3DGS優(yōu)化神器 | 理想汽車提出MVGS:利用多視圖一致性暴力漲點!
本文經(jīng)自動駕駛之心公眾號授權(quán)轉(zhuǎn)載,轉(zhuǎn)載請聯(lián)系出處。
寫在前面&筆者的個人理解
最近在體渲染方面的工作,例如NeRF和3GS,在學(xué)習到的隱式神經(jīng)輻射場或3D高斯分布的幫助下,顯著提高了渲染質(zhì)量和效率。在演示表示的基礎(chǔ)上進行渲染,vanilla 3DGS及其變體通過優(yōu)化參數(shù)模型,在訓(xùn)練過程中每次迭代都進行單視圖監(jiān)督,從而提供實時效率,這是NeRF采用的。因此某些視圖過擬合,導(dǎo)致新視角合成和不精確的3D幾何中的外觀不令人滿意。為了解決上述問題,我們提出了一種新的3DGS優(yōu)化方法,該方法體現(xiàn)了四個關(guān)鍵的新貢獻:1)我們將傳統(tǒng)的單視圖訓(xùn)練范式轉(zhuǎn)化為多視圖訓(xùn)練策略。通過我們提出的多視圖調(diào)節(jié),3D高斯屬性得到了進一步優(yōu)化,而不會過擬合某些訓(xùn)練視圖。作為通用解決方案,我們提高了各種場景和不同高斯變體的整體精度。2)受其他視角帶來的好處的啟發(fā),我們進一步提出了一種跨內(nèi)參指導(dǎo)方法,從而針對不同分辨率進行了從粗到細的訓(xùn)練過程。3)基于我們的多視圖訓(xùn)練,進一步提出了一種交叉射線高斯split&clone策略,從一系列視圖中在射線交叉區(qū)域優(yōu)化高斯核。4) 通過進一步研究致密化策略,我們發(fā)現(xiàn)當某些視角明顯不同時,densification的效果應(yīng)該得到增強。作為一種解決方案,我們提出了一種新的多視圖增強致密化策略,其中鼓勵3D高斯模型相應(yīng)地被致密化到足夠的數(shù)量,從而提高了重建精度。我們進行了廣泛的實驗,以證明我們提出的方法能夠改進基于高斯的顯式表示方法的新視圖合成,其峰值信噪比約為1 dB,適用于各種任務(wù)。
- 項目主頁:https://xiaobiaodu.github.io/mvgs-project/

總結(jié)來說,本文的主要貢獻如下:
- 首先提出了一種多視圖調(diào)節(jié)訓(xùn)練策略,該策略可以很容易地適應(yīng)現(xiàn)有的單視圖監(jiān)督3DGS框架及其變體,這些變體針對各種任務(wù)進行了優(yōu)化,可以持續(xù)提高NVS和幾何精度。
- 受不同外參下的多視圖監(jiān)督帶來的好處的啟發(fā),提出了一種交叉內(nèi)參指導(dǎo)方法,以從粗到細的方式訓(xùn)練3D高斯人。因此3D高斯分布可以與像素局部特征保持更高的一致性。
- 由于致密化策略對3DGS至關(guān)重要,我們進一步提出了一種交叉射線致密化策略,在2D loss圖引導(dǎo)下發(fā)射射線,并對重疊的3D區(qū)域進行致密化。這些重疊區(qū)域中的致密三維高斯分布有助于多個視圖的擬合,提高了新型視圖合成的性能。
- 最后但同樣重要的是,我們提出了一種多視圖增強致密化策略,在多視圖差異顯著的情況下加強致密化。它確保了3D高斯分布可以被充分稠密,以很好地適應(yīng)急劇變化的多視圖監(jiān)督信息。
- 總之大量實驗表明,我們的方法是現(xiàn)有基于高斯的方法的通用優(yōu)化解決方案,可以將各種任務(wù)的新視圖合成性能提高約1 dB PSNR,包括靜態(tài)對象或場景重建和動態(tài)4D重建。
MVGS方法介紹
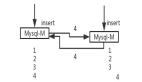
高斯散射最近被提出用于實時新穎的視圖合成和高保真3D幾何重建。高斯散射不是使用NeRF中的密度場和NeuS中的SDF等隱式表示,而是利用一組由其位置、顏色、協(xié)方差和不透明度組成的各向異性3D高斯來參數(shù)化場景。與NeRF和NeuS等先前的方法相比,這種顯式表示顯著提高了訓(xùn)練和推理效率。在渲染過程中,高斯散斑還采用了NeRF之后的基于點的體繪制技術(shù)。如圖2(a)所示,由于其點采樣策略和隱式表示,NeRF在訓(xùn)練迭代中無法接收多視圖監(jiān)督。通過沿光線r(p,E,K)混合一組3D高斯分布,計算具有相機外部函數(shù)E和內(nèi)部函數(shù)K的圖像中每個像素p的視圖相關(guān)輻射C。雖然NeRF與輻射場中采樣器指定的點近似混合,但3DGS通過沿光線r用N個參數(shù)化內(nèi)核進行光柵化來精確渲染。


