













語(yǔ)言模型新范式:首個(gè)8B擴(kuò)散大語(yǔ)言模型LLaDA發(fā)布,性能比肩LLaMA 3
本文由中國(guó)人民大學(xué)高瓴人工智能學(xué)院李崇軒、文繼榮教授團(tuán)隊(duì)和螞蟻集團(tuán)共同完成。共同一作聶燊和朱峰琪是中國(guó)人民大學(xué)高瓴人工智能學(xué)院的博士生,導(dǎo)師為李崇軒副教授,論文為二者在螞蟻實(shí)習(xí)期間完成。螞蟻集團(tuán)張曉露、胡俊,人民大學(xué)林衍凱、李崇軒為共同項(xiàng)目負(fù)責(zé)人。李崇軒副教授為唯一通訊作者。LLaDA 基于李崇軒課題組的前期工作 RADD [1] 和 SMDM [2]。目前這兩篇論文均已被 ICLR2025 接收。
近年來(lái),大語(yǔ)言模型(LLMs)取得了突破性進(jìn)展,展現(xiàn)了諸如上下文學(xué)習(xí)、指令遵循、推理和多輪對(duì)話等能力。目前,普遍的觀點(diǎn)認(rèn)為其成功依賴于自回歸模型的「next token prediction」范式。這種方法通過(guò)預(yù)測(cè)下一個(gè)詞的方式拆解語(yǔ)言聯(lián)合概率,形式化如下:
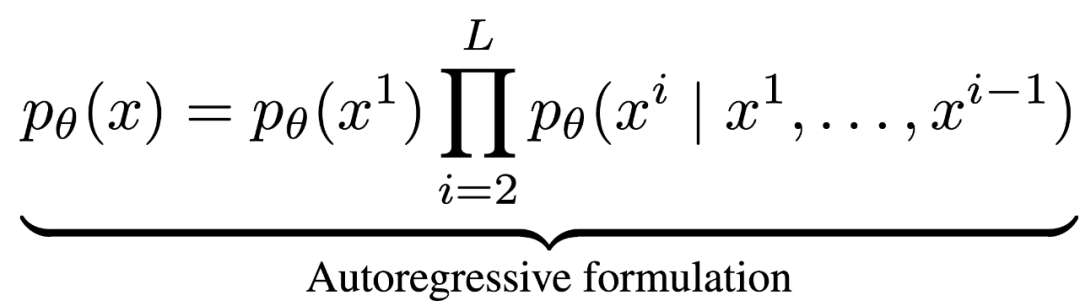
最近,人大高瓴李崇軒、文繼榮團(tuán)隊(duì)和螞蟻集團(tuán)的研究員提出了一種新的洞察:大語(yǔ)言模型展現(xiàn)的語(yǔ)言智能(如上下文學(xué)習(xí)、指令遵循、推理和多輪對(duì)話等能力)并非自回歸機(jī)制獨(dú)有,而在于背后所遵循的生成建模原則,即通過(guò)最大似然估計(jì)(或最小化 KL 散度)來(lái)逼近真實(shí)語(yǔ)言分布。

正是基于這一理念,團(tuán)隊(duì)開發(fā)了 LLaDA(Large Language Diffusion with mAsking)—— 一種基于掩碼擴(kuò)散模型的語(yǔ)言生成方法。與傳統(tǒng)自回歸模型不同,LLaDA 采用了前向掩碼加噪和反向去噪的機(jī)制,不僅突破了單向生成的局限,還通過(guò)優(yōu)化似然下界,提供了一種不同于自回歸的、原理嚴(yán)謹(jǐn)?shù)母怕式7桨浮?/span>
通過(guò)大規(guī)模實(shí)驗(yàn),LLaDA 8B 在可擴(kuò)展性、下游語(yǔ)言任務(wù)中全面媲美現(xiàn)代大語(yǔ)言模型,如 Llama3 8B。這些結(jié)果一定程度上表明,LLMs 的核心能力(如可擴(kuò)展性、上下文學(xué)習(xí)和指令遵循)并非自回歸模型獨(dú)有,而是源自于合理的生成建模策略和充分的模型數(shù)據(jù)規(guī)模。LLaDA 不僅提出了一種新的大語(yǔ)言模型的概率建模框架,也有助于我們進(jìn)一步理解語(yǔ)言智能。

