
print("Loading and chunking PDF...")
reader = PdfReader(pdf_file)
all_text = ""
for page in reader.pages:
text = page.extract_text()
if text:
all_text += text + "\n"
# Split the text into chunks
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=250, # Size of each chunk
chunk_overlap=50, # Overlap between chunks to maintain context
separators=["\n\n", "\n", " ", ""]
)
chunks = text_splitter.split_text(all_text)
return chunks你可以將塊大小替換成你想要的。沒有使用確切的數(shù)字,所以用它們進(jìn)行試驗(yàn),看看哪個(gè)是最好的參數(shù)。
然后來自上述函數(shù)的塊被傳遞到矢量數(shù)據(jù)庫中。我們將使用ChromaDB矢量數(shù)據(jù)庫和SenteceTransformer來訪問嵌入模型。
def setup_chromadb(chunks):
print("Setting up ChromaDB...")
client = chromadb.PersistentClient(path="chroma_db")
text_embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# Delete existing collection (if needed)
try:
client.delete_collection(name="knowledge_base")
print("Deleted existing collection: knowledge_base")
except Exception as e:
print(f"Collection does not exist or could not be deleted: {e}")
collection = client.create_collection(name="knowledge_base")
for i, chunk in enumerate(chunks):
embedding = text_embedding_model.encode(chunk).tolist()
collection.add(
ids=[f"chunk_{i}"],
embeddings=[embedding],
metadatas=[{"source": "pdf", "chunk_id": i}],
documents=[chunk]
)
print("Text chunks and embeddings stored in ChromaDB.")
return collection
Additionally, we will prepare the function for retrieval with the text query to ChromaDB as welll
def query_chromadb(collection, query, top_k=3):
"""Query ChromaDB for relevant chunks."""
text_embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
query_embedding = text_embedding_model.encode(query).tolist()
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
relevant_chunks = [chunk for sublist in results["documents"] for chunk in sublist]
return relevant_chunks然后,我們需要準(zhǔn)備生成功能來完成RAG系統(tǒng)。在本例中,我將使用托管在HuggingFace中的Qwen -1.5-0.5B-Chat模型。你可以根據(jù)需要調(diào)整提示和生成模型。
def generate_response(query, context_chunks):
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "Qwen/Qwen1.5-0.5B-Chat"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Format the prompt with the query and context
context = "\n".join(context_chunks)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f"Use the following context to answer the question:\n\nContext:\n{context}\n\nQuestion: {query}\n\nAnswer:"}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer(
[text],
return_tensors="pt",
padding=True,
truncation=True
).to(device)
# Generate the response
generated_ids = model.generate(
model_inputs.input_ids,
attention_mask=model_inputs.attention_mask,
max_new_tokens=512,
pad_token_id=tokenizer.eos_token_id
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
return response最后,令人興奮的地方在于使用文本到語音模型將生成的響應(yīng)轉(zhuǎn)換成音頻文件。就本例而言,我們將使用托管在HuggingFace中的Suno Bark模型。在生成音頻之后,我們將播放音頻響應(yīng)以完成整條管道。
def text_to_speech(text, output_file):
from transformers import AutoProcessor, BarkModel
print("Generating speech...")
processor = AutoProcessor.from_pretrained("suno/bark-small")
model = BarkModel.from_pretrained("suno/bark-small")
inputs = processor(text, return_tensors="pt")
audio_array = model.generate(**inputs)
audio = audio_array.cpu().numpy().squeeze()
# Save the audio to a file
write(output_file, 22050, (audio * 32767).astype(np.int16))
print(f"Audio response saved to {output_file}")
return audio
def play_audio(audio, samplerate=22050):
print("Playing response...")
sd.play(audio, samplerate=samplerate)
sd.wait()這就是完成完全由語音激活的RAG管道需要的所有功能。不妨把它們結(jié)合在一起,形成連貫有序的結(jié)構(gòu)。
def main():
# Step 1: Load and chunk the PDF
chunks = load_and_chunk_pdf(PDF_FILE)
# Step 2: Set up ChromaDB
collection = setup_chromadb(chunks)
# Step 3: Detect wake word with embedding similarity
if not detect_wake_word():
return # Exit if wake word is not detected
# Step 4: Record and transcribe user input
record_audio(AUDIO_FILE, duration=5)
user_input = transcribe_audio(AUDIO_FILE)
print(f"User Input: {user_input}")
# Step 5: Query ChromaDB for relevant chunks
relevant_chunks = query_chromadb(collection, user_input)
print(f"Relevant Chunks: {relevant_chunks}")
# Step 6: Generate response using a Hugging Face model
response = generate_response(user_input, relevant_chunks)
print(f"Generated Response: {response}")
# Step 7: Convert response to speech, save it, and play it
audio = text_to_speech(response, RESPONSE_AUDIO_FILE)
play_audio(audio)
# Clean up
os.remove(AUDIO_FILE) # Delete the temporary audio file
if __name__ == "__main__":
main()我已將整個(gè)代碼保存在一個(gè)名為app.py的腳本中,我們可以使用以下代碼激活系統(tǒng)。
python app.py自己嘗試一下,你將獲得可用于審閱的響應(yīng)音頻文件。
這就是構(gòu)建帶有語音激活的本地RAG系統(tǒng)所需的全部內(nèi)容。你可以為系統(tǒng)構(gòu)建一個(gè)應(yīng)用程序并將其部署到生產(chǎn)環(huán)境中,進(jìn)一步完善項(xiàng)目。
結(jié)論
構(gòu)建具有語音激活的RAG系統(tǒng)涉及一系列先進(jìn)的技術(shù)以及協(xié)同工作如同一個(gè)模型的多個(gè)模型。本項(xiàng)目利用檢索和生成函數(shù)來構(gòu)建RAG系統(tǒng),通過幾個(gè)步驟嵌入音頻功能,增添另一層。我們打下基礎(chǔ)后,就可以根據(jù)需求進(jìn)一步完善項(xiàng)目。
原文標(biāo)題:Creating a Useful Voice-Activated Fully Local RAG System,作者:Cornellius Yudha Wijaya