













李飛飛、DeepSeek為何偏愛這個國產模型?
斯坦福李飛飛團隊的一篇論文,近來在AI圈子掀起了一場颶風。
他們僅用1000個樣本,在16塊H100上監督微調26分鐘,訓出的新模型s1-32B,竟取得了和OpenAI o1、DeepSeek R1等尖端推理模型相當的數學和編碼能力!
團隊也再次證明了測試時Scaling的威力。
就連AI大神Karpathy都為之驚嘆。
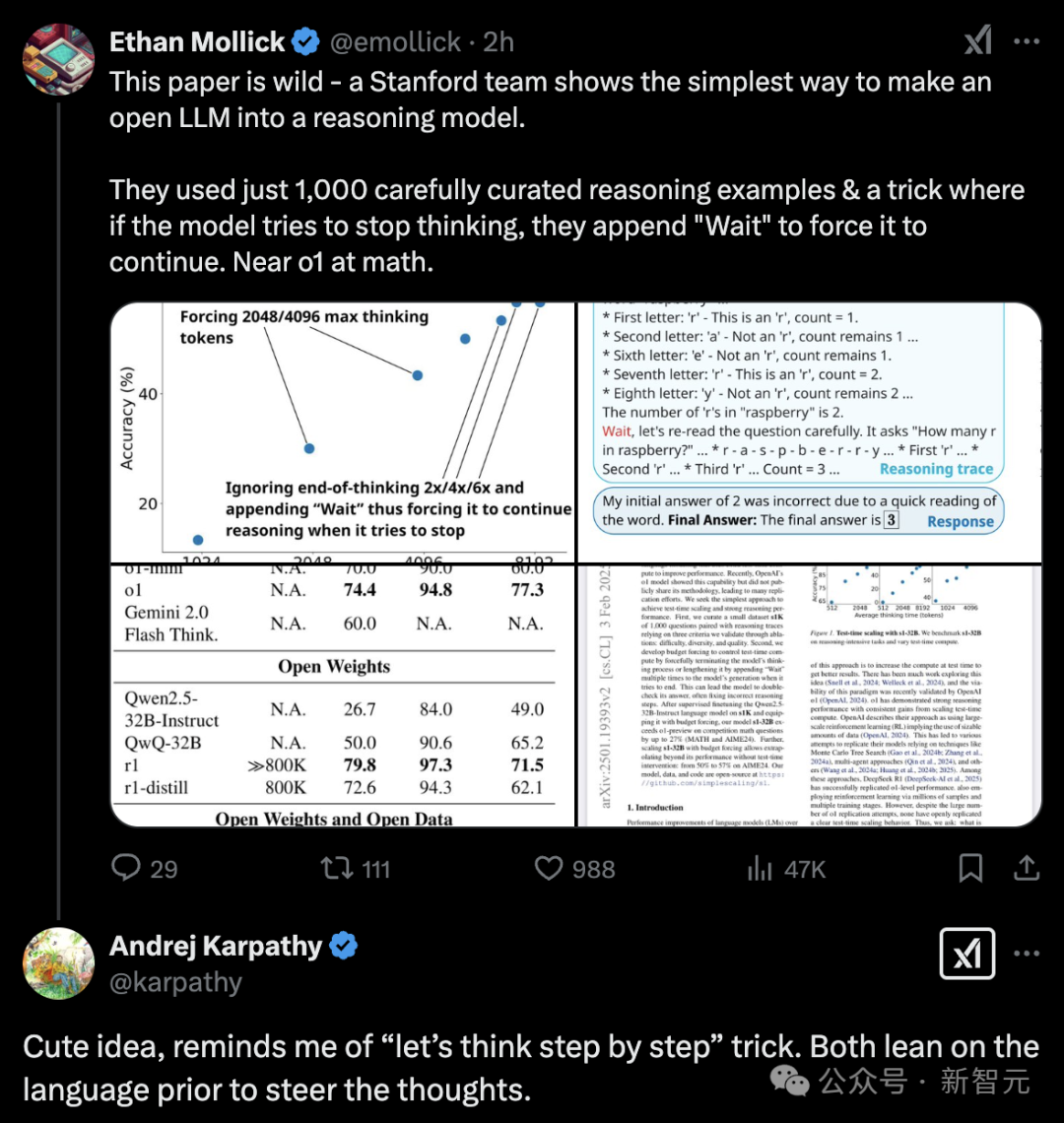
值得一提的是,研究人員是基于阿里通義千問Qwen2.5-32B-Instruct,完成了推理模型的微調。
甚至,在競賽數學問題上,新模型竟將o1-preview甩在身后,領先27%。
這一爆炸性突破,讓全世界目光都聚焦在了,這個來自阿里云的大模型——通義千問Qwen。
早在此之前,紅遍全網的DeepSeek便選擇的也是Qwen模型。
他們將DeepSeek-R1推理能力蒸餾6個模型開源給社區,其中4個都是基于Qwen打造。基于Qwen-32B蒸餾的模型,在多項能力上性能直追o1-mini。
再一次,通義千問Qwen模型又在開源社區火了。

