













兩位本科生一作,首次提出「持續(xù)學(xué)習(xí)」+「少樣本」知識(shí)圖譜補(bǔ)全 | CIKM 2024
知識(shí)圖譜(Knowledge Graphs)是一種結(jié)構(gòu)化的,用于展示和管理信息,組織現(xiàn)實(shí)世界知識(shí)的形式。其通常被表達(dá)為三元組形式(<頭實(shí)體,關(guān)系,尾實(shí)體>)。KGs 為問答系統(tǒng)、推薦系統(tǒng)和搜索引擎等各種實(shí)際應(yīng)用提供了極其重要支持。
然而現(xiàn)有知識(shí)圖譜的顯著不完整性嚴(yán)重限制了其在實(shí)際應(yīng)用中的有效性。
同時(shí),在現(xiàn)實(shí)實(shí)際應(yīng)用中,知識(shí)圖譜中的關(guān)系呈現(xiàn)長(zhǎng)尾分布,即大多數(shù)關(guān)系只有少量相關(guān)的三元組。這種稀缺導(dǎo)致了模型對(duì)于長(zhǎng)尾關(guān)系的泛化能力不足,從而使得知識(shí)圖譜補(bǔ)全模型的整體效果較差 (Few-shot Learning) 。
進(jìn)一步,隨著時(shí)間的推演,越來(lái)越多的新關(guān)系被添加到關(guān)系集中,并在不同時(shí)間點(diǎn)集成到知識(shí)圖譜中。這意味著模型不僅需要學(xué)習(xí)當(dāng)前階段的知識(shí)更需要記住在之前階段學(xué)習(xí)過的知識(shí) (Continual Learning) 。
最近,上海大學(xué)的本科生李卓風(fēng)、張灝翔(第一作者以及共同第一作者)在信息檢索和數(shù)據(jù)挖掘領(lǐng)域頂級(jí)學(xué)術(shù)會(huì)議CIKM 2024上發(fā)表了一篇文章,首次提出了在持續(xù)學(xué)習(xí) (Continual Learning) 和少樣本 (Few-shot) 的場(chǎng)景下對(duì)知識(shí)圖譜進(jìn)行補(bǔ)全,提供了一套全面且有效的框架來(lái)處理這一問題。

論文標(biāo)題:Learning from Novel Knowledge: Continual Few-shot Knowledge Graph Completion
論文鏈接:https://dl.acm.org/doi/10.1145/3627673.3679734
代碼鏈接:https://github.com/cfkgc-paper/CFKGC-paper/tree/main
該研究的發(fā)表將有助于提高知識(shí)圖譜補(bǔ)全(KGC)模型在實(shí)際應(yīng)用中的泛化能力,使其能夠更好地適應(yīng)動(dòng)態(tài)環(huán)境和數(shù)據(jù)稀缺的場(chǎng)景,從而推動(dòng)相關(guān)領(lǐng)域的應(yīng)用發(fā)展。
通過提供有效的解決方案,本研究為后續(xù)研究奠定了基礎(chǔ),同時(shí)也為實(shí)際應(yīng)用提供了重要的參考。
研究背景
目前在持續(xù)學(xué)習(xí) (Continual Learning) 和少樣本 (Few-shot) 的場(chǎng)景下對(duì)知識(shí)圖譜進(jìn)行補(bǔ)全面臨兩大挑戰(zhàn):
1. 災(zāi)難性遺忘問題,即模型在不斷學(xué)習(xí)新關(guān)系時(shí),對(duì)之前學(xué)到的關(guān)系的推理性能下降。這會(huì)導(dǎo)致模型退化和對(duì)稀有關(guān)系的推斷能力大幅減弱。
2. 新關(guān)系的稀缺導(dǎo)致模型在稀有關(guān)系上的泛化能力不足。
為解決這些挑戰(zhàn),該研究提出了一個(gè)完整且有效的知識(shí)圖譜補(bǔ)全框架,以適應(yīng)不斷出現(xiàn)的少量的關(guān)系。
1. 為了解決災(zāi)難性遺忘問題,研究人員從數(shù)據(jù)和模型兩個(gè)維度入手。
在數(shù)據(jù)層面,通過特定的指標(biāo)評(píng)估每個(gè)三元組在知識(shí)圖譜中的重要性,包括拓?fù)涓兄完P(guān)系異質(zhì)感知系數(shù);利用這些重要性得分,可以識(shí)別出并存儲(chǔ)來(lái)自最重要的三元組;這些緩存的三元組可以在優(yōu)化過程中重放,以應(yīng)對(duì)新關(guān)系的出現(xiàn),確保模型回憶起最重要的知識(shí)。
在模型層面,研究人員實(shí)施了一種參數(shù)凍結(jié)的策略。在每個(gè)階段,模型會(huì)識(shí)別與當(dāng)前任務(wù)相關(guān)的一個(gè)模型子網(wǎng)絡(luò),并將其凍結(jié),從而有效減輕遺忘問題。
2. 為了解決關(guān)系的稀缺導(dǎo)致模型在稀有關(guān)系上的泛化能力不足的問題,研究人員引入了一種多視角關(guān)系增強(qiáng)技術(shù)。該方法通過自監(jiān)督學(xué)習(xí)提升模型的泛化能力。
技術(shù)方法