多視角調(diào)節(jié)訓(xùn)練
給定T對GT圖像I及其相應(yīng)的相機外部函數(shù)E和內(nèi)部函數(shù)K,3DGS的目標是重建由多視圖立體數(shù)據(jù)描述的3D模型。在訓(xùn)練策略方面,3DGS遵循NeR的慣例,通過每次迭代的單視圖監(jiān)督來優(yōu)化參數(shù)模型。關(guān)于訓(xùn)練,3DGS通常通過每次迭代的單一信息視圖進行監(jiān)督來優(yōu)化,其中一次迭代中的監(jiān)督被隨機選擇為(Ii,Ei,Ki)。因此,原始3DGS的損失函數(shù)可以相應(yīng)地公式化為:

考慮到隱式表示(如NeRF)依賴于預(yù)訓(xùn)練的采樣器來近似最自信的混合點,每次迭代的多視圖監(jiān)督并不能確保對單視圖訓(xùn)練的改進,特別是當采樣器沒有如圖2(a)所示經(jīng)過訓(xùn)練時。另一方面,明確定義的高斯核不依賴于采樣器來分配,如圖2(b)所示,這使得我們提出的多視圖訓(xùn)練策略適用于圖2(c)所示的情況,其中G中的大多數(shù)混合核可以用多視圖加權(quán)梯度反向傳播,以克服某些視角的過擬合問題。
與原始的單視圖迭代訓(xùn)練不同,我們提出了一種多視圖調(diào)節(jié)訓(xùn)練方法,以多視圖監(jiān)督的方式優(yōu)化3D高斯分布。特別是,我們在迭代中對M對監(jiān)督圖像和相機參數(shù)進行采樣。請注意,M組匹配的圖像和相機參數(shù)被采樣并且彼此不同。因此,我們提出的梯度積分單次迭代中的多視圖調(diào)節(jié)學(xué)習可以表示為:

與原始3DGS損失的唯一區(qū)別是,我們提出的方法為優(yōu)化一組3D高斯G提供了梯度的多視圖約束。這樣優(yōu)化每個高斯核gi可能會受到多視圖信息的調(diào)節(jié),從而克服某些視圖的過擬合問題。此外,多視圖約束使3D高斯人能夠?qū)W習和推斷與視圖相關(guān)的信息,如圖4左側(cè)突出顯示的反射,因此我們的方法可以在反射場景的新穎視圖合成中表現(xiàn)良好。