- 論文鏈接:https://arxiv.org/abs/2502.09992
- 項(xiàng)目地址:https://ml-gsai.github.io/LLaDA-demo/
- 代碼倉(cāng)庫(kù):https://github.com/ML-GSAI/LLaDA
團(tuán)隊(duì)預(yù)計(jì)近期開源推理代碼和 LLaDA 8B Base 權(quán)重,后續(xù)還將開源 LLaDA 8B Instruct 權(quán)重。
性能展示
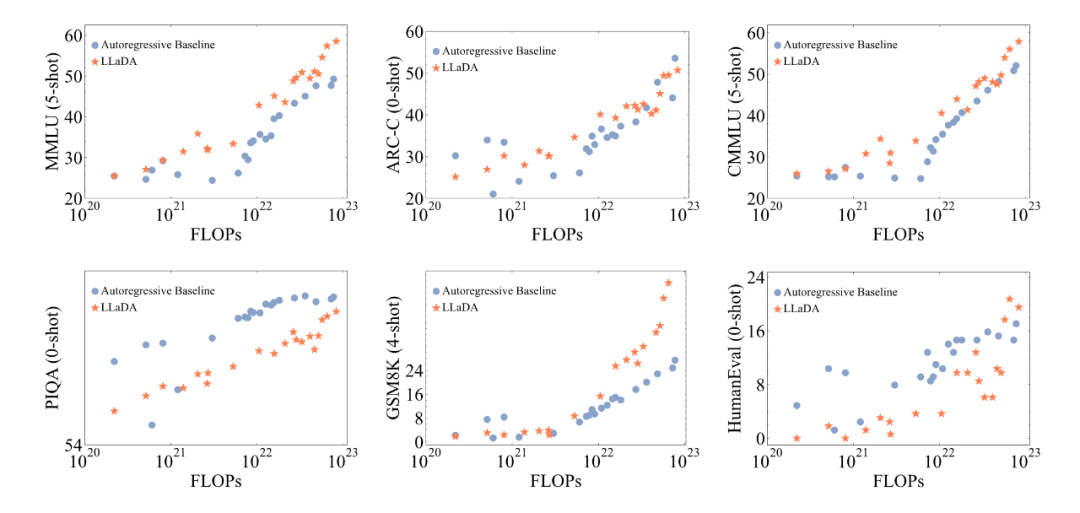
卓越的可擴(kuò)展性。在多個(gè)語(yǔ)言任務(wù)上,LLaDA 和自回歸模型基線進(jìn)行了嚴(yán)格對(duì)比。實(shí)驗(yàn)表明,在相同的數(shù)據(jù)條件下,LLaDA 在 MMLU、GSM8K 等多個(gè)任務(wù)上展現(xiàn)了與自回歸模型相當(dāng)?shù)谋憩F(xiàn),證明了其在高計(jì)算成本下的強(qiáng)大擴(kuò)展能力。即使在某些相對(duì)薄弱的任務(wù)上,隨著模型規(guī)模的增大,LLaDA 也能迅速縮小與自回歸模型之間的性能差距。
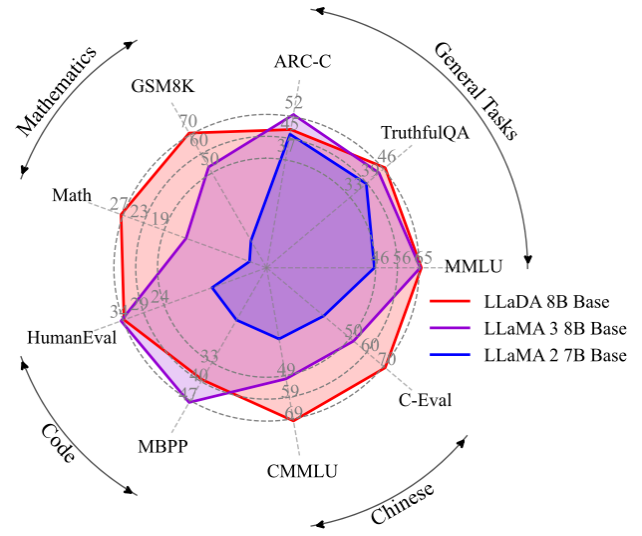
出色的上下文學(xué)習(xí)與指令遵循能力。在涵蓋 15 個(gè)熱門基準(zhǔn)測(cè)試(包括通用任務(wù)、數(shù)學(xué)、代碼及中文任務(wù))的評(píng)測(cè)中,預(yù)訓(xùn)練了 2.3T tokens 的 LLaDA 8B Base 模型憑借強(qiáng)大的 zero/few-shot 學(xué)習(xí)能力,整體表現(xiàn)超越了 LLaMA2 7B Base (預(yù)訓(xùn)練 tokens 2T),并與 LLaMA3 8B Base (預(yù)訓(xùn)練 tokens 15T)媲美。在經(jīng)過(guò)監(jiān)督微調(diào)(SFT)后,LLaDA 的指令遵循能力得到了顯著提升,能在多輪對(duì)話及跨語(yǔ)種生成任務(wù)中保持連貫性和高質(zhì)量輸出,充分展現(xiàn)了其對(duì)復(fù)雜語(yǔ)言指令的良好理解和響應(yīng)能力。
下圖是在一些熱門基準(zhǔn)上 LLaDA 和 LLaMA3 以及 LLaMA2 的性能對(duì)比,詳細(xì)結(jié)果請(qǐng)參見論文。