三元組的記憶回放
為了緩解災(zāi)難性遺忘問題,研究人員從數(shù)據(jù)和模型兩個(gè)層面提出了解決方案。在數(shù)據(jù)層面,通過特別設(shè)計(jì)的指標(biāo)來(lái)評(píng)估每個(gè)實(shí)體的重要性,并在內(nèi)存中存儲(chǔ)最重要的三元組。
這些緩存的三元組可以在新關(guān)系出現(xiàn)時(shí)進(jìn)行重播,以確保模型能夠回憶起最重要的知識(shí)。
具體來(lái)說(shuō),從兩個(gè)角度評(píng)估實(shí)體的重要程度:
1. 拓?fù)涓兄匾取T谥R(shí)圖譜中,一個(gè)實(shí)體的重要性應(yīng)當(dāng)由與其相連的其他實(shí)體的重要性共同決定。

其中du表示實(shí)體u的出邊數(shù)量,N(v)表示實(shí)體v在Gr中的鄰居集合。 是實(shí)體v的最終拓?fù)涓兄匾缘梅帧?/span>
是實(shí)體v的最終拓?fù)涓兄匾缘梅帧?/span>
2. 除了拓?fù)浣Y(jié)構(gòu)外,還考慮了實(shí)體參與關(guān)系的多樣性,即關(guān)系異質(zhì)性感知重要度:

其中|Rv|表示實(shí)體v連接的不同關(guān)系數(shù)量。
最終,可以計(jì)算三元組的重要性分?jǐn)?shù):

元學(xué)習(xí)器的調(diào)制
文中進(jìn)一步在模型層面實(shí)施了參數(shù)調(diào)制策略來(lái)保存最重要的參數(shù)。
具體來(lái)說(shuō),首先使用權(quán)重分?jǐn)?shù)s來(lái)衡量網(wǎng)絡(luò)參數(shù)的重要性:

然后,通過下面的優(yōu)化公式來(lái)更新模型參數(shù):


θ是元學(xué)習(xí)器參數(shù),Qr代表關(guān)系集, 是學(xué)習(xí)率,
是學(xué)習(xí)率, 表示之前會(huì)話中識(shí)別的子網(wǎng)絡(luò)掩碼的并集。
表示之前會(huì)話中識(shí)別的子網(wǎng)絡(luò)掩碼的并集。
通過這種參數(shù)調(diào)制機(jī)制,可以在學(xué)習(xí)新任務(wù)時(shí)保護(hù)已獲得的重要知識(shí),從而有效緩解災(zāi)難性遺忘問題。
增強(qiáng)少樣本和自監(jiān)督學(xué)習(xí)
通過引入基于自監(jiān)督的多視圖關(guān)系增強(qiáng)技術(shù)來(lái)增強(qiáng)模型的泛化能力,通過兩種擾動(dòng)方式生成關(guān)系的不同視圖。
1. 元學(xué)習(xí)器參數(shù)擾動(dòng):

2. 輸入實(shí)體嵌入擾動(dòng):

然后通過對(duì)比學(xué)習(xí)損失來(lái)優(yōu)化:

其中τ是溫度參數(shù), 一個(gè) Batch 之內(nèi)的關(guān)系集。
一個(gè) Batch 之內(nèi)的關(guān)系集。 與
與 分別代表經(jīng)過1或者2擾動(dòng)之后生成的關(guān)系。
分別代表經(jīng)過1或者2擾動(dòng)之后生成的關(guān)系。
實(shí)驗(yàn)結(jié)果
研究人員在 NELL-ONE 和 Wiki-ONE 兩個(gè)數(shù)據(jù)集上對(duì)模型進(jìn)行持續(xù)學(xué)習(xí)以及小樣本學(xué)習(xí)的全面驗(yàn)證。
持續(xù)學(xué)習(xí)能力
該框架在持續(xù)學(xué)習(xí)方面的表現(xiàn),與基線模型相比,能夠顯著減輕災(zāi)難性遺忘,且該模型不僅能有效保留先前會(huì)話的知識(shí),還在后續(xù)會(huì)話中表現(xiàn)出更好的性能。該框架相對(duì)于基線模型,在減輕災(zāi)難性遺忘方面顯示出顯著優(yōu)勢(shì)。

