從架構(gòu)、工藝到能效表現(xiàn),全面了解LLM硬件加速,這篇綜述就夠了
對人類語言進行大規(guī)模建模是一個復雜的過程,研究人員花了幾十年的時間才開發(fā)出來。這項技術(shù)最早可追溯于 1950 年,當時克勞德?香農(nóng)將信息理論應(yīng)用于人類語言。從那時起,翻譯和語音識別等任務(wù)取得了長足的進步。
在這個過程中,人工智能 (AI) 和機器學習 (ML) 是技術(shù)進步的關(guān)鍵。ML 作為 AI 的一個子集,其允許計算機從數(shù)據(jù)中進行學習。一般來說,ML 模型要么是有監(jiān)督的,要么是無監(jiān)督的。
在接下來要介紹的這篇論文中《 Hardware Acceleration of LLMs: A comprehensive survey and comparison 》,來自西阿提卡大學的研究者重點介紹了有監(jiān)督模型。

論文地址:https://arxiv.org/pdf/2409.03384
根據(jù)論文介紹,深度學習模型分為生成式和判別式。生成式人工智能是深度學習的一個子集,它使用神經(jīng)網(wǎng)絡(luò)來處理標記和未標記的數(shù)據(jù)。大型語言模型 (LLM) 有助于理解字符、單詞和文本。
2017 年,Transformer 徹底改變了語言建模。Transformer 是一種神經(jīng)網(wǎng)絡(luò),它使用注意力機制處理長期文本依賴關(guān)系。谷歌于 2017 年創(chuàng)建了第一個用于文本翻譯的 Transformer 模型。Transformer 此后不斷發(fā)展,改進了注意力機制和架構(gòu)。發(fā)展到今天,OpenAI 發(fā)布的 ChatGPT 是一個著名的 LLM,它可以預測文本并能回答問題、總結(jié)文本等。
本文對使用硬件加速器來加速 Transformer 網(wǎng)絡(luò)所做的一些研究工作進行了全面的調(diào)查。該調(diào)查介紹了已提出的框架,然后對每個框架的技術(shù)、處理平臺(FPGA、ASIC、內(nèi)存、GPU)、加速、能源效率、性能(GOP)等進行了定性和定量比較。
FPGA 加速器
在這一部分中,作者以 A-T 編號的方式列舉了有關(guān) FPGA 的研究,可謂調(diào)查的非常詳細。每項研究都用簡短的幾句話概括,閱讀起來簡單又清晰。舉例來說:
FTRANS 。2020 年,Li 等人提出了一種硬件加速框架 FTRANS,旨在加速基于 Transformer 的大規(guī)模語言表示。FTRANS 顯著提高了速度和能效,超越了 CPU 和 GPU 實現(xiàn),在一系列比較后顯示 FTRANS 比其他方案快 81 倍,能效高 9 倍,特別是與使用 VCU118 (16nm) 的 GPU 處理器 RTX5000 相比。該加速器的性能速率為 170 GOP,能效率為 6.8 GOP/W。
多頭注意力。2020 年,Lu 等人提出了一種基于 FPGA 的架構(gòu),用于加速 Transformer 網(wǎng)絡(luò)中計算最密集的部分。在他們的工作中,他們?yōu)閮蓚€關(guān)鍵組件提出了一種新型硬件加速器,即多頭注意力 (MHA) ResBlock 和位置前饋網(wǎng)絡(luò) (FFN) ResBlock,它們是 Transformer 中最復雜的兩個層。所提出的框架是在 Xilinx FPGA 上實現(xiàn)的。根據(jù)性能評估,與 V100 GPU 相比,所提出的設(shè)計實現(xiàn)了 14.6 倍的加速。
FPGA NPE。2021 年,Khan 等人提出了一種用于語言模型的 FPGA 加速器,稱為 NPE。NPE 的能源效率比 CPU(i7-8700k)高約 4 倍,比 GPU(RTX 5000)高約 6 倍。
除此以外,文中還介紹了 ViA 、 FPGA DFX 、 FPGA OPU 等研究,這里就不再詳細介紹了。
基于 CPU 和 GPU 的加速器
TurboTransformer。2021 年,Jiarui Fang 和 Yang Yu 推出了 TurboTransformers 加速器,這是一種在 GPU 上專為 Transformer 模型打造的技術(shù)。TurboTransformers 在可變長度輸入的延遲和性能方面優(yōu)于 PyTorch 和 ONNXRuntime,速度提高了 2.8 倍。