有專家提出:也許,這是我們第一次認真嘗試研究,推理中究竟發生了什么變化。
現在,我們有充分的理由去質疑「涌現」的說法,也有了更多動力去理解,為什么Qwen-2.5-Math的基礎模型要比Llama 3.1好這么多。
的確,如今在業內,這一現象越來越成為大家公認的事實——
憑借強勁的性能,多樣化開源尺寸,以及全球最大的衍生模型群,Qwen已經取代Llama成為開源AI社區最重要的標桿基座模型。
站在巨人的肩膀上
自2023年8月以來,阿里云通義千問掀起了一場開源革命。
Qwen、Qwen1.5、Qwen2、Qwen2.5四代模型相繼開源,覆蓋了大語言模型、多模態模型、數學模型和代碼模型等數十款。
在HuggingFace的Open LLM Leaderboard、Chatbot Arena大模型盲測榜單、司南OpenCompass等多個國內外權威榜單中,Qwen性能全球領先,屢次斬獲「全球開源冠軍」。
甚至,有業內專家指出——
當前AI領域的諸多突破性進展,無論是微調、蒸餾,還是其他低成本創新技術,并非從0開始訓練,而是建立在Qwen等基礎模型的優異性能之上。
Databricks研究科學家Omar Khattab稱,「更多關于Qwen的發現。我越來越確信這些論文似乎發現了一些關于Qwen模型的特性,而不一定涉及推理能力的突破」。
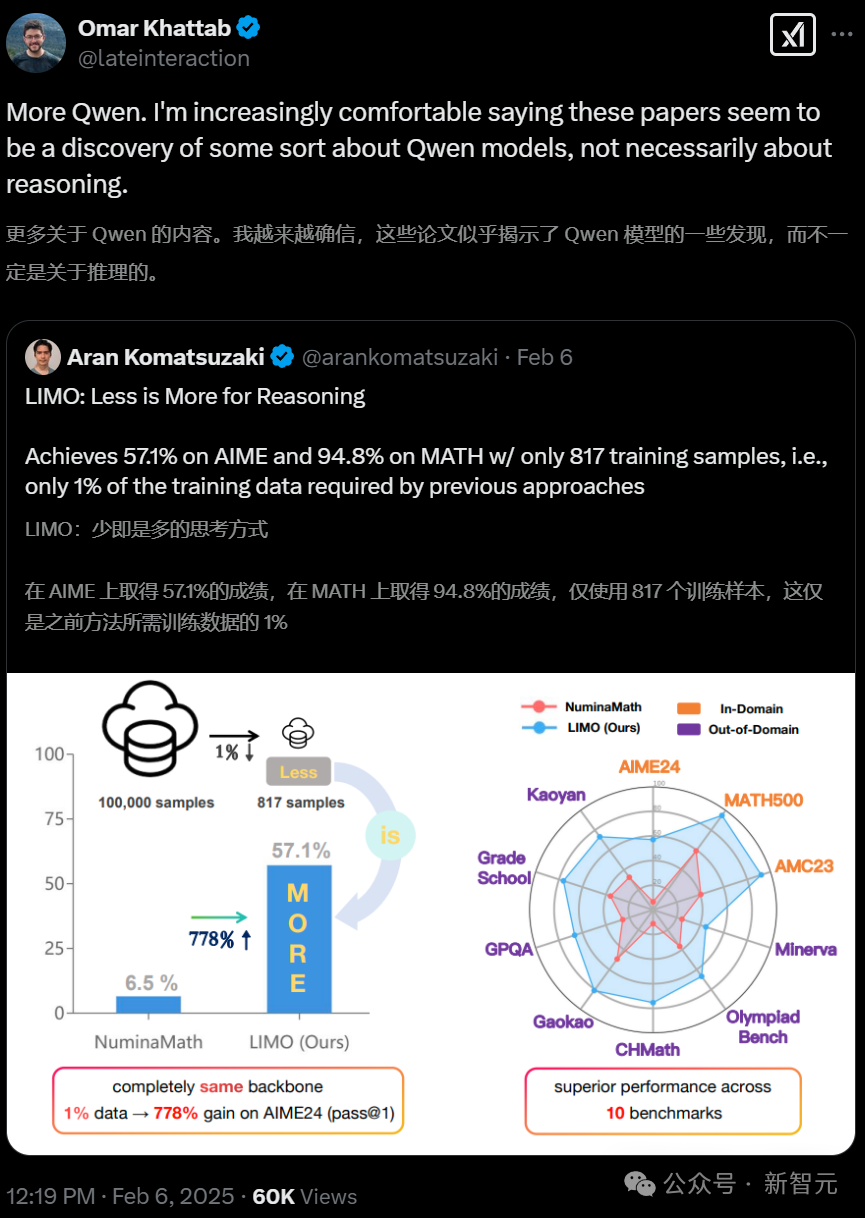
另一位來自滑鐵盧大學計算機系助理教授Wenhu Chen對此觀點表示極大地認同。
他表示,這基本和s1的發現一樣,用大約1000個樣本就能得到類似的訓練結果。
在別的模型上用同樣的數據訓練,但卻完全沒成效,這是為何?
顯然,Qwen模型本身必然有一些神奇之處。