例如,在NELL-One數(shù)據(jù)集中,方法在后續(xù)任務(wù)(Task1至Task7)中,平均比第二佳的基線方法改進(jìn)了+13.3%,而在Wiki-One數(shù)據(jù)集中,平均改進(jìn)為+27.0%。這表明該模型不僅有效地保留了之前學(xué)習(xí)會(huì)話的知識(shí),還在隨后的學(xué)習(xí)任務(wù)中展示了更優(yōu)越的性能。

少樣本學(xué)習(xí)能力
在快速適應(yīng)新的學(xué)習(xí)進(jìn)程中的未見關(guān)系時(shí),模型能夠維持穩(wěn)定或增強(qiáng)的少樣本學(xué)習(xí)性能。
相反,基線模型由于每個(gè)新會(huì)話中元任務(wù)數(shù)量有限,表現(xiàn)出明顯的性能下降。這進(jìn)一步證明了提出的多視角關(guān)系增強(qiáng)策略在解決與元任務(wù)稀缺相關(guān)的過擬合問題中的有效性。
模型在少樣本學(xué)習(xí)方面顯示了出色的性能,特別是在快速適應(yīng)未見關(guān)系的新學(xué)習(xí)環(huán)境中。
以NELL-One數(shù)據(jù)集為例,MRR指標(biāo)相較于第一個(gè)task(11.1%),模型在最后一個(gè)任務(wù)中表現(xiàn)出11.35%的性能,期間最高達(dá)到12.55%。
在Wiki-One數(shù)據(jù)集中,從基線的38.9%提高到了最后一個(gè)任務(wù)的40.05%,相對(duì)于其他的方法——隨著更新的知識(shí)的學(xué)習(xí),小樣本性能也在下降,模型實(shí)現(xiàn)了對(duì)于更好的小樣本學(xué)習(xí)性能的保持。
結(jié)果驗(yàn)證了所提出的多視角關(guān)系增強(qiáng)策略在緩解元任務(wù)稀缺導(dǎo)致的過擬合問題上的高效性。
結(jié)果表明模型不僅可以充分記住先前階段的知識(shí)同時(shí)還可以有效學(xué)習(xí)新的知識(shí)。
消融實(shí)驗(yàn)
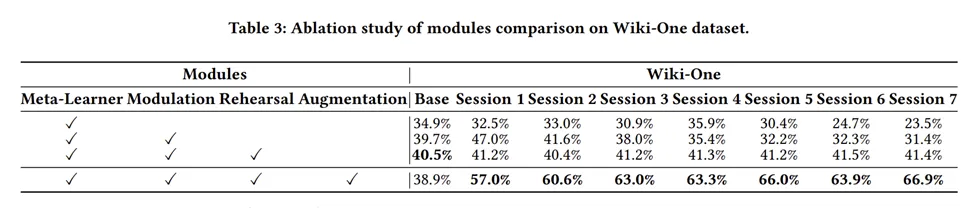
總結(jié)
本篇文章探討了在持續(xù)學(xué)習(xí)以及少量樣本的場(chǎng)景下對(duì)知識(shí)圖譜補(bǔ)全的問題,提出了一種全面且有效的框架,旨在應(yīng)對(duì)災(zāi)難性遺忘以及少樣本帶來(lái)的挑戰(zhàn)。
該方案包括三元組重演策略,模型參數(shù)調(diào)制策略,多視角關(guān)系增強(qiáng)策略。該研究的發(fā)表將有助于提高知識(shí)圖譜補(bǔ)全(KGC)模型在實(shí)際應(yīng)用中的泛化能力,使其能夠更好地適應(yīng)動(dòng)態(tài)環(huán)境和數(shù)據(jù)稀缺的場(chǎng)景,從而推動(dòng)相關(guān)領(lǐng)域的應(yīng)用發(fā)展。
通過提供有效的解決方案,本研究為后續(xù)研究奠定了基礎(chǔ),同時(shí)也為實(shí)際應(yīng)用提供了重要的參考。