跨內(nèi)參指導(dǎo)
如圖2底部所示,受圖像金字塔帶來的好處的啟發(fā),我們提出了一種從粗到細的訓(xùn)練方案,通過簡單地補充更多的光柵化平面,使用不同的相機設(shè)置,即內(nèi)在參數(shù)K。具體而言,如圖2(d)所示,通過簡單地重新配置焦距fk和K中的主點ck,可以構(gòu)建具有下采樣因子S的4層圖像金字塔。根據(jù)經(jīng)驗,設(shè)置sk為8足以容納足夠的訓(xùn)練圖像進行多視圖訓(xùn)練,因子sk等于1意味著不應(yīng)用下采樣操作。對于每一層,我們都匹配了多視圖設(shè)置。特別是,較大的下采樣因子能夠容納更多的視圖,從而提供更強的多視圖約束。在最初的三個訓(xùn)練階段,我們每個階段只運行幾千次迭代,而沒有完全訓(xùn)練模型。由于目標圖像是降采樣的,因此模型在這些早期階段無法捕捉到精細的細節(jié)。因此,我們將前三個訓(xùn)練階段視為粗訓(xùn)練。在粗略訓(xùn)練期間,合并更多的多視圖信息會對整個3D高斯模型施加更強大的約束。在這種情況下,豐富的多視圖信息為整個3DGS提供了全面的監(jiān)控,并鼓勵快速擬合粗糙的紋理和結(jié)構(gòu)。一旦粗略的訓(xùn)練結(jié)束,精細的訓(xùn)練就開始了。由于之前的粗略訓(xùn)練階段提供了3DGS的粗略架構(gòu),精細訓(xùn)練階段只需要為每個3D高斯模型細化和雕刻精細細節(jié)。特別是,粗訓(xùn)練階段提供了大量的多視圖約束。它將學(xué)習到的多視圖約束傳遞給下一次精細訓(xùn)練。該方案有效地增強了多視圖約束,進一步提高了新穎的視圖合成性能。
跨射線稠密化
由于體渲染的性質(zhì)和3DGS的顯式表示,某些區(qū)域的3D高斯分布在渲染時對不同的視圖有重大影響。例如在以不同姿態(tài)拍攝中心的相機進行渲染時,中心3D高斯分布至關(guān)重要。然而找到這些區(qū)域并非易事,尤其是在3D空間中。如圖2所示,我們提出了一種交叉射線致密化策略,從2D空間開始,然后在3D中自適應(yīng)搜索。具體來說,我們首先計算多個視圖的損失圖,然后使用大小為(h,w)的滑動窗口定位包含最大平均損失值的區(qū)域。之后,我們從這些區(qū)域的頂點投射光線,每個窗口有四條光線。然后,我們計算不同視角光線的交點。由于我們每個視角投射四條光線,交點可以形成幾個長方體。這些長方體是包含重要3D高斯分布的重疊區(qū)域,在渲染多個視圖時起著重要作用。因此,我們在這些重疊區(qū)域中加密了更多的3D高斯分布,以促進多視圖監(jiān)督的訓(xùn)練。該策略依賴于對包含對多個視圖具有高意義的3D高斯分布的重疊區(qū)域的精確搜索。首先,我們選擇損失指導(dǎo),因為它突出了每個視圖應(yīng)該改進的最低質(zhì)量區(qū)域。其次,光線投射技術(shù)使我們能夠定位包含一組對這些視圖有重大貢獻的3D高斯分布的3D區(qū)域。基于精確的位置,這些區(qū)域中的3D高斯分布可以被視為多視圖聯(lián)合優(yōu)化的關(guān)鍵。通過這種方式,我們將這些3D高斯圖像加密到一定程度,以共同提高這些視圖的重建性能。
多視圖增強稠密化


實驗結(jié)果






結(jié)論
在這項工作中,我們提出了MVGS,這是一種新穎而通用的方法,可以提高現(xiàn)有基于高斯的方法的新穎視圖合成性能。MVGS的核心在于提出的多視圖調(diào)節(jié)學(xué)習,約束了具有多視圖信息的3D高斯優(yōu)化。我們表明,我們的方法可以集成到現(xiàn)有的方法中,以實現(xiàn)最先進的渲染性能。我們進一步證明了我們提出的跨內(nèi)稟制導(dǎo)方案引入了強大的多視圖約束,以獲得更好的結(jié)果。我們還證明了所提出的多視圖增強致密化和交叉射線致密化在增強致密化以促進3D高斯優(yōu)化方面的有效性。大量實驗證明了我們方法的有效性,并表明我們的方法取得了最先進的新穎視圖合成結(jié)果。