Jaewan Choi。2022 年,研究員 Jaewan Choi 發(fā)表了題為「Accelerating Transformer Networks through Rewiring of Softmax Layers」的研究,文中提出了一種加速 Transformer 網(wǎng)絡(luò)中 Softmax 層的方法。該研究引入了一種重新布線技術(shù)來加速 Transformer 網(wǎng)絡(luò)中的 Softmax 層,隨著 Transformer 模型處理更長的序列以提高準確率,這項技術(shù)變得越來越重要。所提出的技術(shù)將 Softmax 層劃分為多個子層,更改數(shù)據(jù)訪問模式,然后將分解的 Softmax 子層與后續(xù)和前面的過程合并。該方法分別將 BERT、GPT-Neo、BigBird 和 Longformer 在當前 GPU 上的推理速度加快了 1.25 倍、1.12 倍、1.57 倍和 1.65 倍,顯著減少了片外內(nèi)存流量。
SoftMax。2022 年,Choi 等人提出了一種通過重組 Softmax 層加速 Transformer 網(wǎng)絡(luò)的新框架。Softmax 層將注意力矩陣的元素歸一化為 0 到 1 之間的值。此操作沿注意力矩陣的行向量進行。根據(jù)分析,縮放點積注意力 (SDA) 塊中的 softmax 層分別使用了 BERT、GPT-Neo、BigBird 和 Longformer 總執(zhí)行時間的 36%、18%、40% 和 42%。Softmax 重組通過顯著減少片外內(nèi)存流量,在 A100 GPU 上對 BERT、GPT-Neo、BigBird 和 Longformer 進行推理時實現(xiàn)了高達 1.25 倍、1.12 倍、1.57 倍和 1.65 倍的加速。
此外,論文還介紹了 LightSeq2 、 LLMA 、 vLLMs 等研究。
ASIC 加速器
A3。2020 年,Hma 等人提出了一項關(guān)于 Transformer 網(wǎng)絡(luò)加速的早期研究,稱為 A3 。不過,研究人員所提出的方案尚未在 FPGA 上實現(xiàn)。基于性能評估,與 Intel Gold 6128 CPU 實現(xiàn)相比,所提出的方案可實現(xiàn)高達 7 倍的加速,與 CPU 實現(xiàn)相比,能效可提高 11 倍。
ELSA。2021 年,Ham 等人提出了一種用于加速 Transformer 網(wǎng)絡(luò)的硬件 - 軟件協(xié)同設(shè)計方法,稱為 Elsa 。ELSA 大大減少了自注意力操作中的計算浪費。
SpAtten。2021 年,Want 等人提出了一種用于大型語言模型加速的框架 Spatten。SpAtten 采用新穎的 NLP 加速方案,以減少計算和內(nèi)存訪問。SpAtten 分別比 GPU(TITAN Xp)和 Xeon CPU 實現(xiàn)了 162 倍和 347 倍的加速。在能源效率方面,與 GPU 和 CPU 相比,SpAtten 實現(xiàn)了 1193 倍和 4059 倍的節(jié)能。
在這部分,作者還列舉了加速 transformer 網(wǎng)絡(luò)的新方法 Sanger、用于提高自然語言處理中 transformer 模型效率的 AccelTran 等多項研究。
內(nèi)存硬件加速器
ATT。2020 年,Guo 等人提出了一種基于注意力的加速器加速方法,稱為 ATT,該方法基于電阻性 RAM。根據(jù)性能評估,ATT 與 NVIDIA GTX 1080 Ti GPU 相比,可以實現(xiàn) 202 倍的加速。
ReTransformer。2020 年,Yang 等人提出了一種用于加速 Transformer 的內(nèi)存框架,稱為 ReTransformer。ReTransformer 是一種基于 ReRAM 的內(nèi)存架構(gòu),用于加速 Transformer,它不僅使用基于 ReRAM 的內(nèi)存架構(gòu)加速 Transformer 的縮放點積注意力,而且還通過使用提出的矩陣分解技術(shù)避免寫入中間結(jié)果來消除一些數(shù)據(jù)依賴性。性能評估表明,與 GPU 相比,ReTransformer 可以實現(xiàn)高達 23.21 倍的加速,而相應(yīng)的整體功率降低了 1086 倍。
iMCAT。2021 年,Laguna 等人提出了一種用于加速長句 Transformer 網(wǎng)絡(luò)的新型內(nèi)存架構(gòu),稱為 iMCAT。該框架結(jié)合使用 XBar 和 CAM 來加速 Transformer 網(wǎng)絡(luò)。性能評估表明,對于長度為 4098 的序列,這種方法實現(xiàn)了 200 倍的加速和 41 倍的性能改進。
除此以外,該章節(jié)還介紹了 iMCAT 、 TransPIM 、 iMTransformer 等研究。
定量比較
下表 I 列出了目前所有的硬件加速器以及各自的主要特性,包括加速器名稱、加速器類型(FPGA/ASIC/In-memory)、性能和能效。
在某些情況下,當提出的架構(gòu)與 CPU、GPU 進行比較時,以往的工作也會提及加速這一指標。不過,由于每種架構(gòu)的基線比較不同,因而本文只展示了它們的絕對性能和能效,而沒有涉及加速。