越來越多的人不約而同地發現,「我們幾乎什么都沒做,Qwen 2.5卻幾乎什么都能做了。」
這就說明,它的基礎模型一定性能超強,在基準測試中非常領先。
因為,這已經完全不能用訓練數據質量來說明了。
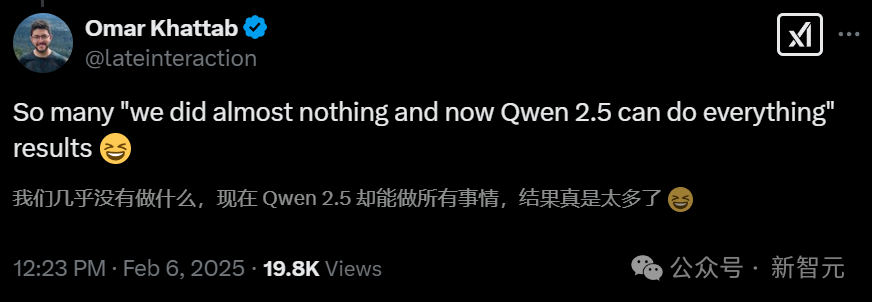

李飛飛團隊s1模型用實踐證明,在特定條件下,低成本(不到50美金)訓練確實能夠產生令人驚喜的結果。
這在很大程度上,要歸功于它所依賴的基座模型——通義千問Qwen。
如果沒有這樣強大的模型作為支撐,想要去實現同樣的效果,恐怕并非易事。
包括DeepSeek開源蒸餾后四款Qwen模型,也是如此。

這也讓Qwen成為推動前沿技術發展的又一重要案例。
全尺寸、全模態、多場景
可以說,阿里云Qwen模型是業界率先實現「全尺寸、全模態、多場景」的開源。
無論是1.5B、72B還是110B,Qwen開源的模型尺寸和版本的覆蓋面都最廣,讓開發者和企業有了更多選擇的余地。
從2024年開始,Qwen就已經在開發者中擁有越來越高的影響力。
比如,在全球最知名的開源社區HuggingFace數據統計中,2024年,僅Qwen2.5-1.5B-Instruct這款模型,就占到了全球模型下載量的26.6%,遠高于第二名Llama-3.1-8B-Instruct-GGUF的6.44%。
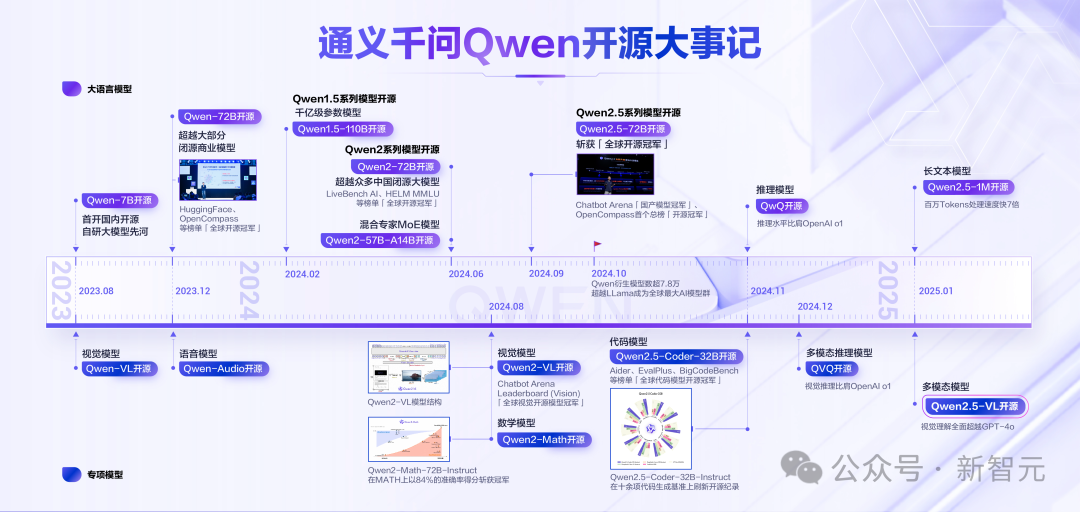
而僅僅是視覺理解Qwen-VL及Qwen2-VL兩款模型,全球的下載量就突破了3200萬次。
就在一周前,Qwen2.5-VL全新升級,又引發了新一輪的開源社區狂熱。
如今,細數海內外開源社區,Qwen的衍生模型數量已突破9萬,直接超越了Llama系列衍生模型。
DeepSeek和李飛飛的選擇,更是證明了Qwen系列的強大潛力。
在未來,它必將繼續創造新的奇跡。


