平衡的正向與逆向推理能力。傳統(tǒng)自回歸模型在逆向推理任務(wù)中常常存在「逆向詛咒」[3] 問(wèn)題,好比當(dāng)模型在「A is B」數(shù)據(jù)上訓(xùn)練之后無(wú)法回答「B is A」。而 LLaDA 則通過(guò)雙向的概率建模機(jī)制,有效克服了這一局限。在詩(shī)歌補(bǔ)全任務(wù)中,LLaDA 在正向生成與逆向生成上均取得了均衡表現(xiàn),尤其在逆向任務(wù)中明顯超越了 GPT-4o 和其他對(duì)比模型,展現(xiàn)了強(qiáng)大的逆向推理能力。

多場(chǎng)景下的實(shí)際應(yīng)用效果。除了標(biāo)準(zhǔn)測(cè)試指標(biāo)外,我們?cè)诙噍唽?duì)話、數(shù)學(xué)題解和跨語(yǔ)言文本生成等實(shí)際應(yīng)用場(chǎng)景中也看到了 LLaDA 的出色表現(xiàn)。無(wú)論是復(fù)雜問(wèn)題求解、指令翻譯,還是創(chuàng)意詩(shī)歌生成,LLaDA 都能準(zhǔn)確把握上下文并生成流暢、合理的回答,充分驗(yàn)證了其在非自回歸生成模式下的應(yīng)用前景。
下圖是 LLaDA 在回答用戶提問(wèn)的一個(gè)例子,用戶輸入的 prompt 是「Explain what artificial intelligence is」。LLaDA 采取了一種不同于自回歸模型從左到右的生成方式。

下圖是 LLaDA 同用戶進(jìn)行多輪對(duì)話的場(chǎng)景。LLaDA 不僅正確回答了詩(shī)歌《未選擇的路》的前兩句,而且成功將英文翻譯成中文和德語(yǔ),并且按照用戶要求創(chuàng)作了一首五行,且每一行均以字母 C 開頭的詩(shī)歌。