性能定量比較
下圖 1 展示了不同工藝技術(shù)下,每種加速器的性能;圖 2 展示了更加清楚的對數(shù)尺度性能。
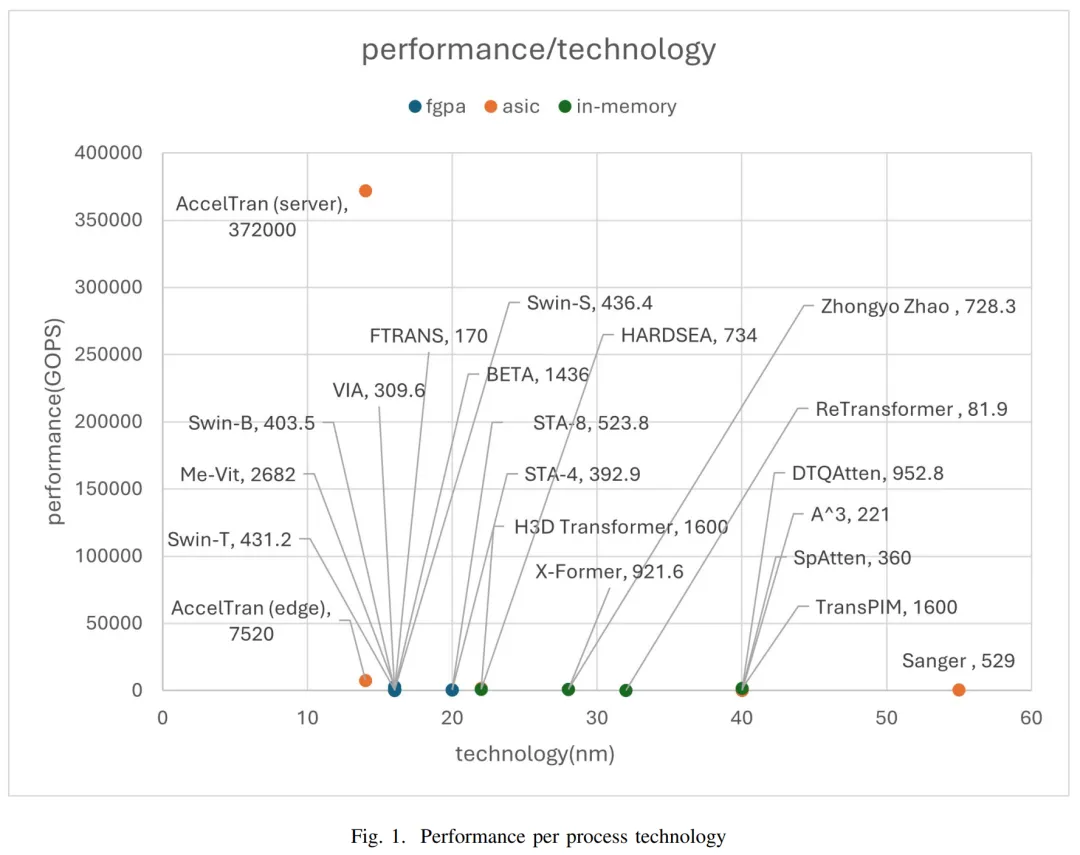

我們可以看到,采用 14nm 工藝的 AccelTran(服務(wù)器)實現(xiàn)最高性能,達到了 372000 GOPs,而 ReTransformer 模型的性能最低。此外,ViA、Me-ViT 和 Ftrans 等采用相同工藝技術(shù)的模型并沒有實現(xiàn)相似的性能。
不過,對于沒有采用相同工藝技術(shù)的加速器,則很難進行公平比較。畢竟,工藝技術(shù)會對硬件加速器性能產(chǎn)生顯著的影響。
能效 vs 工藝技術(shù)
下圖 3 展示了大多數(shù)硬件加速器的能效(GOPs/W)水平,圖 4 展示了對數(shù)尺度層面的能效。由于很多架構(gòu)沒有測量能效,因而本文只列出了提供了能效的加速器。當然,很多加速器采用了不同的工藝技術(shù),因此很難進行公平比較。
結(jié)果顯示,以內(nèi)存為主(In-Memory 加速器)的模型具有更好的能效表現(xiàn)。原因在于數(shù)據(jù)傳輸減少了,并且這種特定的架構(gòu)允許數(shù)據(jù)在內(nèi)存中直接處理,而不需要從內(nèi)存?zhèn)鬏數(shù)?CPU。


16nm 工藝下的加速比較
下表 II 展示了 16nm 工藝下,不同硬件加速器的外推性能。

下圖 5 展示了當在相同的 16nm 工藝技術(shù)下外推性能時,不同硬件加速器的絕對性能,其中 AccelTran 的性能水平最高。

實驗外推
本文針對 FPGA 架構(gòu)進行了實驗外推,并測試了 20nm、28nm、40nm、 55nm、65nm 和 180nm 工藝下技術(shù)不同的矩陣乘法代碼,以驗證 16nm 工藝的理論轉(zhuǎn)換效果。研究者表示,F(xiàn)PGA 技術(shù)上的矩陣乘法結(jié)果有助于外推不同硬件加速器在相同工藝技術(shù)上的結(jié)果。
下表 III 展示了不同 FPGA 設(shè)備、工藝技術(shù)以及矩陣乘法 IP 核的結(jié)果。

下圖 6 展示了每種 FPGA 設(shè)備和矩陣乘法工藝技術(shù)的最大時鐘頻率。由于 FPGA 的性能依賴于最大時鐘頻率,因此外推性能使得不同工藝技術(shù)下架構(gòu)之間能夠?qū)崿F(xiàn)公平比較。

更多實驗細節(jié)請參閱原論文。