核心方法
下圖展示了 LLaDA 的預(yù)訓(xùn)練、監(jiān)督微調(diào)以及采樣過(guò)程。

概率建模框架。LLaDA 通過(guò)前向過(guò)程和反向過(guò)程來(lái)定義模型分布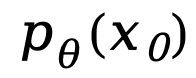 。在前向過(guò)程中,對(duì)文本
。在前向過(guò)程中,對(duì)文本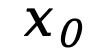 中的 tokens 進(jìn)行逐步獨(dú)立掩碼,直到在 t=1 時(shí)整個(gè)序列被完全掩碼。當(dāng)
中的 tokens 進(jìn)行逐步獨(dú)立掩碼,直到在 t=1 時(shí)整個(gè)序列被完全掩碼。當(dāng)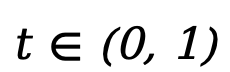 時(shí),序列
時(shí),序列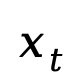 是部分掩碼的,每個(gè) token 有概率 t 被掩碼,或者以概率 1-t 保留原樣。而反向過(guò)程則通過(guò)在 t 從 1 逐步減小到 0 的過(guò)程中反復(fù)預(yù)測(cè)被掩碼的 tokens,從而恢復(fù)出數(shù)據(jù)分布。LLaDA 的核心是一個(gè)參數(shù)化的掩碼預(yù)測(cè)器
是部分掩碼的,每個(gè) token 有概率 t 被掩碼,或者以概率 1-t 保留原樣。而反向過(guò)程則通過(guò)在 t 從 1 逐步減小到 0 的過(guò)程中反復(fù)預(yù)測(cè)被掩碼的 tokens,從而恢復(fù)出數(shù)據(jù)分布。LLaDA 的核心是一個(gè)參數(shù)化的掩碼預(yù)測(cè)器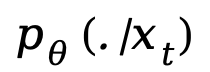 ,其訓(xùn)練目標(biāo)僅對(duì)被掩碼部分計(jì)算交叉熵?fù)p失:
,其訓(xùn)練目標(biāo)僅對(duì)被掩碼部分計(jì)算交叉熵?fù)p失:
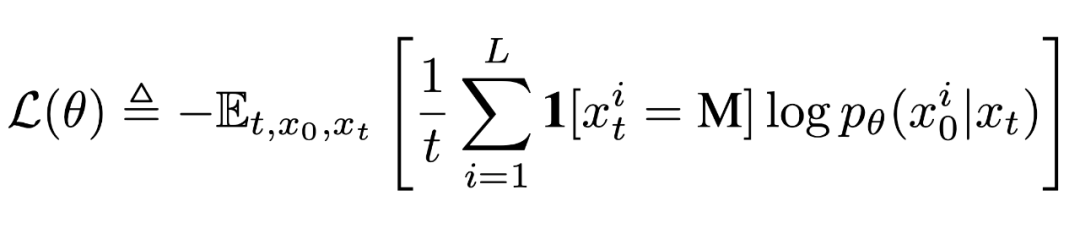
前期工作 [2] 已證明該目標(biāo)函數(shù)為負(fù)對(duì)數(shù)似然的上界,從而為生成建模提供了嚴(yán)格的理論依據(jù)。
預(yù)訓(xùn)練。LLaDA 使用 Transformer 作為掩碼預(yù)測(cè)器,并且不采用因果掩碼,從而能夠利用全局信息進(jìn)行預(yù)測(cè)。預(yù)訓(xùn)練在 2.3 萬(wàn)億 tokens 的數(shù)據(jù)上進(jìn)行,這些數(shù)據(jù)涵蓋通用文本、代碼、數(shù)學(xué)以及多語(yǔ)言內(nèi)容。對(duì)于每個(gè)訓(xùn)練序列 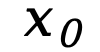 ,先隨機(jī)采樣
,先隨機(jī)采樣 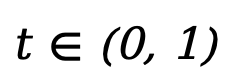 ,然后以相同概率 t 對(duì)每個(gè) token 進(jìn)行獨(dú)立掩碼得到
,然后以相同概率 t 對(duì)每個(gè) token 進(jìn)行獨(dú)立掩碼得到 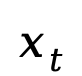 ,并通過(guò)蒙特卡羅方法估計(jì)目標(biāo)函數(shù)
,并通過(guò)蒙特卡羅方法估計(jì)目標(biāo)函數(shù)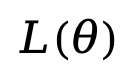 進(jìn)行優(yōu)化。為增強(qiáng)對(duì)變長(zhǎng)數(shù)據(jù)的處理能力,部分?jǐn)?shù)據(jù)采用了隨機(jī)長(zhǎng)度。LLaDA 采用 Warmup-Stable-Decay 學(xué)習(xí)率調(diào)度器和 AdamW 優(yōu)化器,設(shè)置總批量大小為 1280(每 GPU 4)。
進(jìn)行優(yōu)化。為增強(qiáng)對(duì)變長(zhǎng)數(shù)據(jù)的處理能力,部分?jǐn)?shù)據(jù)采用了隨機(jī)長(zhǎng)度。LLaDA 采用 Warmup-Stable-Decay 學(xué)習(xí)率調(diào)度器和 AdamW 優(yōu)化器,設(shè)置總批量大小為 1280(每 GPU 4)。
監(jiān)督微調(diào)(SFT)。為了提升模型的指令遵循能力,LLaDA 在監(jiān)督微調(diào)階段使用成對(duì)數(shù)據(jù) 進(jìn)行訓(xùn)練,其中
進(jìn)行訓(xùn)練,其中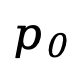 為提示,
為提示,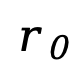 為響應(yīng)。在 SFT 中保持提示
為響應(yīng)。在 SFT 中保持提示 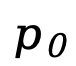 不變,對(duì)響應(yīng)
不變,對(duì)響應(yīng) 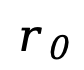 進(jìn)行獨(dú)立掩碼生成 ,然后計(jì)算如下?lián)p失:
進(jìn)行獨(dú)立掩碼生成 ,然后計(jì)算如下?lián)p失:
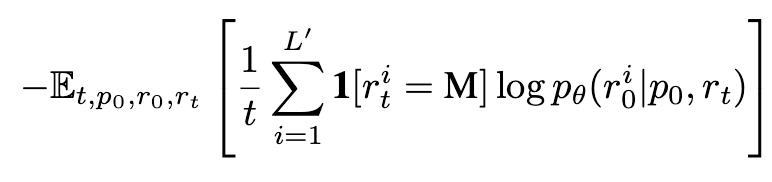
其中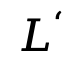 為響應(yīng)的動(dòng)態(tài)長(zhǎng)度。整個(gè)過(guò)程與預(yù)訓(xùn)練一致,只是所有被掩碼的 token 均來(lái)自響應(yīng)部分。SFT 在 450 萬(wàn)對(duì)數(shù)據(jù)上進(jìn)行,使用類似預(yù)訓(xùn)練的學(xué)習(xí)率調(diào)度和優(yōu)化器設(shè)置。
為響應(yīng)的動(dòng)態(tài)長(zhǎng)度。整個(gè)過(guò)程與預(yù)訓(xùn)練一致,只是所有被掩碼的 token 均來(lái)自響應(yīng)部分。SFT 在 450 萬(wàn)對(duì)數(shù)據(jù)上進(jìn)行,使用類似預(yù)訓(xùn)練的學(xué)習(xí)率調(diào)度和優(yōu)化器設(shè)置。
推斷。給定提示 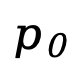 ,模型從完全掩碼的響應(yīng)開始,通過(guò)離散化的反向過(guò)程逐步恢復(fù)文本。在每一步,模型預(yù)測(cè)所有被掩碼 token 后,會(huì)按一定比例對(duì)部分預(yù)測(cè)結(jié)果進(jìn)行再掩碼,以保證反向過(guò)程與前向過(guò)程一致。對(duì)于條件似然評(píng)估,LLaDA 使用了下面這個(gè)和
,模型從完全掩碼的響應(yīng)開始,通過(guò)離散化的反向過(guò)程逐步恢復(fù)文本。在每一步,模型預(yù)測(cè)所有被掩碼 token 后,會(huì)按一定比例對(duì)部分預(yù)測(cè)結(jié)果進(jìn)行再掩碼,以保證反向過(guò)程與前向過(guò)程一致。對(duì)于條件似然評(píng)估,LLaDA 使用了下面這個(gè)和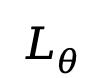 等價(jià)但是方差更小的目標(biāo)函數(shù):
等價(jià)但是方差更小的目標(biāo)函數(shù):

其中 l 是從 中均勻采樣得到,
中均勻采樣得到,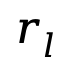 是通過(guò)從
是通過(guò)從  中不放回地均勻采樣 l 個(gè) token 進(jìn)行掩碼得到。
中不放回地均勻采樣 l 個(gè) token 進(jìn)行掩碼得到。
總結(jié)
擴(kuò)散語(yǔ)言模型 LLaDA 首次展示了通過(guò)前向掩碼加噪與反向去噪機(jī)制,同樣可以實(shí)現(xiàn)大語(yǔ)言模型的核心能力。實(shí)驗(yàn)表明,LLaDA 在可擴(kuò)展性、上下文學(xué)習(xí)和指令遵循等方面表現(xiàn)優(yōu)異,具備與傳統(tǒng)自回歸模型相媲美甚至更優(yōu)的性能,同時(shí)其雙向生成與增強(qiáng)的魯棒性有效突破了自回歸建模的固有限制,從而挑戰(zhàn)了「大語(yǔ)言模型的智能必然依賴自回歸生成」的傳統(tǒng)觀念。




























